 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANTRA: Synthesizing SMT-Validated Compliance Benchmarks for Tool-Using LLM Agents
May 07, 2026Tool-using large language model (LLM) agents are increasingly deployed in settings where their reliable behavior is governed by strict procedural manuals. Ensuring that such agents comply with the rules from these manuals is challenging, as they are typically written for humans in natural language while agent behavior manifests as an execution trace of tool calls. Existing evaluations of LLM agents rely on manually constructed benchmarks or LLM-based judges, which either do not scale or lack reliability for complex, long-horizon manuals. To overcome these limitations, we present MANTRA, a framework for automatically synthesizing machine-checkable compliance benchmarks from natural-language manuals and tool schemas. MANTRA independently generates (i) a symbolic world model capturing procedural dependencies, and (ii) a set of trace-level compliance checks for a given task, and validates their consistency using SMT solving. A structured repair loop resolves inconsistencies, requiring human intervention only as a fallback. %This yields benchmarks that are formally validated. Importantly, MANTRA supports arbitrary domains and long procedural manuals, and provides a tunable notion of task complexity which is utilized to automatically derive challenging tasks accompanying compliance checks. Using MANTRA, we build a new benchmark suite with 285 tasks across 6 domains scaling to 50+ page manuals with minimal human effort. Empirically, we show that the compliance checks are richer with stronger constraint enforcement compared to existing benchmarks. Additionally, the granularity of the checks can be used for debugging the agents' failure modes. These results demonstrate that combining automated benchmark generation with formally grounded validation methods enables scalable and reliable benchmarking of tool-using agents.
About Time: Model-free Reinforcement Learning with Timed Reward Machines
Dec 19, 2025



Reward specification plays a central role in reinforcement learning (RL), guiding the agent's behavior. To express non-Markovian rewards, formalisms such as reward machines have been introduced to capture dependencies on histories. However, traditional reward machines lack the ability to model precise timing constraints, limiting their use in time-sensitive applications. In this paper, we propose timed reward machines (TRMs), which are an extension of reward machines that incorporate timing constraints into the reward structure. TRMs enable more expressive specifications with tunable reward logic, for example, imposing costs for delays and granting rewards for timely actions. We study model-free RL frameworks (i.e., tabular Q-learning) for learning optimal policies with TRMs under digital and real-time semantics. Our algorithms integrate the TRM into learning via abstractions of timed automata, and employ counterfactual-imagining heuristics that exploit the structure of the TRM to improve the search. Experimentally, we demonstrate that our algorithm learns policies that achieve high rewards while satisfying the timing constraints specified by the TRM on popular RL benchmarks. Moreover, we conduct comparative studies of performance under different TRM semantics, along with ablations that highlight the benefits of counterfactual-imagining.
Maximal Adaptation, Minimal Guidance: Permissive Reactive Robot Task Planning with Humans in the Loop
Oct 14, 2025We present a novel framework for human-robot \emph{logical} interaction that enables robots to reliably satisfy (infinite horizon) temporal logic tasks while effectively collaborating with humans who pursue independent and unknown tasks. The framework combines two key capabilities: (i) \emph{maximal adaptation} enables the robot to adjust its strategy \emph{online} to exploit human behavior for cooperation whenever possible, and (ii) \emph{minimal tunable feedback} enables the robot to request cooperation by the human online only when necessary to guarantee progress. This balance minimizes human-robot interference, preserves human autonomy, and ensures persistent robot task satisfaction even under conflicting human goals. We validate the approach in a real-world block-manipulation task with a Franka Emika Panda robotic arm and in the Overcooked-AI benchmark, demonstrating that our method produces rich, \emph{emergent} cooperative behaviors beyond the reach of existing approaches, while maintaining strong formal guarantees.
Synthesizing Efficiently Monitorable Formulas in Metric Temporal Logic
Oct 26, 2023In runtime verification, manually formalizing a specification for monitoring system executions is a tedious and error-prone process. To address this issue, we consider the problem of automatically synthesizing formal specifications from system executions. To demonstrate our approach, we consider the popular specification language Metric Temporal Logic (MTL), which is particularly tailored towards specifying temporal properties for cyber-physical systems (CPS). Most of the classical approaches for synthesizing temporal logic formulas aim at minimizing the size of the formula. However, for efficiency in monitoring, along with the size, the amount of "lookahead" required for the specification becomes relevant, especially for safety-critical applications. We formalize this notion and devise a learning algorithm that synthesizes concise formulas having bounded lookahead. To do so, our algorithm reduces the synthesis task to a series of satisfiability problems in Linear Real Arithmetic (LRA) and generates MTL formulas from their satisfying assignments. The reduction uses a novel encoding of a popular MTL monitoring procedure using LRA. Finally, we implement our algorithm in a tool called TEAL and demonstrate its ability to synthesize efficiently monitorable MTL formulas in a CPS application.
Scalable Anytime Algorithms for Learning Formulas in Linear Temporal Logic
Oct 27, 2021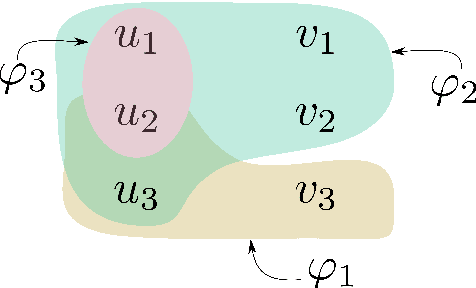
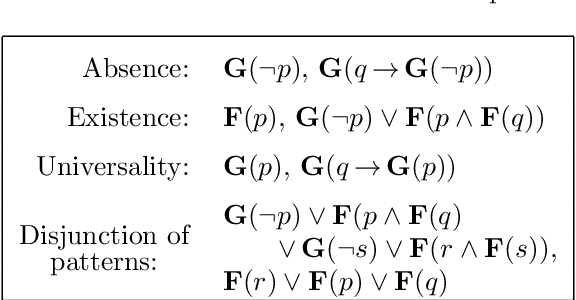
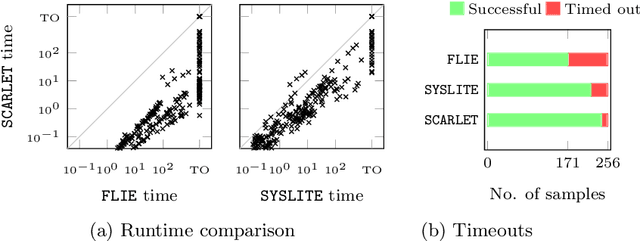
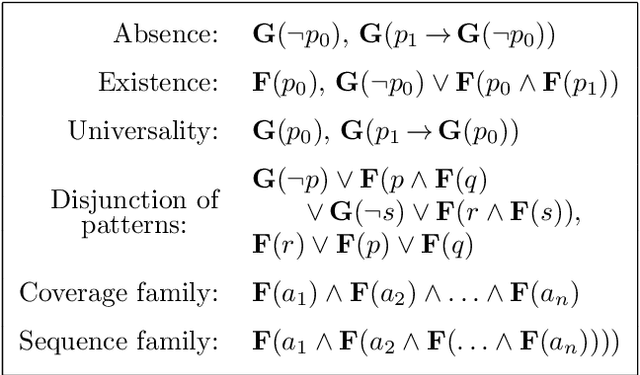
Linear temporal logic (LTL) is a specification language for finite sequences (called traces) widely used in program verification, motion planning in robotics, process mining, and many other areas. We consider the problem of learning LTL formulas for classifying traces; despite a growing interest of the research community, existing solutions suffer from two limitations: they do not scale beyond small formulas, and they may exhaust computational resources without returning any result. We introduce a new algorithm addressing both issues: our algorithm is able to construct formulas an order of magnitude larger than previous methods, and it is anytime, meaning that it in most cases successfully outputs a formula, albeit possibly not of minimal size. We evaluate the performances of our algorithm using an open source implementation against publicly available benchmarks.