 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Bank Loan Default with Extreme Gradient Boosting
Jan 18, 2020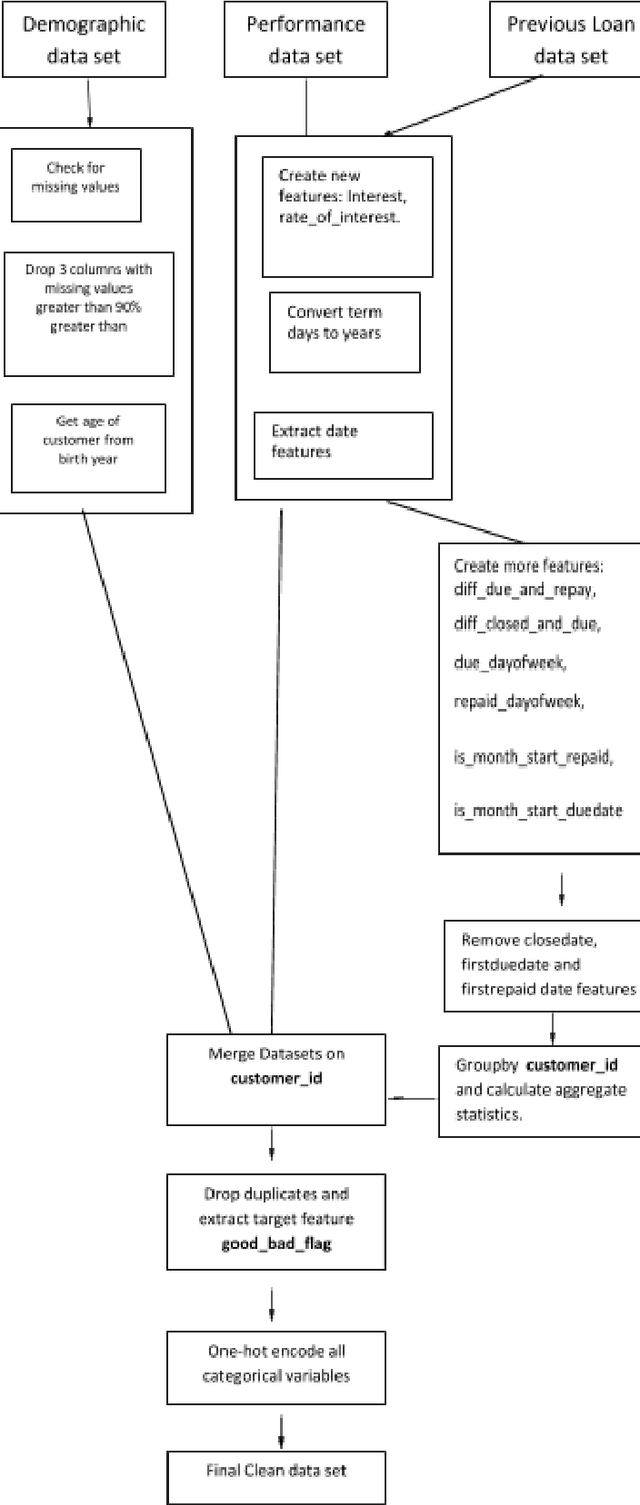



Loan default prediction is one of the most important and critical problems faced by banks and other financial institutions as it has a huge effect on profit. Although many traditional methods exist for mining information about a loan application, most of these methods seem to be under-performing as there have been reported increases in the number of bad loans. In this paper, we use an Extreme Gradient Boosting algorithm called XGBoost for loan default prediction. The prediction is based on a loan data from a leading bank taking into consideration data sets from both the loan application and the demographic of the applicant. We also present important evaluation metrics such as Accuracy, Recall, precision, F1-Score and ROC area of the analysis. This paper provides an effective basis for loan credit approval in order to identify risky customers from a large number of loan applications using predictive modeling.
DataSist: A Python-based library for easy data analysis, visualization and modeling
Nov 09, 2019
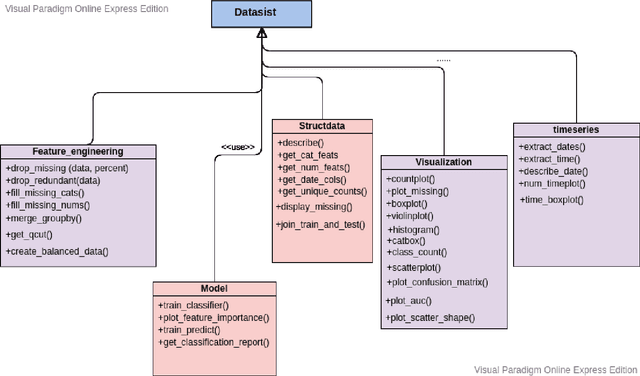
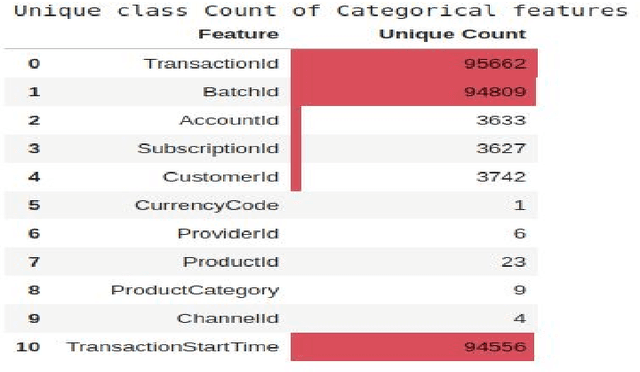
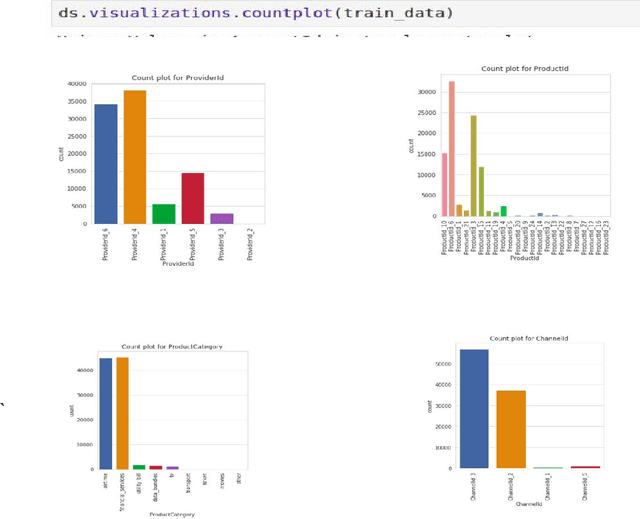
A large amount of data is produced every second from modern information systems such as mobile devices, the world wide web, Internet of Things, social media, etc. Analysis and mining of this massive data requires a lot of advanced tools and techniques. Therefore, big data analytics and mining is currently an active and trending area of research because of the enormous benefits businesses and organizations derive from it. Numerous tools like Pandas, Numpy, STATA, SPSS, have been created to help analyze and mine these huge outburst of data and some have become so popular and widely used in the field. This paper presents a new python-based library, DataSist, which offers high level, intuitive and easy to use functions, and methods that helps data scientists/analyst to quickly analyze, mine and visualize big data sets. The objectives of this project were to (i) design a python library to aid data analysis process by abstracting low level syntax (ii) increase productivity of data scientist by making them focus on what to do rather than how to do it. This project shows that data analysis can be automated and much faster when we abstract certain functions, and will serve as an important tool in the workflow of data scientists.