 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLorentz Group Equivariant Neural Network for Particle Physics
Jun 08, 2020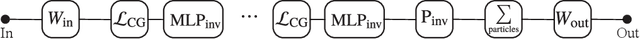
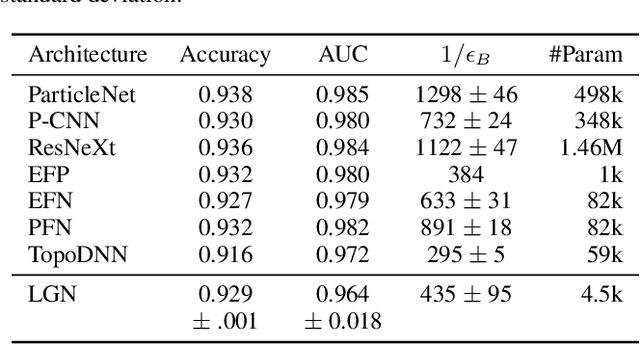
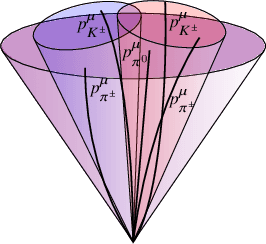
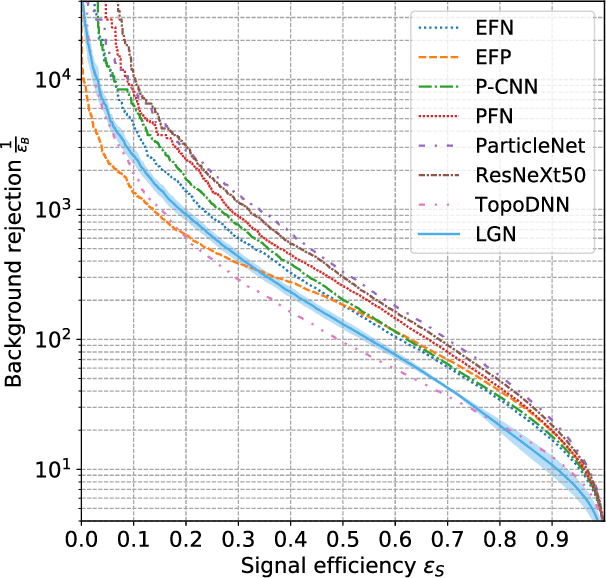
We present a neural network architecture that is fully equivariant with respect to transformations under the Lorentz group, a fundamental symmetry of space and time in physics. The architecture is based on the theory of the finite-dimensional representations of the Lorentz group and the equivariant nonlinearity involves the tensor product. For classification tasks in particle physics, we demonstrate that such an equivariant architecture leads to drastically simpler models that have relatively few learnable parameters and are much more physically interpretable than leading approaches that use CNNs and point cloud approaches. The competitive performance of the network is demonstrated on a public classification dataset [27] for tagging top quark decays given energy-momenta of jet constituents produced in proton-proton collisions.
The general theory of permutation equivarant neural networks and higher order graph variational encoders
Apr 08, 2020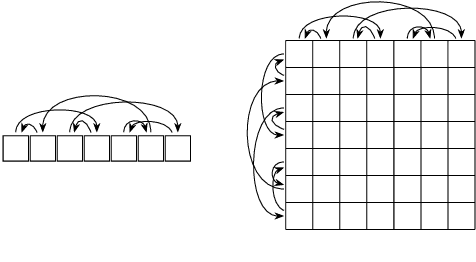
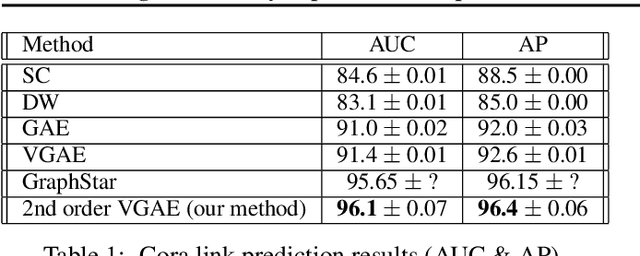
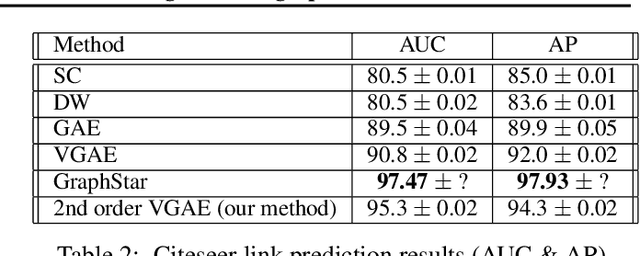
Previous work on symmetric group equivariant neural networks generally only considered the case where the group acts by permuting the elements of a single vector. In this paper we derive formulae for general permutation equivariant layers, including the case where the layer acts on matrices by permuting their rows and columns simultaneously. This case arises naturally in graph learning and relation learning applications. As a specific case of higher order permutation equivariant networks, we present a second order graph variational encoder, and show that the latent distribution of equivariant generative models must be exchangeable. We demonstrate the efficacy of this architecture on the tasks of link prediction in citation graphs and molecular graph generation.
Asymmetric Multiresolution Matrix Factorization
Oct 10, 2019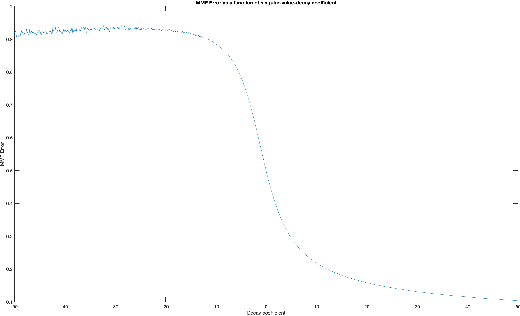
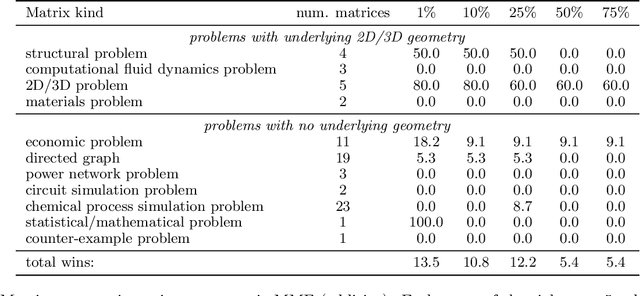
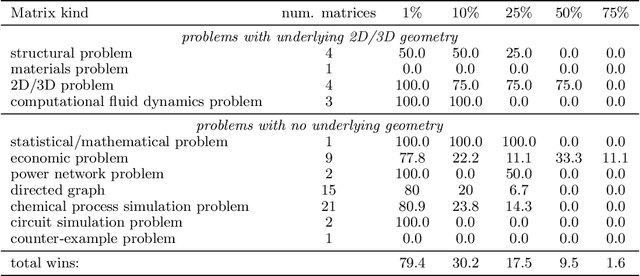
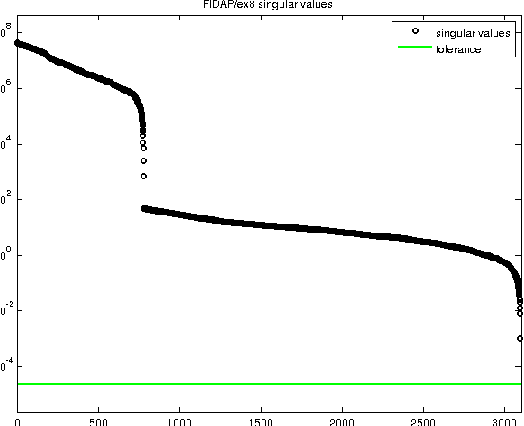
Multiresolution Matrix Factorization (MMF) was recently introduced as an alternative to the dominant low-rank paradigm in order to capture structure in matrices at multiple different scales. Using ideas from multiresolution analysis (MRA), MMF teased out hierarchical structure in symmetric matrices by constructing a sequence of wavelet bases. While effective for such matrices, there is plenty of data that is more naturally represented as nonsymmetric matrices (e.g. directed graphs), but nevertheless has similar hierarchical structure. In this paper, we explore techniques for extending MMF to any square matrix. We validate our approach on numerous matrix compression tasks, demonstrating its efficacy compared to low-rank methods. Moreover, we also show that a combined low-rank and MMF approach, which amounts to removing a small global-scale component of the matrix and then extracting hierarchical structure from the residual, is even more effective than each of the two complementary methods for matrix compression.
Deep Learning for Automated Classification and Characterization of Amorphous Materials
Sep 10, 2019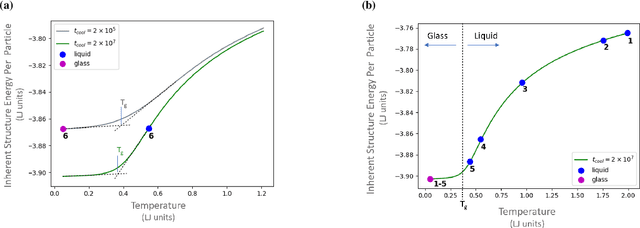
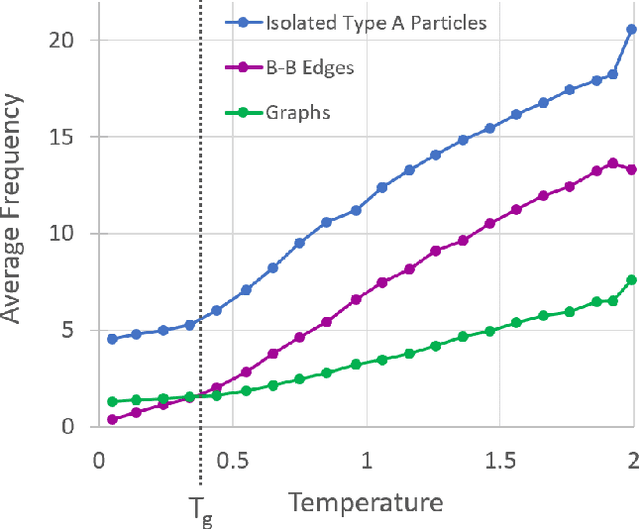
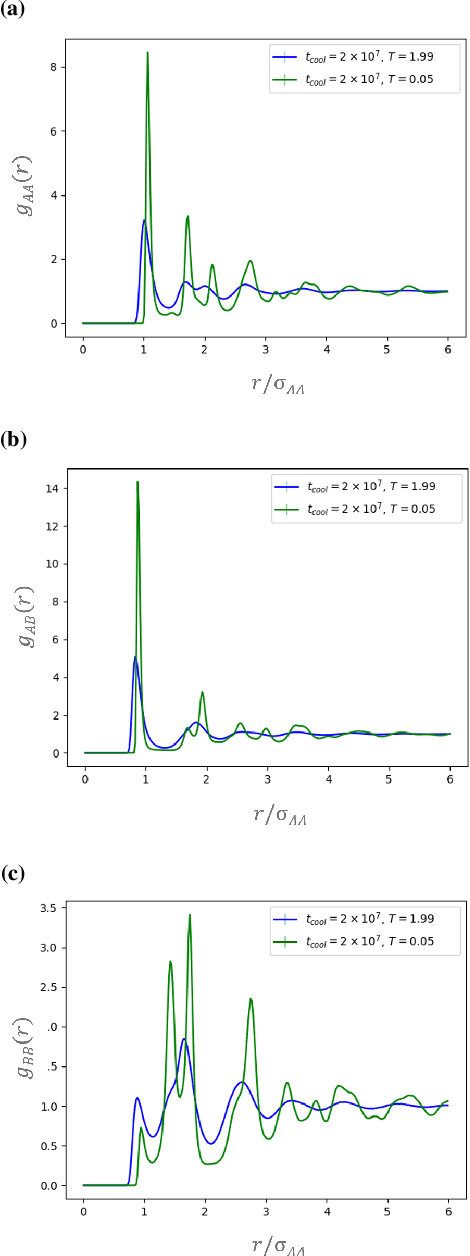
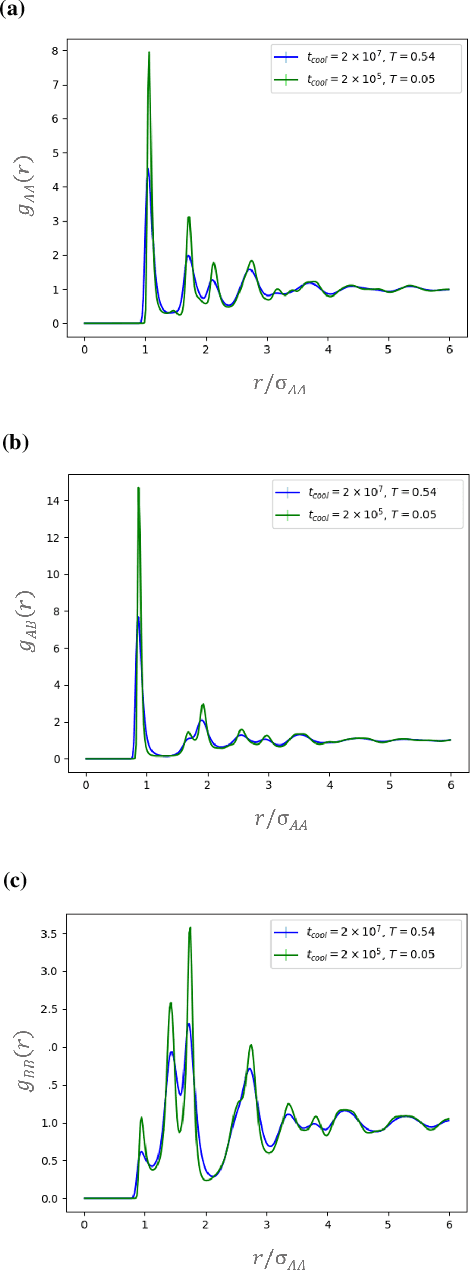
It is difficult to quantify structure-property relationships and to identify structural features of complex materials. The characterization of amorphous materials is especially challenging because their lack of long-range order makes it difficult to define structural metrics. In this work, we apply deep learning algorithms to accurately classify amorphous materials and characterize their structural features. Specifically, we show that convolutional neural networks and message passing neural networks can classify two-dimensional liquids and liquid-cooled glasses from molecular dynamics simulations with greater than 0.98 AUC, with no a priori assumptions about local particle relationships, even when the liquids and glasses are prepared at the same inherent structure energy. Furthermore, we demonstrate that message passing neural networks surpass convolutional neural networks in this context in both accuracy and interpretability. We extract a clear interpretation of how message passing neural networks evaluate liquid and glass structures by using a self-attention mechanism. Using this interpretation, we derive three novel structural metrics that accurately characterize glass formation. The methods presented here provide us with a procedure to identify important structural features in materials that could be missed by standard techniques and give us a unique insight into how these neural networks process data.
Cormorant: Covariant Molecular Neural Networks
Jun 06, 2019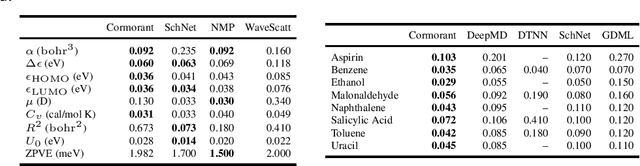
We propose Cormorant, a rotationally covariant neural network architecture for learning the behavior and properties of complex many-body physical systems. We apply these networks to molecular systems with two goals: learning atomic potential energy surfaces for use in Molecular Dynamics simulations, and learning ground state properties of molecules calculated by Density Functional Theory. Some of the key features of our network are that (a) each neuron explicitly corresponds to a subset of atoms; (b) the activation of each neuron is covariant to rotations, ensuring that overall the network is fully rotationally invariant. Furthermore, the non-linearity in our network is based upon tensor products and the Clebsch-Gordan decomposition, allowing the network to operate entirely in Fourier space. Cormorant significantly outperforms competing algorithms in learning molecular Potential Energy Surfaces from conformational geometries in the MD-17 dataset, and is competitive with other methods at learning geometric, energetic, electronic, and thermodynamic properties of molecules on the GDB-9 dataset.
Clebsch-Gordan Nets: a Fully Fourier Space Spherical Convolutional Neural Network
Jun 24, 2018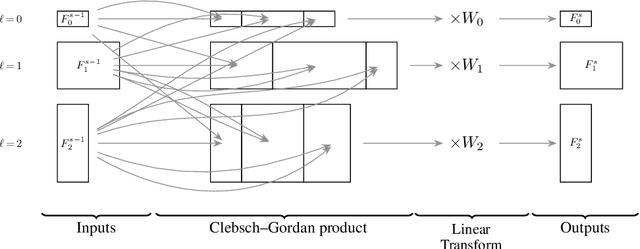

Recent work by Cohen \emph{et al.} has achieved state-of-the-art results for learning spherical images in a rotation invariant way by using ideas from group representation theory and noncommutative harmonic analysis. In this paper we propose a generalization of this work that generally exhibits improved performace, but from an implementation point of view is actually simpler. An unusual feature of the proposed architecture is that it uses the Clebsch--Gordan transform as its only source of nonlinearity, thus avoiding repeated forward and backward Fourier transforms. The underlying ideas of the paper generalize to constructing neural networks that are invariant to the action of other compact groups.
On the Generalization of Equivariance and Convolution in Neural Networks to the Action of Compact Groups
Jun 10, 2018Convolutional neural networks have been extremely successful in the image recognition domain because they ensure equivariance to translations. There have been many recent attempts to generalize this framework to other domains, including graphs and data lying on manifolds. In this paper we give a rigorous, theoretical treatment of convolution and equivariance in neural networks with respect to not just translations, but the action of any compact group. Our main result is to prove that (given some natural constraints) convolutional structure is not just a sufficient, but also a necessary condition for equivariance to the action of a compact group. Our exposition makes use of concepts from representation theory and noncommutative harmonic analysis and derives new generalized convolution formulae.
N-body Networks: a Covariant Hierarchical Neural Network Architecture for Learning Atomic Potentials
Mar 05, 2018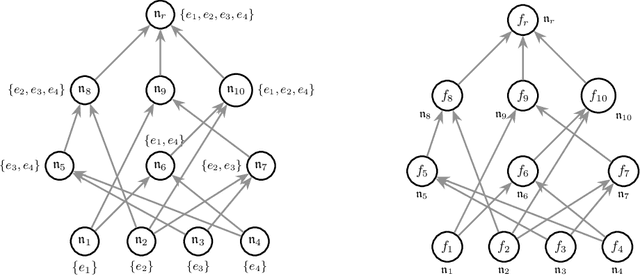
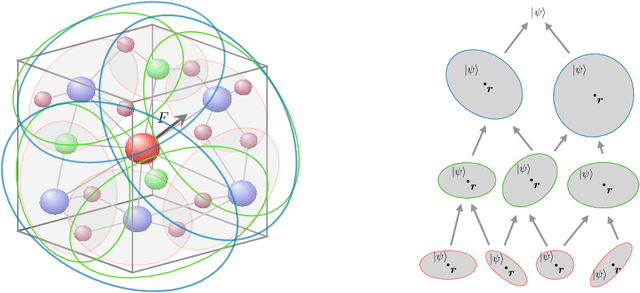
We describe N-body networks, a neural network architecture for learning the behavior and properties of complex many body physical systems. Our specific application is to learn atomic potential energy surfaces for use in molecular dynamics simulations. Our architecture is novel in that (a) it is based on a hierarchical decomposition of the many body system into subsytems, (b) the activations of the network correspond to the internal state of each subsystem, (c) the "neurons" in the network are constructed explicitly so as to guarantee that each of the activations is covariant to rotations, (d) the neurons operate entirely in Fourier space, and the nonlinearities are realized by tensor products followed by Clebsch-Gordan decompositions. As part of the description of our network, we give a characterization of what way the weights of the network may interact with the activations so as to ensure that the covariance property is maintained.
Multiresolution Kernel Approximation for Gaussian Process Regression
Jan 30, 2018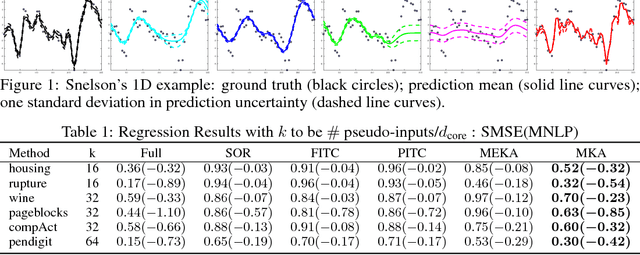
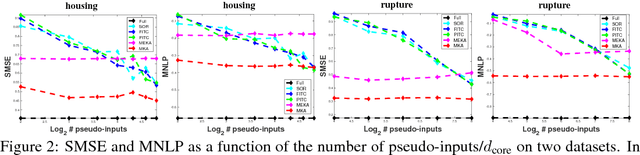
Gaussian process regression generally does not scale to beyond a few thousands data points without applying some sort of kernel approximation method. Most approximations focus on the high eigenvalue part of the spectrum of the kernel matrix, $K$, which leads to bad performance when the length scale of the kernel is small. In this paper we introduce Multiresolution Kernel Approximation (MKA), the first true broad bandwidth kernel approximation algorithm. Important points about MKA are that it is memory efficient, and it is a direct method, which means that it also makes it easy to approximate $K^{-1}$ and $\mathop{\textrm{det}}(K)$.
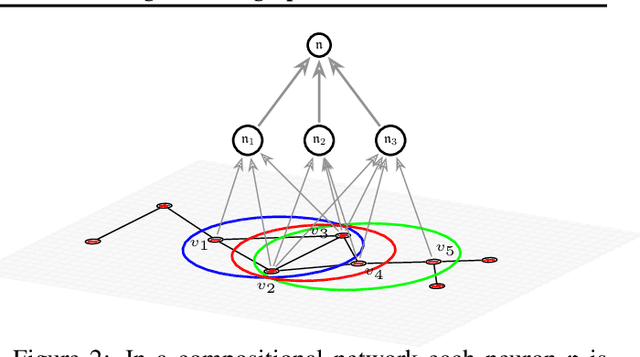
Covariant Compositional Networks For Learning Graphs
Jan 07, 2018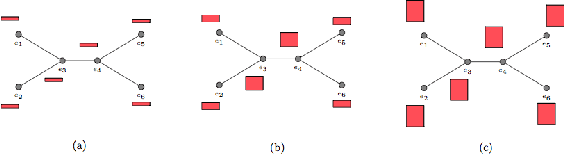
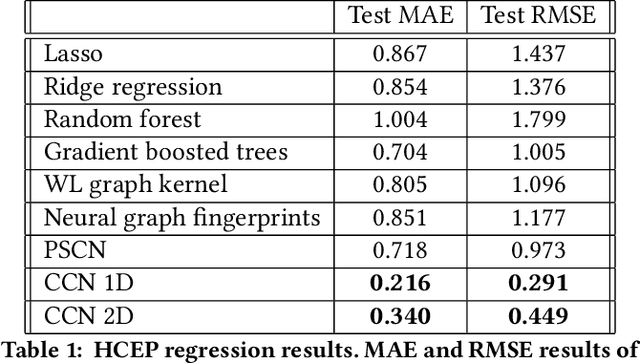
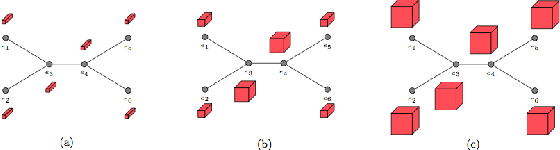
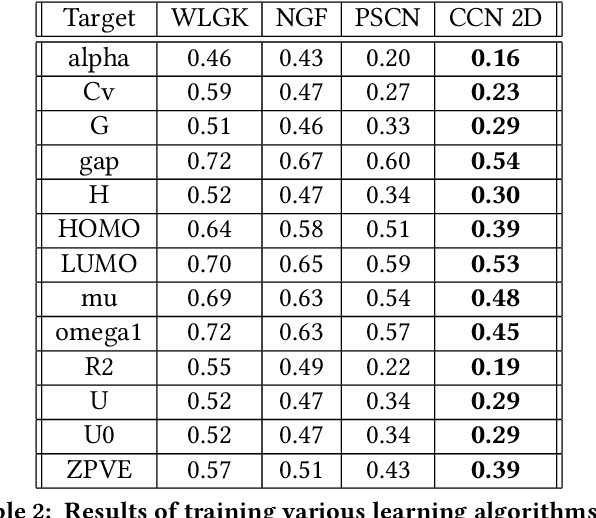
Most existing neural networks for learning graphs address permutation invariance by conceiving of the network as a message passing scheme, where each node sums the feature vectors coming from its neighbors. We argue that this imposes a limitation on their representation power, and instead propose a new general architecture for representing objects consisting of a hierarchy of parts, which we call Covariant Compositional Networks (CCNs). Here, covariance means that the activation of each neuron must transform in a specific way under permutations, similarly to steerability in CNNs. We achieve covariance by making each activation transform according to a tensor representation of the permutation group, and derive the corresponding tensor aggregation rules that each neuron must implement. Experiments show that CCNs can outperform competing methods on standard graph learning benchmarks.