 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework towards Domain Specific Video Summarization
Sep 24, 2018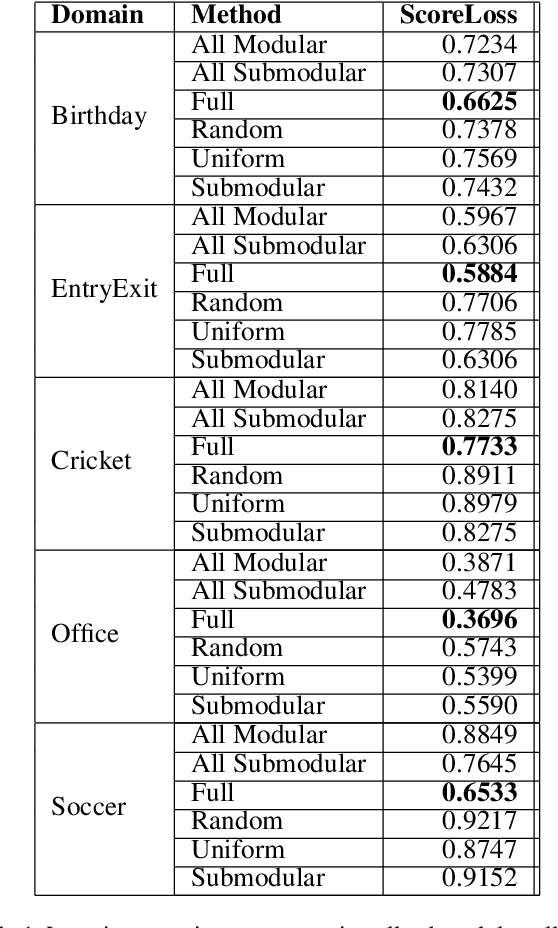


In the light of exponentially increasing video content, video summarization has attracted a lot of attention recently due to its ability to optimize time and storage. Characteristics of a good summary of a video depend on the particular domain under question. We propose a novel framework for domain specific video summarization. Given a video of a particular domain, our system can produce a summary based on what is important for that domain in addition to possessing other desired characteristics like representativeness, coverage, diversity etc. as suitable to that domain. Past related work has focused either on using supervised approaches for ranking the snippets to produce summary or on using unsupervised approaches of generating the summary as a subset of snippets with the above characteristics. We look at the joint problem of learning domain specific importance of segments as well as the desired summary characteristic for that domain. Our studies show that the more efficient way of incorporating domain specific relevances into a summary is by obtaining ratings of shots as opposed to binary inclusion/exclusion information. We also argue that ratings can be seen as unified representation of all possible ground truth summaries of a video, taking us one step closer in dealing with challenges associated with multiple ground truth summaries of a video. We also propose a novel evaluation measure which is more naturally suited in assessing the quality of video summary for the task at hand than F1 like measures. It leverages the ratings information and is richer in appropriately modeling desirable and undesirable characteristics of a summary. Lastly, we release a gold standard dataset for furthering research in domain specific video summarization, which to our knowledge is the first dataset with long videos across several domains with rating annotations.
Vis-DSS: An Open-Source toolkit for Visual Data Selection and Summarization
Sep 24, 2018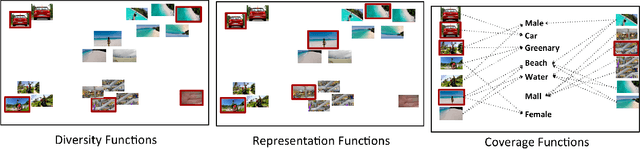

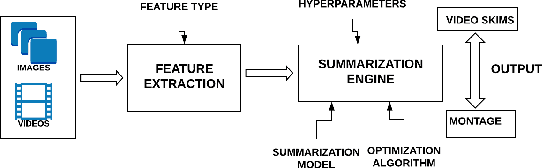
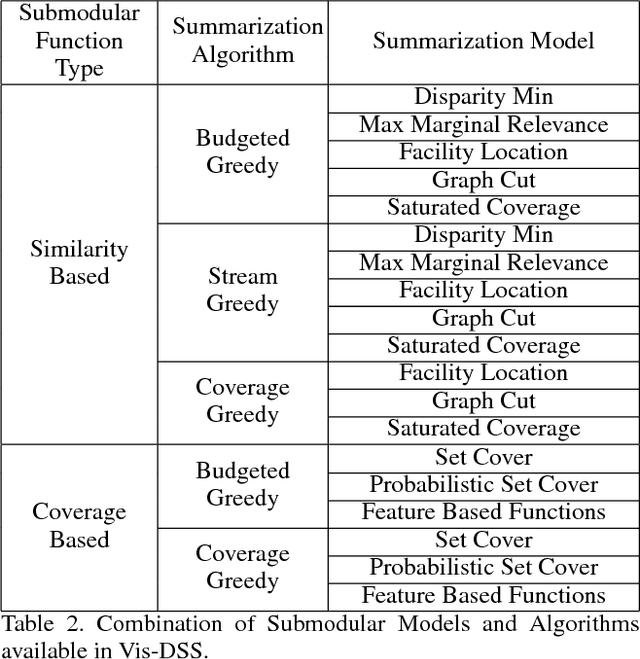
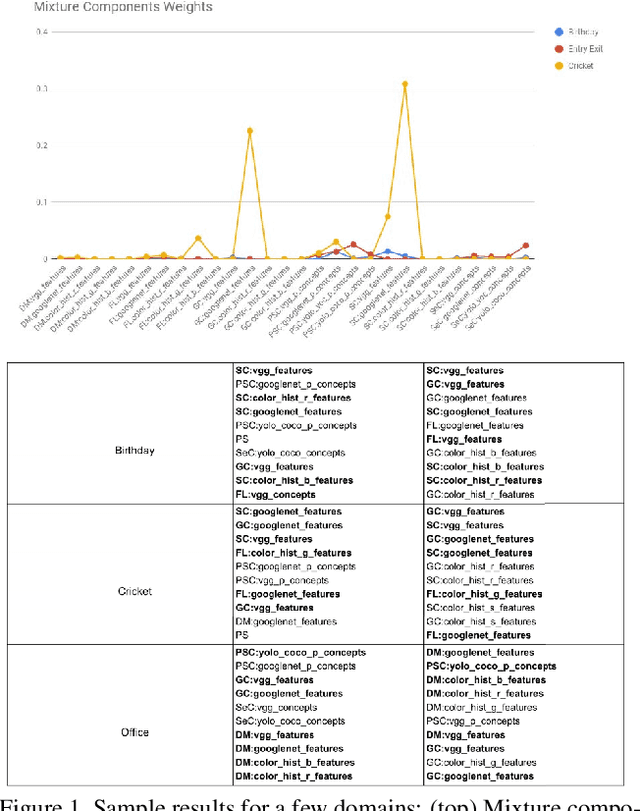
With increasing amounts of visual data being created in the form of videos and images, visual data selection and summarization are becoming ever increasing problems. We present Vis-DSS, an open-source toolkit for Visual Data Selection and Summarization. Vis-DSS implements a framework of models for summarization and data subset selection using submodular functions, which are becoming increasingly popular today for these problems. We present several classes of models, capturing notions of diversity, coverage, representation and importance, along with optimization/inference and learning algorithms. Vis-DSS is the first open source toolkit for several Data selection and summarization tasks including Image Collection Summarization, Video Summarization, Training Data selection for Classification and Diversified Active Learning. We demonstrate state-of-the art performance on all these tasks, and also show how we can scale to large problems. Vis-DSS allows easy integration for applications to be built on it, also can serve as a general skeleton that can be extended to several use cases, including video and image sharing platforms for creating GIFs, image montage creation, or as a component to surveillance systems and we demonstrate this by providing a graphical user-interface (GUI) desktop app built over Qt framework. Vis-DSS is available at https://github.com/rishabhk108/vis-dss
A Unified Batch Online Learning Framework for Click Prediction
Sep 12, 2018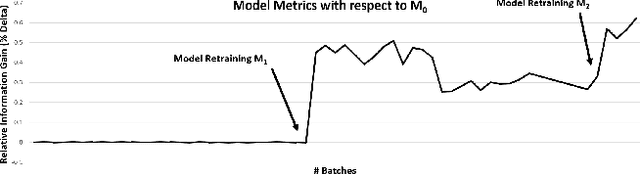
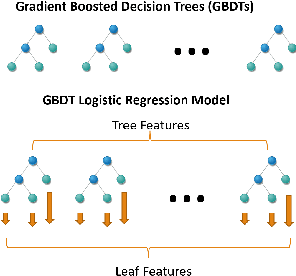
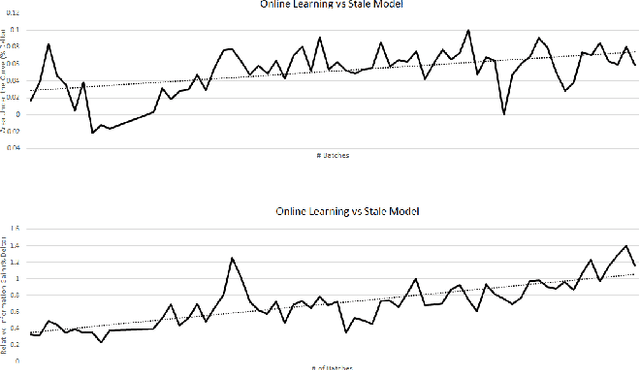
We present a unified framework for Batch Online Learning (OL) for Click Prediction in Search Advertisement. Machine Learning models once deployed, show non-trivial accuracy and calibration degradation over time due to model staleness. It is therefore necessary to regularly update models, and do so automatically. This paper presents two paradigms of Batch Online Learning, one which incrementally updates the model parameters via an early stopping mechanism, and another which does so through a proximal regularization. We argue how both these schemes naturally trade-off between old and new data. We then theoretically and empirically show that these two seemingly different schemes are closely related. Through extensive experiments, we demonstrate the utility of of our OL framework; how the two OL schemes relate to each other and how they trade-off between the new and historical data. We then compare batch OL to full model retrains, and show how online learning is more robust to data issues. We also demonstrate the long term impact of Online Learning, the role of the initial Models in OL, the impact of delays in the update, and finally conclude with some implementation details and challenges in deploying a real world online learning system in production. While this paper mostly focuses on application of click prediction for search advertisement, we hope that the lessons learned here can be carried over to other problem domains.
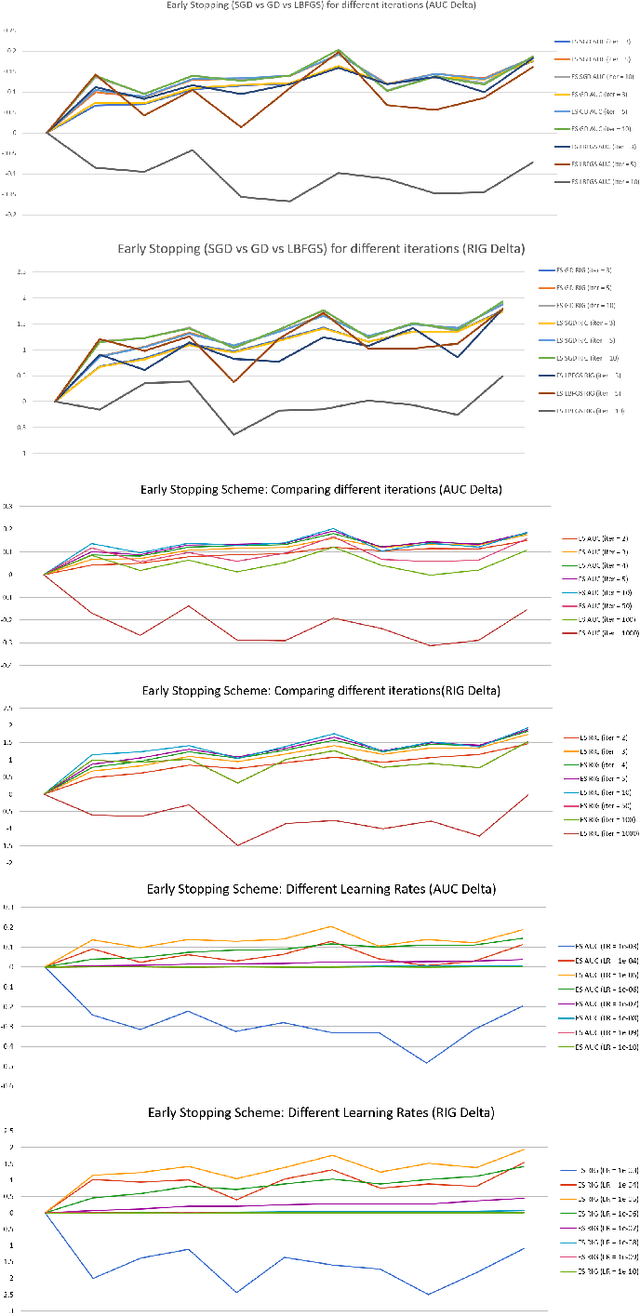
Jensen: An Easily-Extensible C++ Toolkit for Production-Level Machine Learning and Convex Optimization
Jul 17, 2018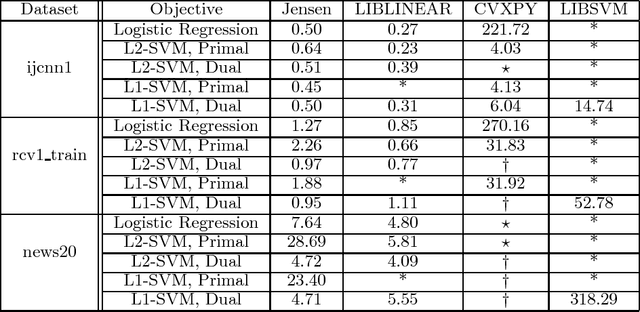
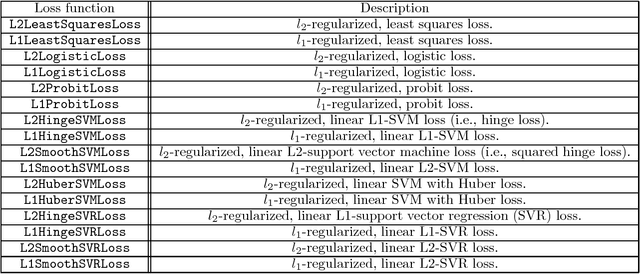
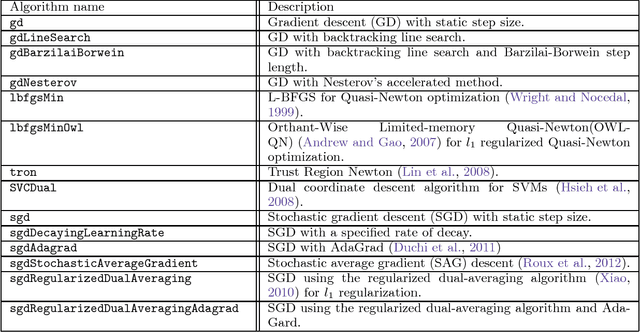
This paper introduces Jensen, an easily extensible and scalable toolkit for production-level machine learning and convex optimization. Jensen implements a framework of convex (or loss) functions, convex optimization algorithms (including Gradient Descent, L-BFGS, Stochastic Gradient Descent, Conjugate Gradient, etc.), and a family of machine learning classifiers and regressors (Logistic Regression, SVMs, Least Square Regression, etc.). This framework makes it possible to deploy and train models with a few lines of code, and also extend and build upon this by integrating new loss functions and optimization algorithms.
Deployment of Customized Deep Learning based Video Analytics On Surveillance Cameras
Jun 27, 2018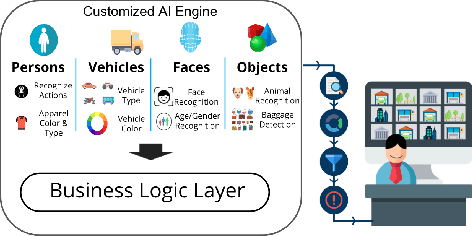
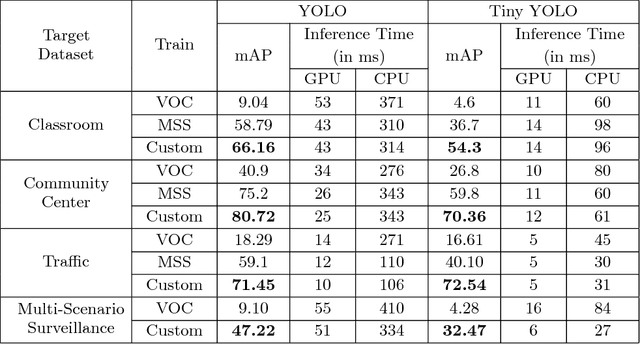

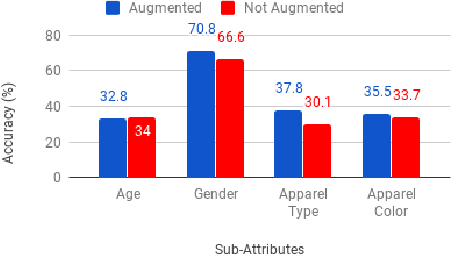
This paper demonstrates the effectiveness of our customized deep learning based video analytics system in various applications focused on security, safety, customer analytics and process compliance. We describe our video analytics system comprising of Search, Summarize, Statistics and real-time alerting, and outline its building blocks. These building blocks include object detection, tracking, face detection and recognition, human and face sub-attribute analytics. In each case, we demonstrate how custom models trained using data from the deployment scenarios provide considerably superior accuracies than off-the-shelf models. Towards this end, we describe our data processing and model training pipeline, which can train and fine-tune models from videos with a quick turnaround time. Finally, since most of these models are deployed on-site, it is important to have resource constrained models which do not require GPUs. We demonstrate how we custom train resource constrained models and deploy them on embedded devices without significant loss in accuracy. To our knowledge, this is the first work which provides a comprehensive evaluation of different deep learning models on various real-world customer deployment scenarios of surveillance video analytics. By sharing our implementation details and the experiences learned from deploying customized deep learning models for various customers, we hope that customized deep learning based video analytics is widely incorporated in commercial products around the world.
Learning From Less Data: Diversified Subset Selection and Active Learning in Image Classification Tasks
May 28, 2018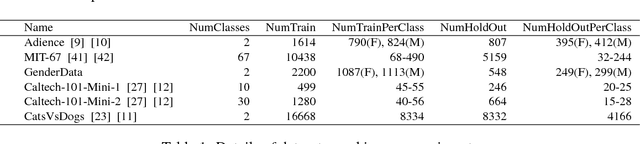
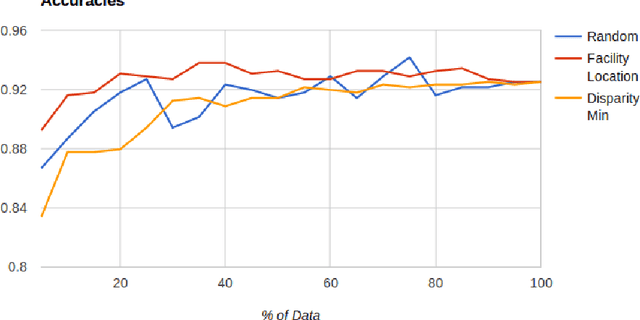
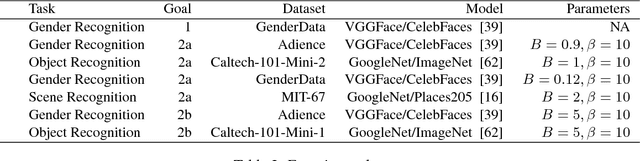
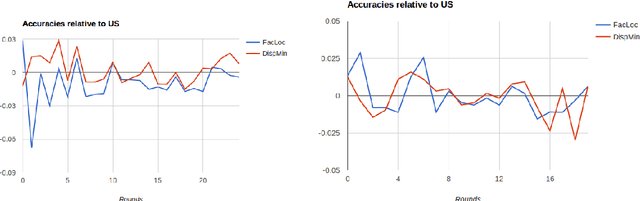
Supervised machine learning based state-of-the-art computer vision techniques are in general data hungry and pose the challenges of not having adequate computing resources and of high costs involved in human labeling efforts. Training data subset selection and active learning techniques have been proposed as possible solutions to these challenges respectively. A special class of subset selection functions naturally model notions of diversity, coverage and representation and they can be used to eliminate redundancy and thus lend themselves well for training data subset selection. They can also help improve the efficiency of active learning in further reducing human labeling efforts by selecting a subset of the examples obtained using the conventional uncertainty sampling based techniques. In this work we empirically demonstrate the effectiveness of two diversity models, namely the Facility-Location and Disparity-Min models for training-data subset selection and reducing labeling effort. We do this for a variety of computer vision tasks including Gender Recognition, Scene Recognition and Object Recognition. Our results show that subset selection done in the right way can add 2-3% in accuracy on existing baselines, particularly in the case of less training data. This allows the training of complex machine learning models (like Convolutional Neural Networks) with much less training data while incurring minimal performance loss.
Modeling and Simultaneously Removing Bias via Adversarial Neural Networks
Apr 18, 2018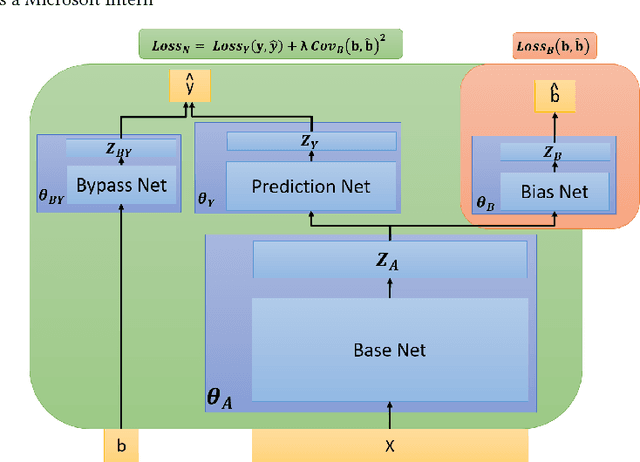
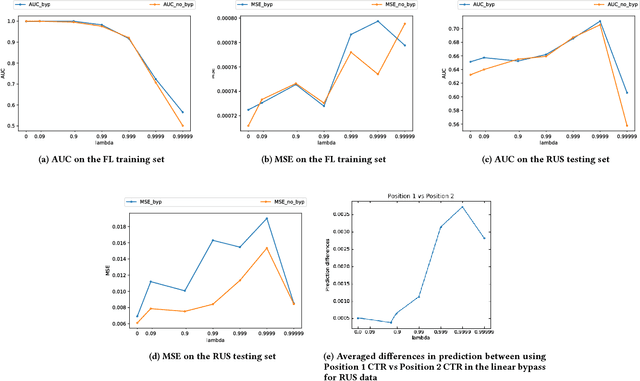
In real world systems, the predictions of deployed Machine Learned models affect the training data available to build subsequent models. This introduces a bias in the training data that needs to be addressed. Existing solutions to this problem attempt to resolve the problem by either casting this in the reinforcement learning framework or by quantifying the bias and re-weighting the loss functions. In this work, we develop a novel Adversarial Neural Network (ANN) model, an alternative approach which creates a representation of the data that is invariant to the bias. We take the Paid Search auction as our working example and ad display position features as the confounding features for this setting. We show the success of this approach empirically on both synthetic data as well as real world paid search auction data from a major search engine.
A Unified Multi-Faceted Video Summarization System
Apr 04, 2017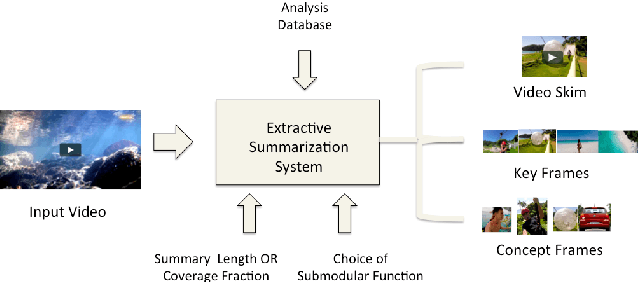

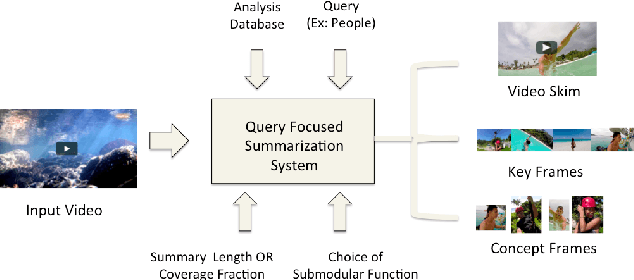

This paper addresses automatic summarization and search in visual data comprising of videos, live streams and image collections in a unified manner. In particular, we propose a framework for multi-faceted summarization which extracts key-frames (image summaries), skims (video summaries) and entity summaries (summarization at the level of entities like objects, scenes, humans and faces in the video). The user can either view these as extractive summarization, or query focused summarization. Our approach first pre-processes the video or image collection once, to extract all important visual features, following which we provide an interactive mechanism to the user to summarize the video based on their choice. We investigate several diversity, coverage and representation models for all these problems, and argue the utility of these different mod- els depending on the application. While most of the prior work on submodular summarization approaches has focused on combining several models and learning weighted mixtures, we focus on the explain-ability of different the diversity, coverage and representation models and their scalability. Most importantly, we also show that we can summarize hours of video data in a few seconds, and our system allows the user to generate summaries of various lengths and types interactively on the fly.
Mixed Robust/Average Submodular Partitioning: Fast Algorithms, Guarantees, and Applications to Parallel Machine Learning and Multi-Label Image Segmentation
Aug 16, 2016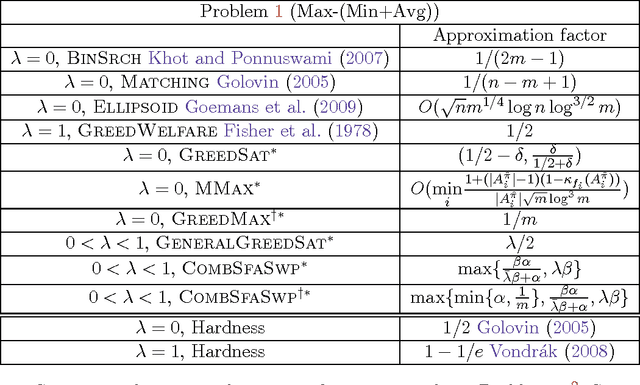
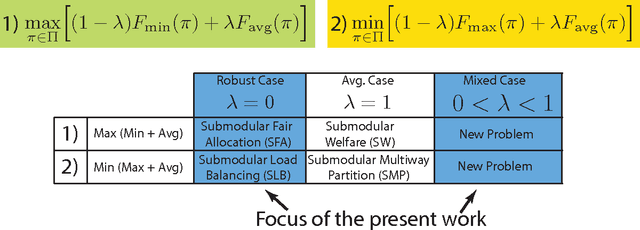
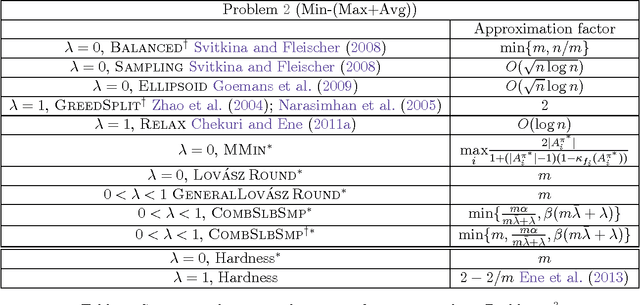
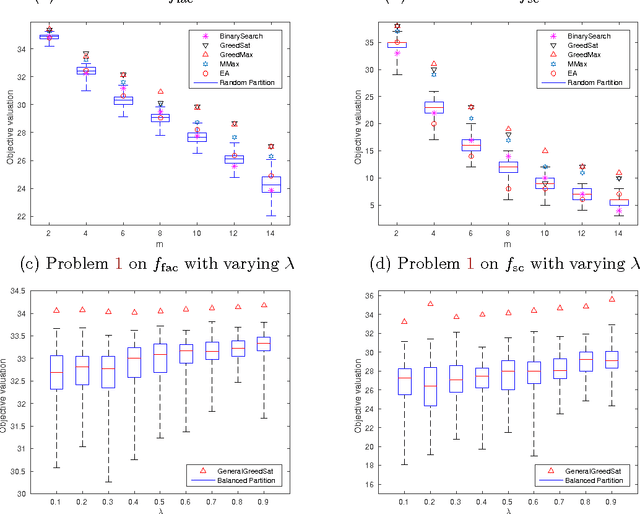
We study two mixed robust/average-case submodular partitioning problems that we collectively call Submodular Partitioning. These problems generalize both purely robust instances of the problem (namely max-min submodular fair allocation (SFA) and min-max submodular load balancing (SLB) and also generalize average-case instances (that is the submodular welfare problem (SWP) and submodular multiway partition (SMP). While the robust versions have been studied in the theory community, existing work has focused on tight approximation guarantees, and the resultant algorithms are not, in general, scalable to very large real-world applications. This is in contrast to the average case, where most of the algorithms are scalable. In the present paper, we bridge this gap, by proposing several new algorithms (including those based on greedy, majorization-minimization, minorization-maximization, and relaxation algorithms) that not only scale to large sizes but that also achieve theoretical approximation guarantees close to the state-of-the-art, and in some cases achieve new tight bounds. We also provide new scalable algorithms that apply to additive combinations of the robust and average-case extreme objectives. We show that these problems have many applications in machine learning (ML). This includes: 1) data partitioning and load balancing for distributed machine algorithms on parallel machines; 2) data clustering; and 3) multi-label image segmentation with (only) Boolean submodular functions via pixel partitioning. We empirically demonstrate the efficacy of our algorithms on real-world problems involving data partitioning for distributed optimization of standard machine learning objectives (including both convex and deep neural network objectives), and also on purely unsupervised (i.e., no supervised or semi-supervised learning, and no interactive segmentation) image segmentation.
Submodular Hamming Metrics
Nov 06, 2015


We show that there is a largely unexplored class of functions (positive polymatroids) that can define proper discrete metrics over pairs of binary vectors and that are fairly tractable to optimize over. By exploiting submodularity, we are able to give hardness results and approximation algorithms for optimizing over such metrics. Additionally, we demonstrate empirically the effectiveness of these metrics and associated algorithms on both a metric minimization task (a form of clustering) and also a metric maximization task (generating diverse k-best lists).