 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoot Mean Square Layer Normalization
Oct 16, 2019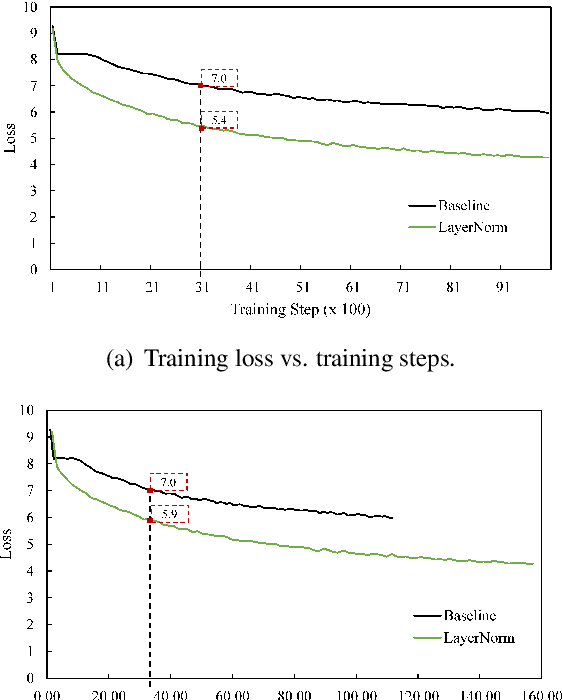

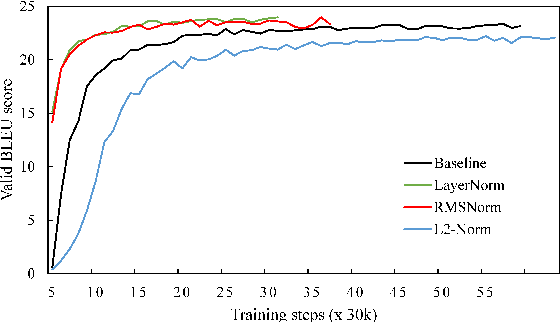
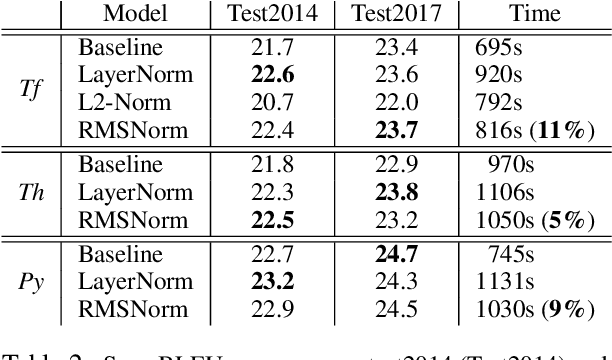
Layer normalization (LayerNorm) has been successfully applied to various deep neural networks to help stabilize training and boost model convergence because of its capability in handling re-centering and re-scaling of both inputs and weight matrix. However, the computational overhead introduced by LayerNorm makes these improvements expensive and significantly slows the underlying network, e.g. RNN in particular. In this paper, we hypothesize that re-centering invariance in LayerNorm is dispensable and propose root mean square layer normalization, or RMSNorm. RMSNorm regularizes the summed inputs to a neuron in one layer according to root mean square (RMS), giving the model re-scaling invariance property and implicit learning rate adaptation ability. RMSNorm is computationally simpler and thus more efficient than LayerNorm. We also present partial RMSNorm, or pRMSNorm where the RMS is estimated from p% of the summed inputs without breaking the above properties. Extensive experiments on several tasks using diverse network architectures show that RMSNorm achieves comparable performance against LayerNorm but reduces the running time by 7%~64% on different models. Source code is available at https://github.com/bzhangGo/rmsnorm.
Context-Aware Monolingual Repair for Neural Machine Translation
Oct 15, 2019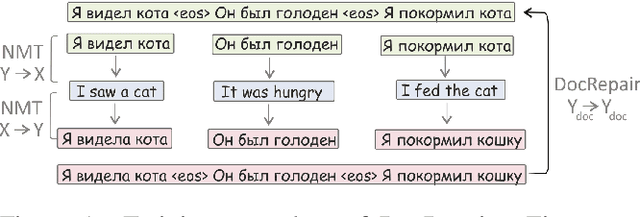
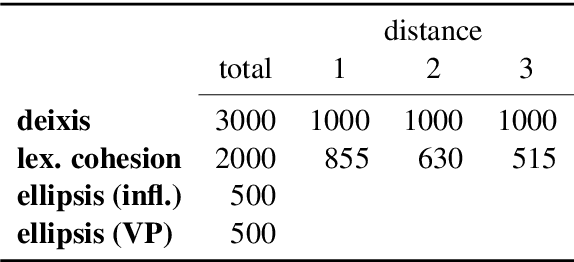
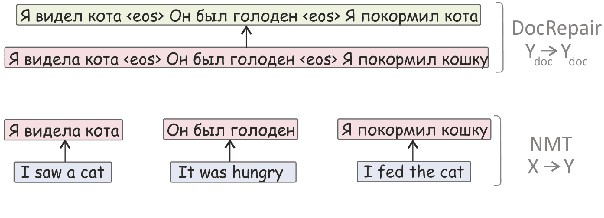
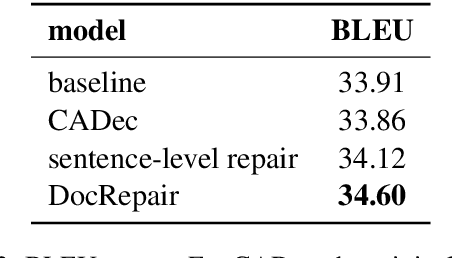
Modern sentence-level NMT systems often produce plausible translations of isolated sentences. However, when put in context, these translations may end up being inconsistent with each other. We propose a monolingual DocRepair model to correct inconsistencies between sentence-level translations. DocRepair performs automatic post-editing on a sequence of sentence-level translations, refining translations of sentences in context of each other. For training, the DocRepair model requires only monolingual document-level data in the target language. It is trained as a monolingual sequence-to-sequence model that maps inconsistent groups of sentences into consistent ones. The consistent groups come from the original training data; the inconsistent groups are obtained by sampling round-trip translations for each isolated sentence. We show that this approach successfully imitates inconsistencies we aim to fix: using contrastive evaluation, we show large improvements in the translation of several contextual phenomena in an English-Russian translation task, as well as improvements in the BLEU score. We also conduct a human evaluation and show a strong preference of the annotators to corrected translations over the baseline ones. Moreover, we analyze which discourse phenomena are hard to capture using monolingual data only.
The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives
Sep 03, 2019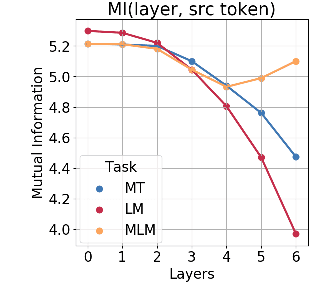
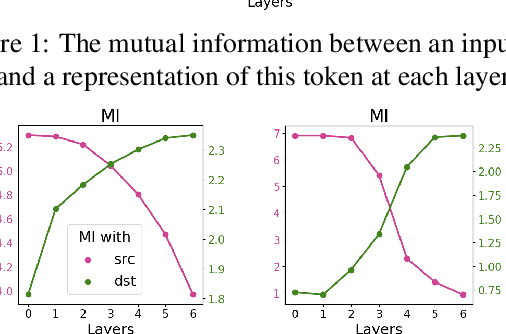
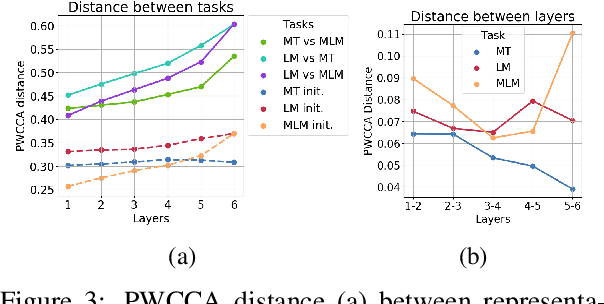
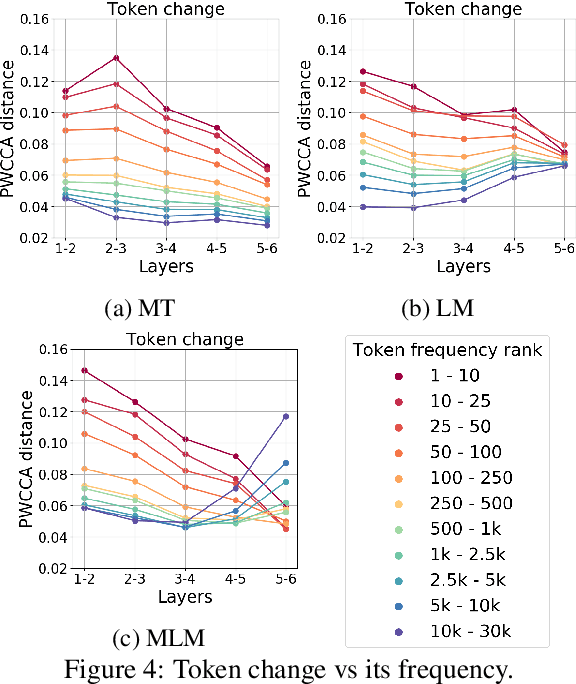
We seek to understand how the representations of individual tokens and the structure of the learned feature space evolve between layers in deep neural networks under different learning objectives. We focus on the Transformers for our analysis as they have been shown effective on various tasks, including machine translation (MT), standard left-to-right language models (LM) and masked language modeling (MLM). Previous work used black-box probing tasks to show that the representations learned by the Transformer differ significantly depending on the objective. In this work, we use canonical correlation analysis and mutual information estimators to study how information flows across Transformer layers and how this process depends on the choice of learning objective. For example, as you go from bottom to top layers, information about the past in left-to-right language models gets vanished and predictions about the future get formed. In contrast, for MLM, representations initially acquire information about the context around the token, partially forgetting the token identity and producing a more generalized token representation. The token identity then gets recreated at the top MLM layers.
Encoders Help You Disambiguate Word Senses in Neural Machine Translation
Aug 30, 2019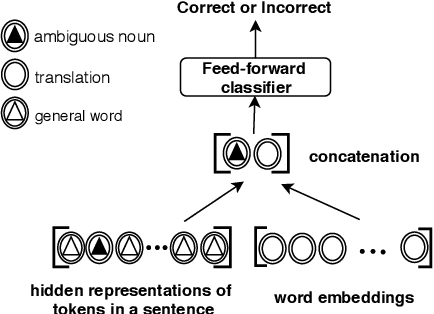
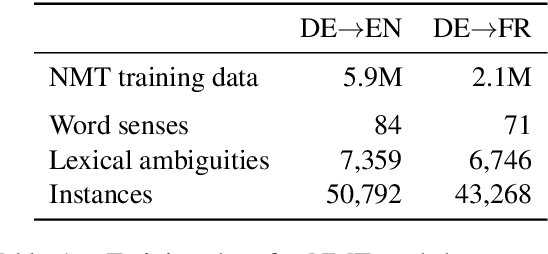
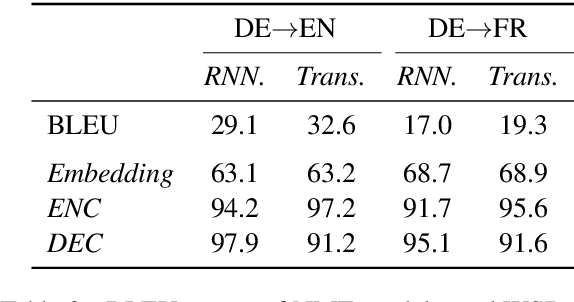
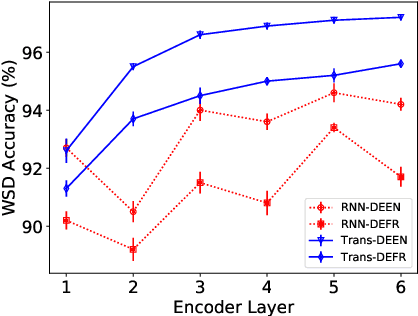
Neural machine translation (NMT) has achieved new state-of-the-art performance in translating ambiguous words. However, it is still unclear which component dominates the process of disambiguation. In this paper, we explore the ability of NMT encoders and decoders to disambiguate word senses by evaluating hidden states and investigating the distributions of self-attention. We train a classifier to predict whether a translation is correct given the representation of an ambiguous noun. We find that encoder hidden states outperform word embeddings significantly which indicates that encoders adequately encode relevant information for disambiguation into hidden states. In contrast to encoders, the effect of decoder is different in models with different architectures. Moreover, the attention weights and attention entropy show that self-attention can detect ambiguous nouns and distribute more attention to the context.
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
Aug 29, 2019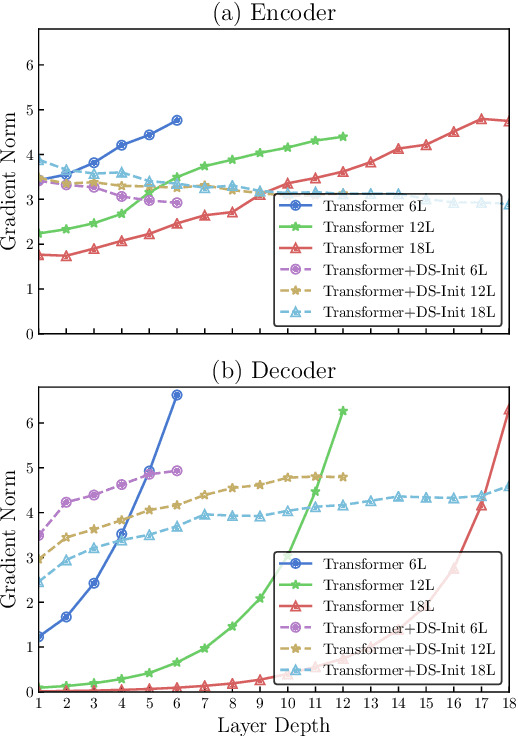
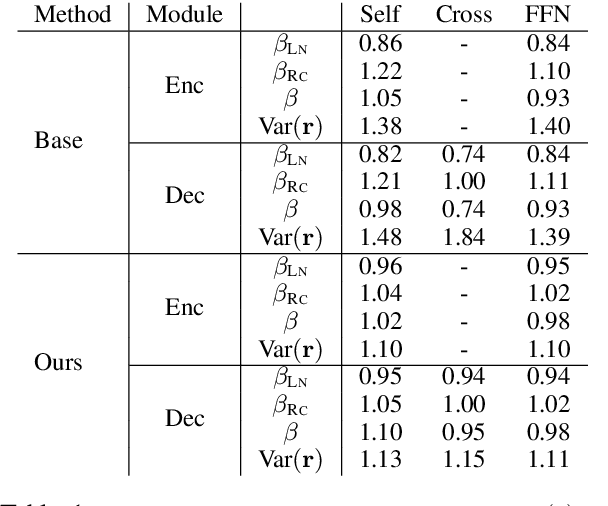
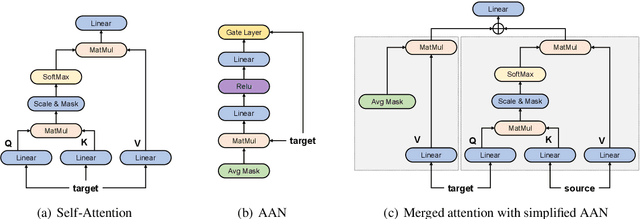
The general trend in NLP is towards increasing model capacity and performance via deeper neural networks. However, simply stacking more layers of the popular Transformer architecture for machine translation results in poor convergence and high computational overhead. Our empirical analysis suggests that convergence is poor due to gradient vanishing caused by the interaction between residual connections and layer normalization. We propose depth-scaled initialization (DS-Init), which decreases parameter variance at the initialization stage, and reduces output variance of residual connections so as to ease gradient back-propagation through normalization layers. To address computational cost, we propose a merged attention sublayer (MAtt) which combines a simplified averagebased self-attention sublayer and the encoderdecoder attention sublayer on the decoder side. Results on WMT and IWSLT translation tasks with five translation directions show that deep Transformers with DS-Init and MAtt can substantially outperform their base counterpart in terms of BLEU (+1.1 BLEU on average for 12-layer models), while matching the decoding speed of the baseline model thanks to the efficiency improvements of MAtt.
Understanding Neural Machine Translation by Simplification: The Case of Encoder-free Models
Jul 18, 2019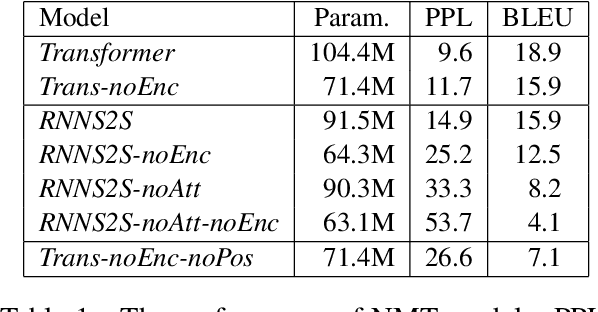
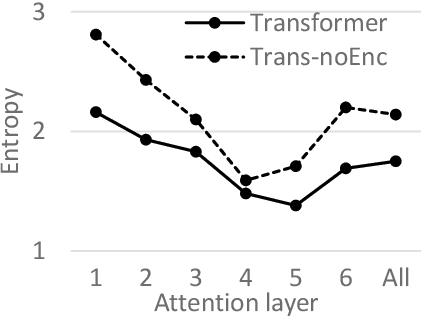

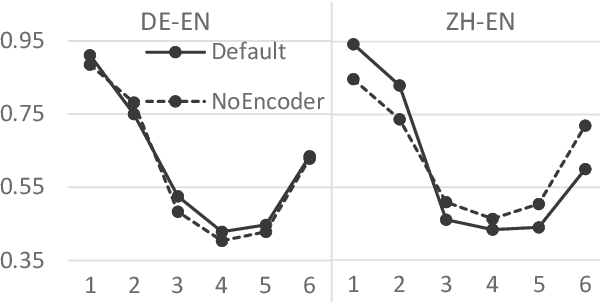
In this paper, we try to understand neural machine translation (NMT) via simplifying NMT architectures and training encoder-free NMT models. In an encoder-free model, the sums of word embeddings and positional embeddings represent the source. The decoder is a standard Transformer or recurrent neural network that directly attends to embeddings via attention mechanisms. Experimental results show (1) that the attention mechanism in encoder-free models acts as a strong feature extractor, (2) that the word embeddings in encoder-free models are competitive to those in conventional models, (3) that non-contextualized source representations lead to a big performance drop, and (4) that encoder-free models have different effects on alignment quality for German-English and Chinese-English.
Widening the Representation Bottleneck in Neural Machine Translation with Lexical Shortcuts
Jun 28, 2019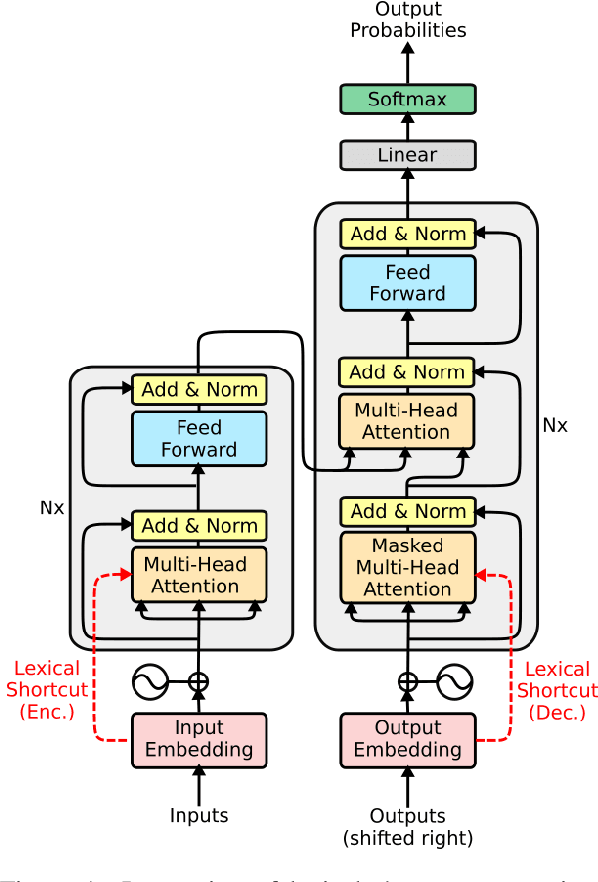
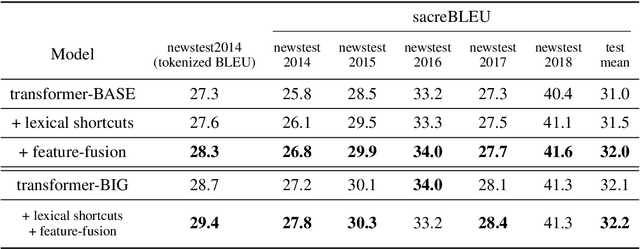
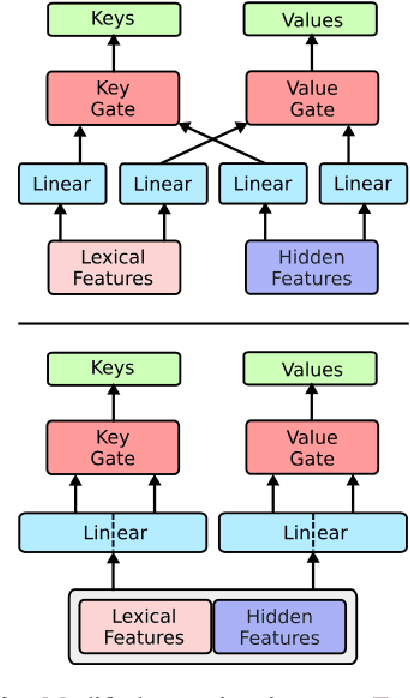
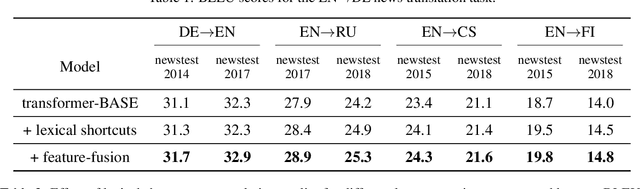
The transformer is a state-of-the-art neural translation model that uses attention to iteratively refine lexical representations with information drawn from the surrounding context. Lexical features are fed into the first layer and propagated through a deep network of hidden layers. We argue that the need to represent and propagate lexical features in each layer limits the model's capacity for learning and representing other information relevant to the task. To alleviate this bottleneck, we introduce gated shortcut connections between the embedding layer and each subsequent layer within the encoder and decoder. This enables the model to access relevant lexical content dynamically, without expending limited resources on storing it within intermediate states. We show that the proposed modification yields consistent improvements over a baseline transformer on standard WMT translation tasks in 5 translation directions (0.9 BLEU on average) and reduces the amount of lexical information passed along the hidden layers. We furthermore evaluate different ways to integrate lexical connections into the transformer architecture and present ablation experiments exploring the effect of proposed shortcuts on model behavior.
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Jun 07, 2019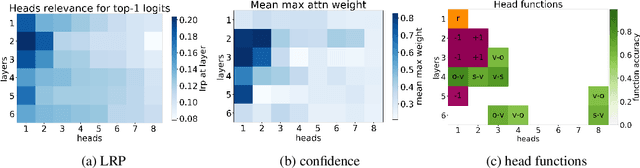
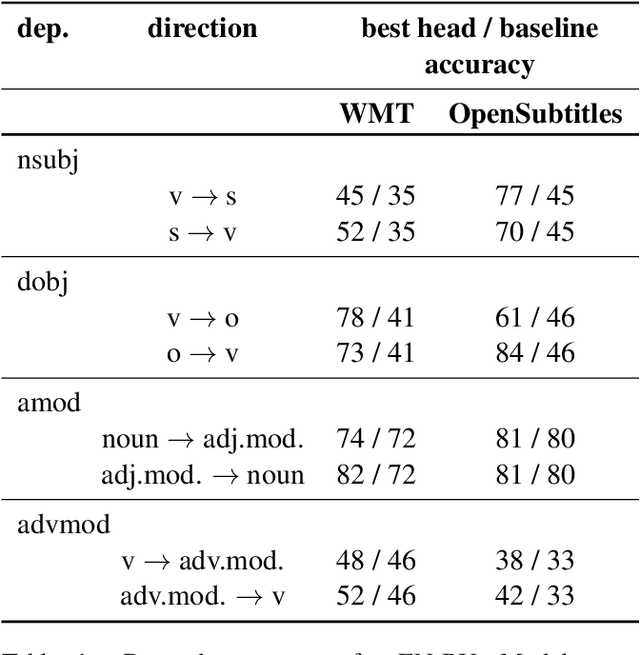
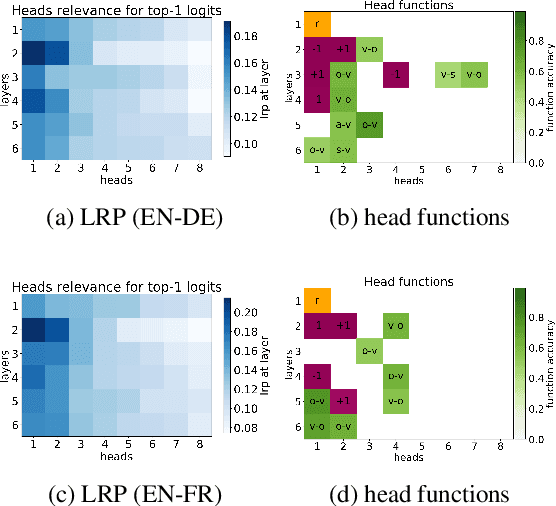
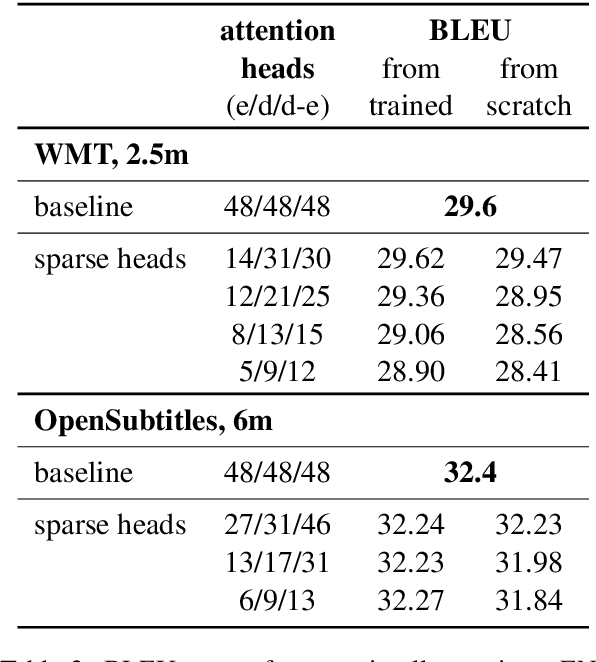
Multi-head self-attention is a key component of the Transformer, a state-of-the-art architecture for neural machine translation. In this work we evaluate the contribution made by individual attention heads in the encoder to the overall performance of the model and analyze the roles played by them. We find that the most important and confident heads play consistent and often linguistically-interpretable roles. When pruning heads using a method based on stochastic gates and a differentiable relaxation of the L0 penalty, we observe that specialized heads are last to be pruned. Our novel pruning method removes the vast majority of heads without seriously affecting performance. For example, on the English-Russian WMT dataset, pruning 38 out of 48 encoder heads results in a drop of only 0.15 BLEU.
A Lightweight Recurrent Network for Sequence Modeling
May 30, 2019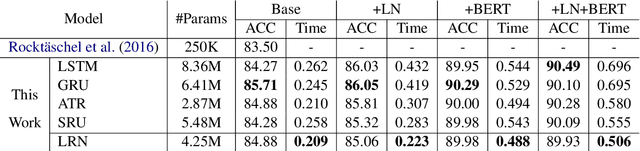
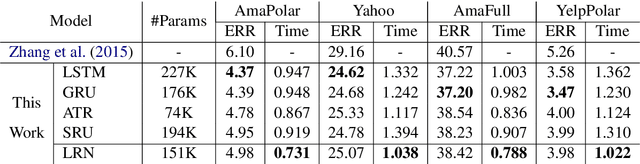
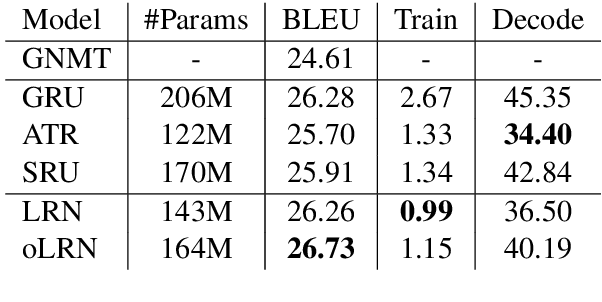
Recurrent networks have achieved great success on various sequential tasks with the assistance of complex recurrent units, but suffer from severe computational inefficiency due to weak parallelization. One direction to alleviate this issue is to shift heavy computations outside the recurrence. In this paper, we propose a lightweight recurrent network, or LRN. LRN uses input and forget gates to handle long-range dependencies as well as gradient vanishing and explosion, with all parameter related calculations factored outside the recurrence. The recurrence in LRN only manipulates the weight assigned to each token, tightly connecting LRN with self-attention networks. We apply LRN as a drop-in replacement of existing recurrent units in several neural sequential models. Extensive experiments on six NLP tasks show that LRN yields the best running efficiency with little or no loss in model performance.
Revisiting Low-Resource Neural Machine Translation: A Case Study
May 28, 2019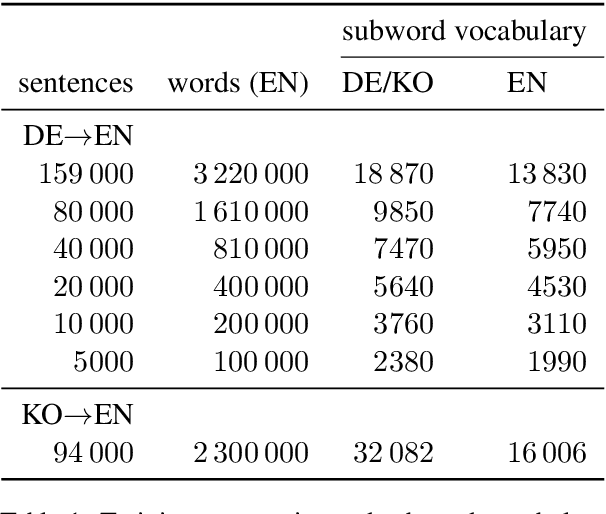

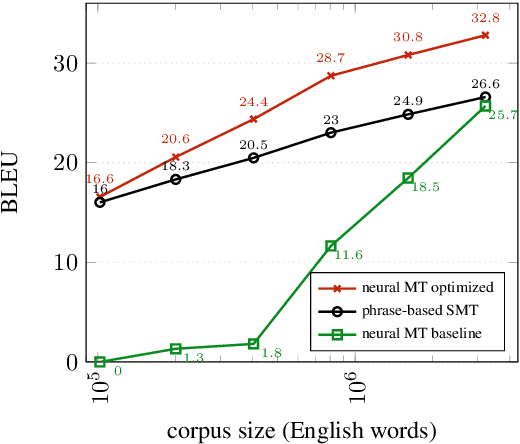
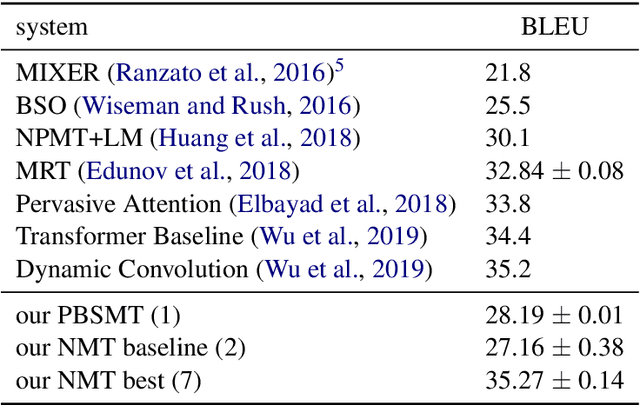
It has been shown that the performance of neural machine translation (NMT) drops starkly in low-resource conditions, underperforming phrase-based statistical machine translation (PBSMT) and requiring large amounts of auxiliary data to achieve competitive results. In this paper, we re-assess the validity of these results, arguing that they are the result of lack of system adaptation to low-resource settings. We discuss some pitfalls to be aware of when training low-resource NMT systems, and recent techniques that have shown to be especially helpful in low-resource settings, resulting in a set of best practices for low-resource NMT. In our experiments on German--English with different amounts of IWSLT14 training data, we show that, without the use of any auxiliary monolingual or multilingual data, an optimized NMT system can outperform PBSMT with far less data than previously claimed. We also apply these techniques to a low-resource Korean-English dataset, surpassing previously reported results by 4 BLEU.