 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN Approaches to Text Normalization: A Challenge
Jan 24, 2017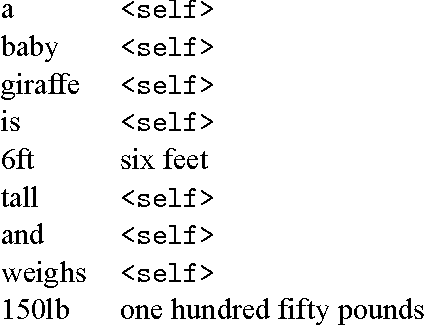

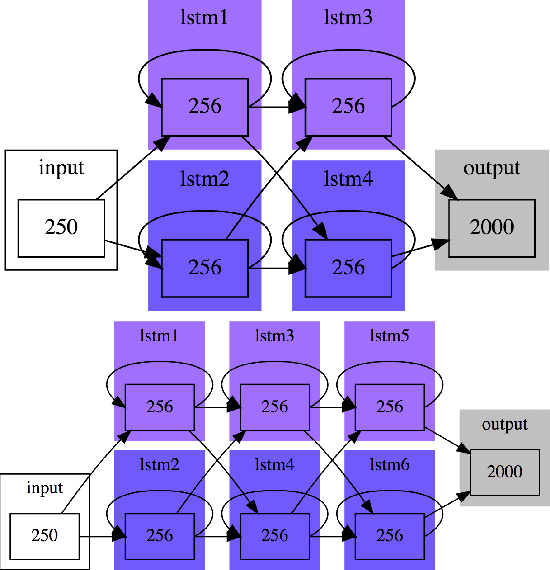
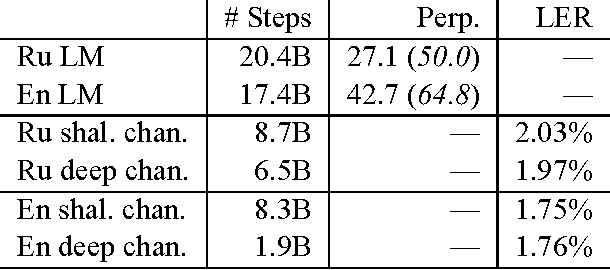
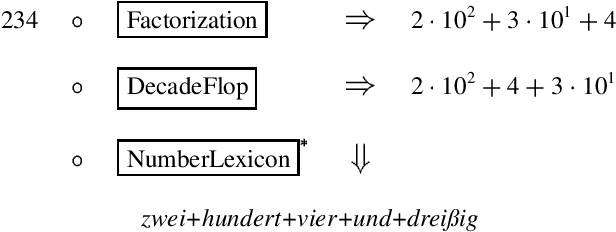
This paper presents a challenge to the community: given a large corpus of written text aligned to its normalized spoken form, train an RNN to learn the correct normalization function. We present a data set of general text where the normalizations were generated using an existing text normalization component of a text-to-speech system. This data set will be released open-source in the near future. We also present our own experiments with this data set with a variety of different RNN architectures. While some of the architectures do in fact produce very good results when measured in terms of overall accuracy, the errors that are produced are problematic, since they would convey completely the wrong message if such a system were deployed in a speech application. On the other hand, we show that a simple FST-based filter can mitigate those errors, and achieve a level of accuracy not achievable by the RNN alone. Though our conclusions are largely negative on this point, we are actually not arguing that the text normalization problem is intractable using an pure RNN approach, merely that it is not going to be something that can be solved merely by having huge amounts of annotated text data and feeding that to a general RNN model. And when we open-source our data, we will be providing a novel data set for sequence-to-sequence modeling in the hopes that the the community can find better solutions. The data used in this work have been released and are available at: https://github.com/rwsproat/text-normalization-data
Minimally Supervised Written-to-Spoken Text Normalization
Sep 21, 2016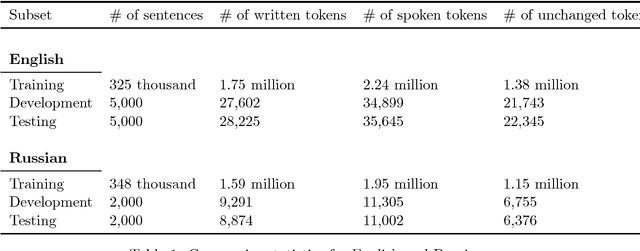
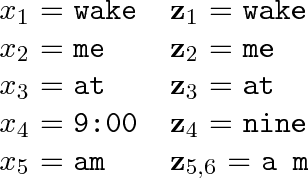

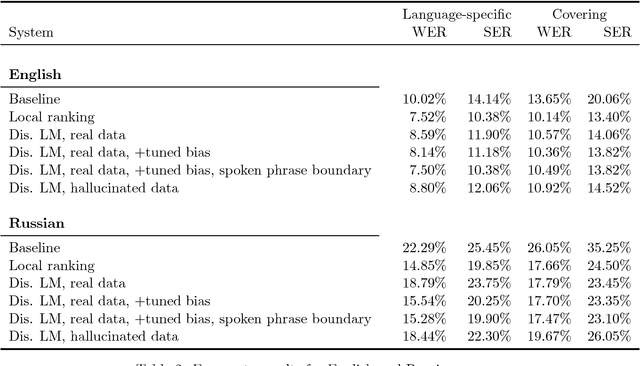
In speech-applications such as text-to-speech (TTS) or automatic speech recognition (ASR), \emph{text normalization} refers to the task of converting from a \emph{written} representation into a representation of how the text is to be \emph{spoken}. In all real-world speech applications, the text normalization engine is developed---in large part---by hand. For example, a hand-built grammar may be used to enumerate the possible ways of saying a given token in a given language, and a statistical model used to select the most appropriate pronunciation in context. In this study we examine the tradeoffs associated with using more or less language-specific domain knowledge in a text normalization engine. In the most data-rich scenario, we have access to a carefully constructed hand-built normalization grammar that for any given token will produce a set of all possible verbalizations for that token. We also assume a corpus of aligned written-spoken utterances, from which we can train a ranking model that selects the appropriate verbalization for the given context. As a substitute for the carefully constructed grammar, we also consider a scenario with a language-universal normalization \emph{covering grammar}, where the developer merely needs to provide a set of lexical items particular to the language. As a substitute for the aligned corpus, we also consider a scenario where one only has the spoken side, and the corresponding written side is "hallucinated" by composing the spoken side with the inverted normalization grammar. We investigate the accuracy of a text normalization engine under each of these scenarios. We report the results of experiments on English and Russian.
Algorithms for Speech Recognition and Language Processing
Sep 17, 1996Speech processing requires very efficient methods and algorithms. Finite-state transducers have been shown recently both to constitute a very useful abstract model and to lead to highly efficient time and space algorithms in this field. We present these methods and algorithms and illustrate them in the case of speech recognition. In addition to classical techniques, we describe many new algorithms such as minimization, global and local on-the-fly determinization of weighted automata, and efficient composition of transducers. These methods are currently used in large vocabulary speech recognition systems. We then show how the same formalism and algorithms can be used in text-to-speech applications and related areas of language processing such as morphology, syntax, and local grammars, in a very efficient way. The tutorial is self-contained and requires no specific computational or linguistic knowledge other than classical results.
Multilingual Text Analysis for Text-to-Speech Synthesis
Aug 19, 1996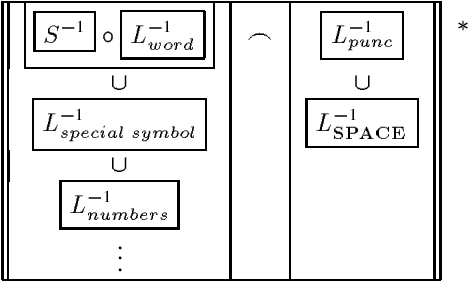
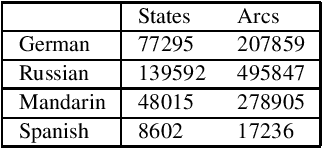
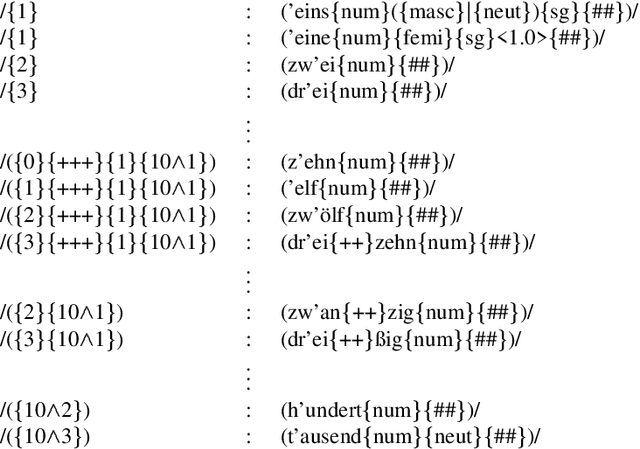
We present a model of text analysis for text-to-speech (TTS) synthesis based on (weighted) finite-state transducers, which serves as the text-analysis module of the multilingual Bell Labs TTS system. The transducers are constructed using a lexical toolkit that allows declarative descriptions of lexicons, morphological rules, numeral-expansion rules, and phonological rules, inter alia. To date, the model has been applied to eight languages: Spanish, Italian, Romanian, French, German, Russian, Mandarin and Japanese.
An Efficient Compiler for Weighted Rewrite Rules
Jun 20, 1996Context-dependent rewrite rules are used in many areas of natural language and speech processing. Work in computational phonology has demonstrated that, given certain conditions, such rewrite rules can be represented as finite-state transducers (FSTs). We describe a new algorithm for compiling rewrite rules into FSTs. We show the algorithm to be simpler and more efficient than existing algorithms. Further, many of our applications demand the ability to compile weighted rules into weighted FSTs, transducers generalized by providing transitions with weights. We have extended the algorithm to allow for this.
Compilation of Weighted Finite-State Transducers from Decision Trees
Jun 14, 1996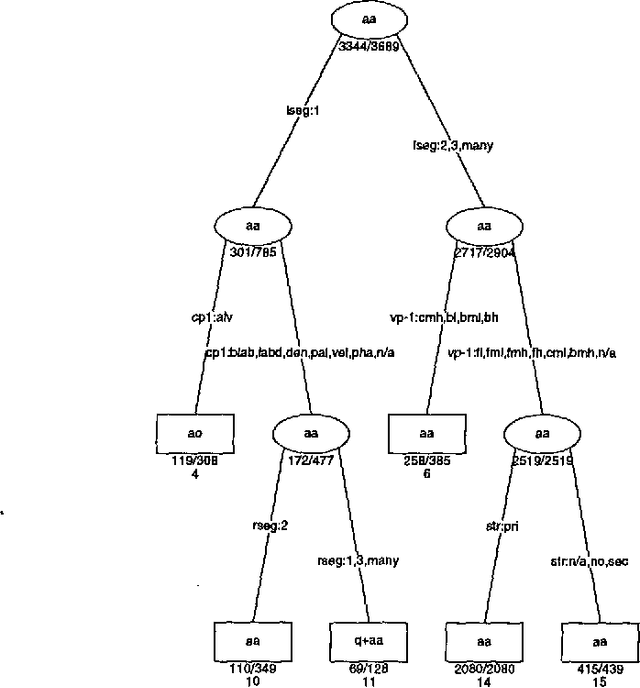

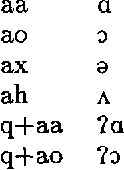

We report on a method for compiling decision trees into weighted finite-state transducers. The key assumptions are that the tree predictions specify how to rewrite symbols from an input string, and the decision at each tree node is stateable in terms of regular expressions on the input string. Each leaf node can then be treated as a separate rule where the left and right contexts are constructable from the decisions made traversing the tree from the root to the leaf. These rules are compiled into transducers using the weighted rewrite-rule rule-compilation algorithm described in (Mohri and Sproat, 1996).
Estimating Lexical Priors for Low-Frequency Syncretic Forms
Apr 24, 1995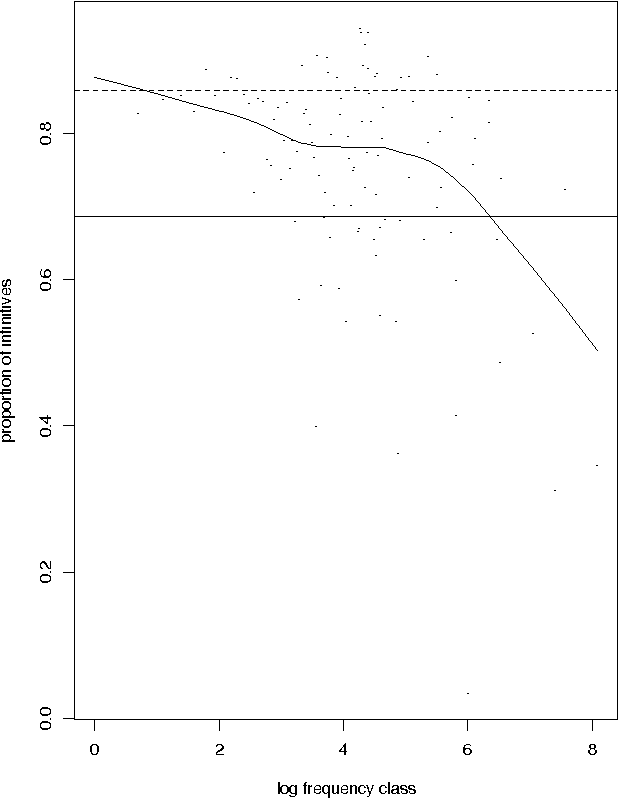
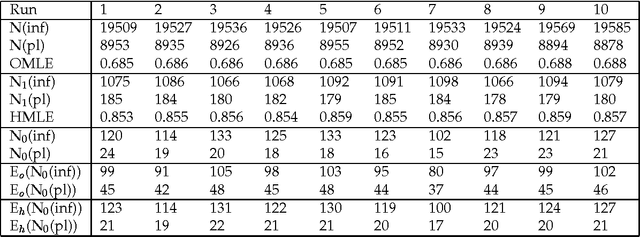
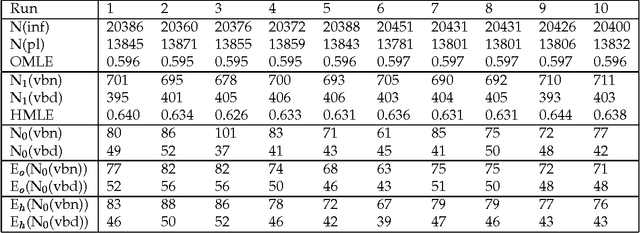
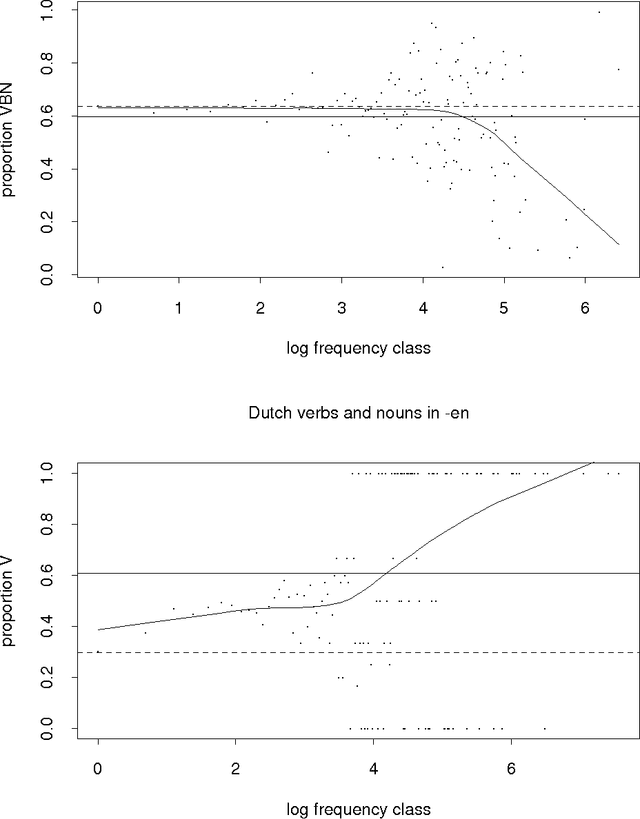
Given a previously unseen form that is morphologically n-ways ambiguous, what is the best estimator for the lexical prior probabilities for the various functions of the form? We argue that the best estimator is provided by computing the relative frequencies of the various functions among the hapax legomena --- the forms that occur exactly once in a corpus. This result has important implications for the development of stochastic morphological taggers, especially when some initial hand-tagging of a corpus is required: For predicting lexical priors for very low-frequency morphologically ambiguous types (most of which would not occur in any given corpus) one should concentrate on tagging a good representative sample of the hapax legomena, rather than extensively tagging words of all frequency ranges.
Text Analysis Tools in Spoken Language Processing
Jun 23, 1994This submission contains the postscript of the final version of the slides used in our ACL-94 tutorial.
A Stochastic Finite-State Word-Segmentation Algorithm for Chinese
May 05, 1994
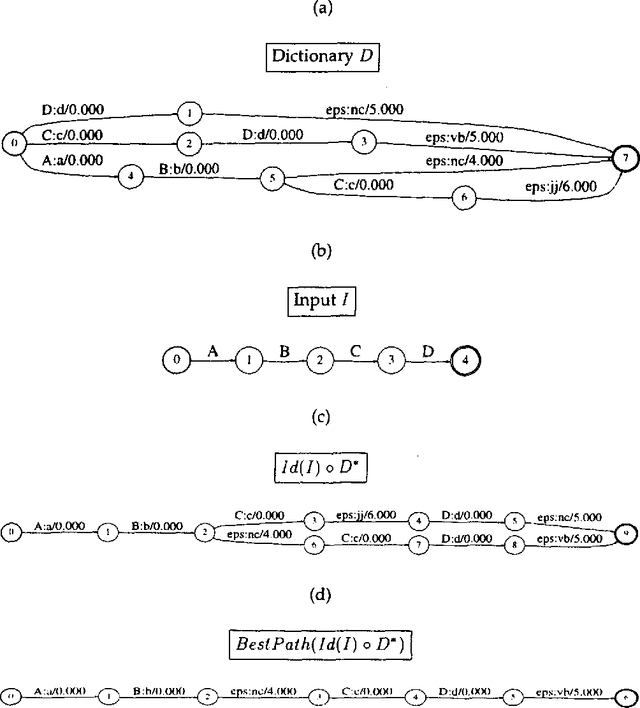
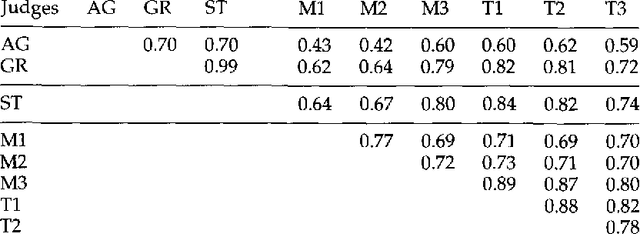
We present a stochastic finite-state model for segmenting Chinese text into dictionary entries and productively derived words, and providing pronunciations for these words; the method incorporates a class-based model in its treatment of personal names. We also evaluate the system's performance, taking into account the fact that people often do not agree on a single segmentation.
* To appear in Proceedings of ACL-94