 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss-sensitive Training of Probabilistic Conditional Random Fields
Jul 09, 2011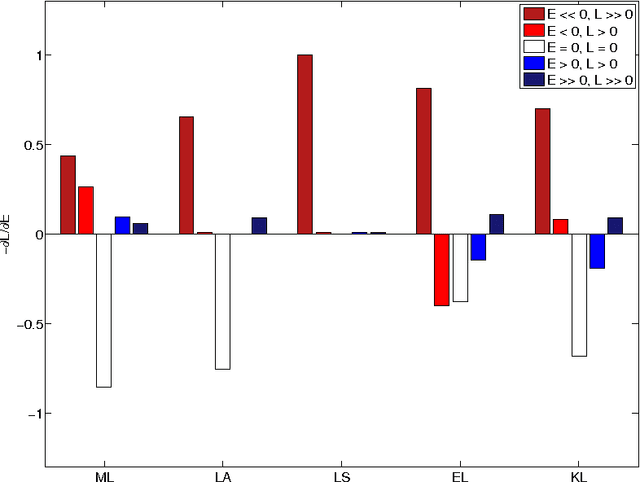
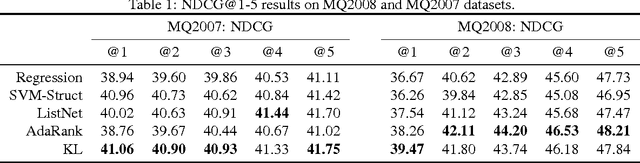
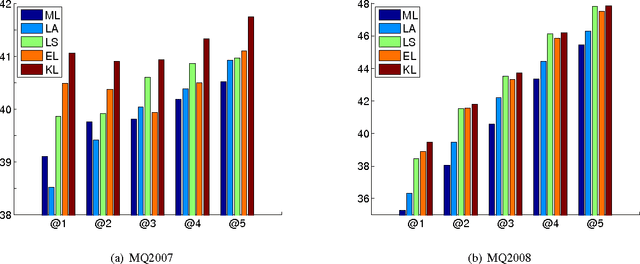
We consider the problem of training probabilistic conditional random fields (CRFs) in the context of a task where performance is measured using a specific loss function. While maximum likelihood is the most common approach to training CRFs, it ignores the inherent structure of the task's loss function. We describe alternatives to maximum likelihood which take that loss into account. These include a novel adaptation of a loss upper bound from the structured SVMs literature to the CRF context, as well as a new loss-inspired KL divergence objective which relies on the probabilistic nature of CRFs. These loss-sensitive objectives are compared to maximum likelihood using ranking as a benchmark task. This comparison confirms the importance of incorporating loss information in the probabilistic training of CRFs, with the loss-inspired KL outperforming all other objectives.
Ranking via Sinkhorn Propagation
Jun 14, 2011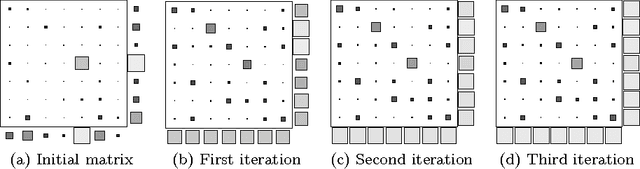
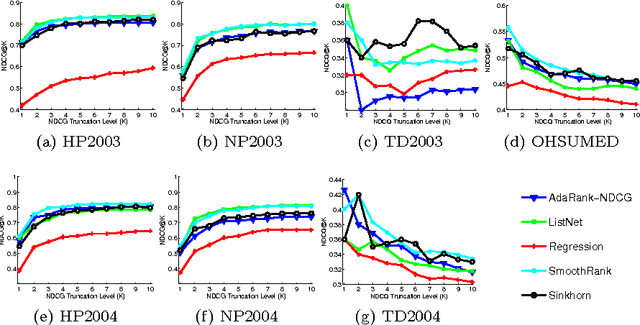
It is of increasing importance to develop learning methods for ranking. In contrast to many learning objectives, however, the ranking problem presents difficulties due to the fact that the space of permutations is not smooth. In this paper, we examine the class of rank-linear objective functions, which includes popular metrics such as precision and discounted cumulative gain. In particular, we observe that expectations of these gains are completely characterized by the marginals of the corresponding distribution over permutation matrices. Thus, the expectations of rank-linear objectives can always be described through locations in the Birkhoff polytope, i.e., doubly-stochastic matrices (DSMs). We propose a technique for learning DSM-based ranking functions using an iterative projection operator known as Sinkhorn normalization. Gradients of this operator can be computed via backpropagation, resulting in an algorithm we call Sinkhorn propagation, or SinkProp. This approach can be combined with a wide range of gradient-based approaches to rank learning. We demonstrate the utility of SinkProp on several information retrieval data sets.
Interpreting Graph Cuts as a Max-Product Algorithm
May 05, 2011
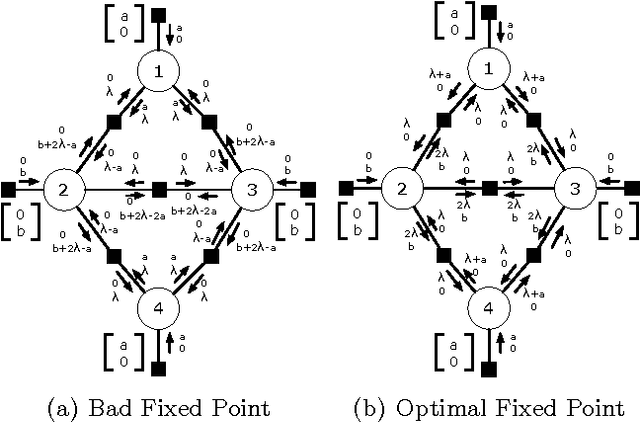
The maximum a posteriori (MAP) configuration of binary variable models with submodular graph-structured energy functions can be found efficiently and exactly by graph cuts. Max-product belief propagation (MP) has been shown to be suboptimal on this class of energy functions by a canonical counterexample where MP converges to a suboptimal fixed point (Kulesza & Pereira, 2008). In this work, we show that under a particular scheduling and damping scheme, MP is equivalent to graph cuts, and thus optimal. We explain the apparent contradiction by showing that with proper scheduling and damping, MP always converges to an optimal fixed point. Thus, the canonical counterexample only shows the suboptimality of MP with a particular suboptimal choice of schedule and damping. With proper choices, MP is optimal.