 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-variates++: more pluses in the k-means++
Feb 13, 2016



k-means++ seeding has become a de facto standard for hard clustering algorithms. In this paper, our first contribution is a two-way generalisation of this seeding, k-variates++, that includes the sampling of general densities rather than just a discrete set of Dirac densities anchored at the point locations, and a generalisation of the well known Arthur-Vassilvitskii (AV) approximation guarantee, in the form of a bias+variance approximation bound of the global optimum. This approximation exhibits a reduced dependency on the "noise" component with respect to the optimal potential --- actually approaching the statistical lower bound. We show that k-variates++ reduces to efficient (biased seeding) clustering algorithms tailored to specific frameworks; these include distributed, streaming and on-line clustering, with direct approximation results for these algorithms. Finally, we present a novel application of k-variates++ to differential privacy. For either the specific frameworks considered here, or for the differential privacy setting, there is little to no prior results on the direct application of k-means++ and its approximation bounds --- state of the art contenders appear to be significantly more complex and / or display less favorable (approximation) properties. We stress that our algorithms can still be run in cases where there is \textit{no} closed form solution for the population minimizer. We demonstrate the applicability of our analysis via experimental evaluation on several domains and settings, displaying competitive performances vs state of the art.
Learning Games and Rademacher Observations Losses
Feb 13, 2016



It has recently been shown that supervised learning with the popular logistic loss is equivalent to optimizing the exponential loss over sufficient statistics about the class: Rademacher observations (rados). We first show that this unexpected equivalence can actually be generalized to other example / rado losses, with necessary and sufficient conditions for the equivalence, exemplified on four losses that bear popular names in various fields: exponential (boosting), mean-variance (finance), Linear Hinge (on-line learning), ReLU (deep learning), and unhinged (statistics). Second, we show that the generalization unveils a surprising new connection to regularized learning, and in particular a sufficient condition under which regularizing the loss over examples is equivalent to regularizing the rados (with Minkowski sums) in the equivalent rado loss. This brings simple and powerful rado-based learning algorithms for sparsity-controlling regularization, that we exemplify on a boosting algorithm for the regularized exponential rado-loss, which formally boosts over four types of regularization, including the popular ridge and lasso, and the recently coined slope --- we obtain the first proven boosting algorithm for this last regularization. Through our first contribution on the equivalence of rado and example-based losses, Omega-R.AdaBoost~appears to be an efficient proxy to boost the regularized logistic loss over examples using whichever of the four regularizers. Experiments display that regularization consistently improves performances of rado-based learning, and may challenge or beat the state of the art of example-based learning even when learning over small sets of rados. Finally, we connect regularization to differential privacy, and display how tiny budgets can be afforded on big domains while beating (protected) example-based learning.
Loss factorization, weakly supervised learning and label noise robustness
Feb 09, 2016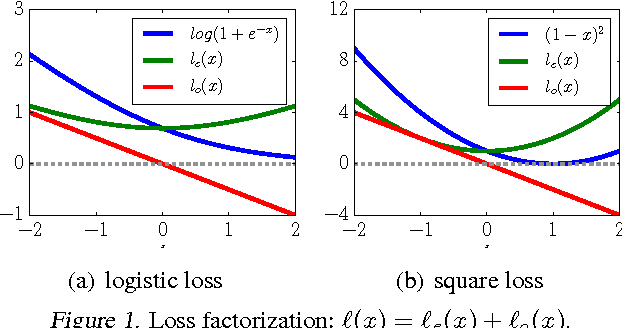
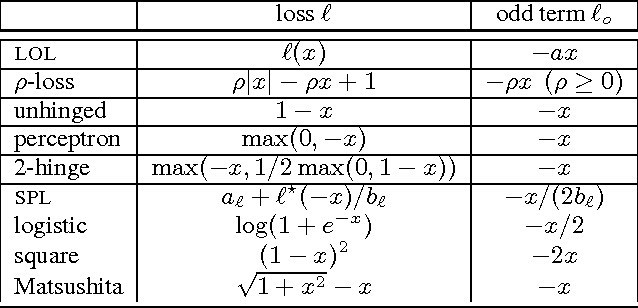
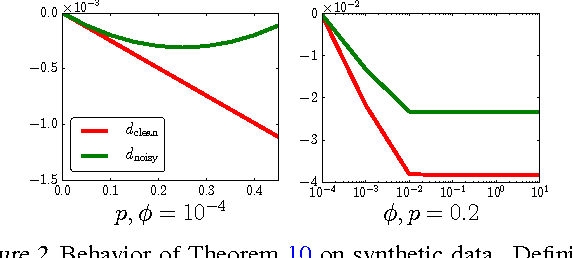
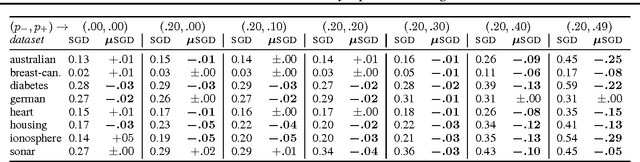
We prove that the empirical risk of most well-known loss functions factors into a linear term aggregating all labels with a term that is label free, and can further be expressed by sums of the loss. This holds true even for non-smooth, non-convex losses and in any RKHS. The first term is a (kernel) mean operator --the focal quantity of this work-- which we characterize as the sufficient statistic for the labels. The result tightens known generalization bounds and sheds new light on their interpretation. Factorization has a direct application on weakly supervised learning. In particular, we demonstrate that algorithms like SGD and proximal methods can be adapted with minimal effort to handle weak supervision, once the mean operator has been estimated. We apply this idea to learning with asymmetric noisy labels, connecting and extending prior work. Furthermore, we show that most losses enjoy a data-dependent (by the mean operator) form of noise robustness, in contrast with known negative results.
Rademacher Observations, Private Data, and Boosting
Apr 02, 2015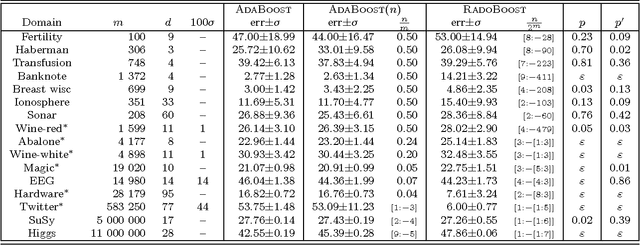
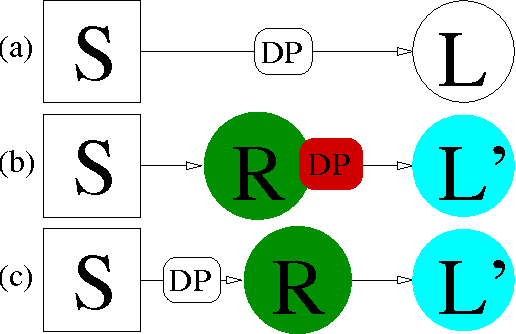
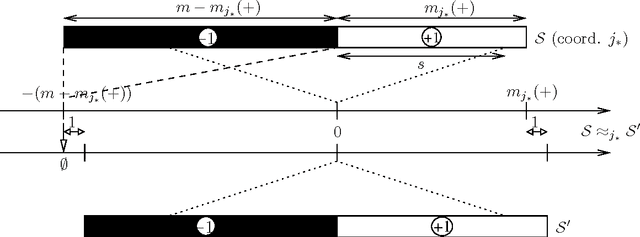
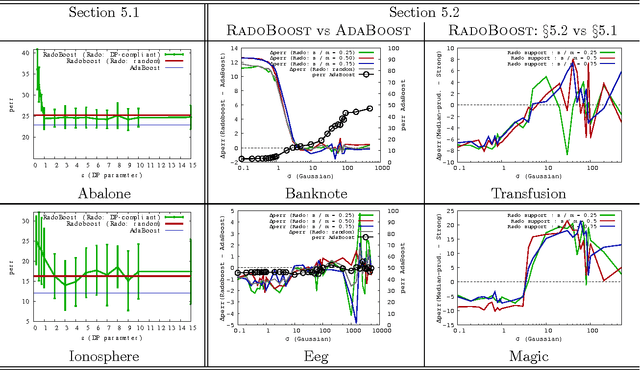
The minimization of the logistic loss is a popular approach to batch supervised learning. Our paper starts from the surprising observation that, when fitting linear (or kernelized) classifiers, the minimization of the logistic loss is \textit{equivalent} to the minimization of an exponential \textit{rado}-loss computed (i) over transformed data that we call Rademacher observations (rados), and (ii) over the \textit{same} classifier as the one of the logistic loss. Thus, a classifier learnt from rados can be \textit{directly} used to classify \textit{observations}. We provide a learning algorithm over rados with boosting-compliant convergence rates on the \textit{logistic loss} (computed over examples). Experiments on domains with up to millions of examples, backed up by theoretical arguments, display that learning over a small set of random rados can challenge the state of the art that learns over the \textit{complete} set of examples. We show that rados comply with various privacy requirements that make them good candidates for machine learning in a privacy framework. We give several algebraic, geometric and computational hardness results on reconstructing examples from rados. We also show how it is possible to craft, and efficiently learn from, rados in a differential privacy framework. Tests reveal that learning from differentially private rados can compete with learning from random rados, and hence with batch learning from examples, achieving non-trivial privacy vs accuracy tradeoffs.
Further heuristics for $k$-means: The merge-and-split heuristic and the $$-means
Jun 23, 2014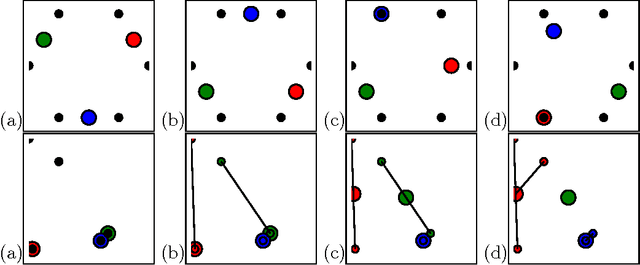
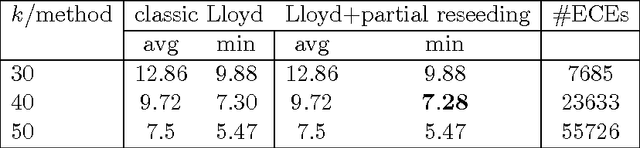
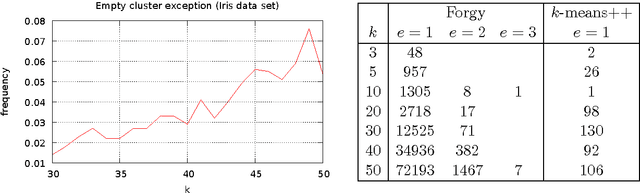
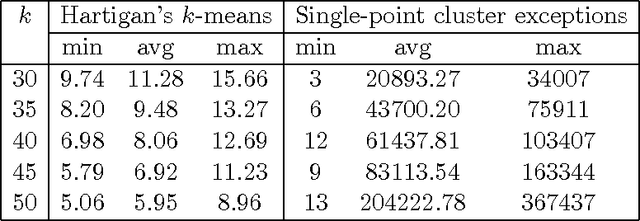
Finding the optimal $k$-means clustering is NP-hard in general and many heuristics have been designed for minimizing monotonically the $k$-means objective. We first show how to extend Lloyd's batched relocation heuristic and Hartigan's single-point relocation heuristic to take into account empty-cluster and single-point cluster events, respectively. Those events tend to increasingly occur when $k$ or $d$ increases, or when performing several restarts. First, we show that those special events are a blessing because they allow to partially re-seed some cluster centers while further minimizing the $k$-means objective function. Second, we describe a novel heuristic, merge-and-split $k$-means, that consists in merging two clusters and splitting this merged cluster again with two new centers provided it improves the $k$-means objective. This novel heuristic can improve Hartigan's $k$-means when it has converged to a local minimum. We show empirically that this merge-and-split $k$-means improves over the Hartigan's heuristic which is the {\em de facto} method of choice. Finally, we propose the $(k,l)$-means objective that generalizes the $k$-means objective by associating the data points to their $l$ closest cluster centers, and show how to either directly convert or iteratively relax the $(k,l)$-means into a $k$-means in order to reach better local minima.
Optimal interval clustering: Application to Bregman clustering and statistical mixture learning
May 26, 2014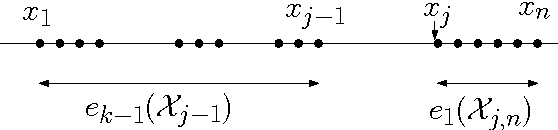
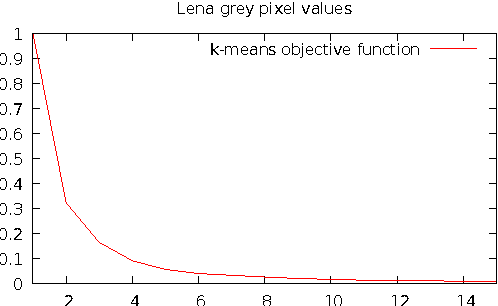
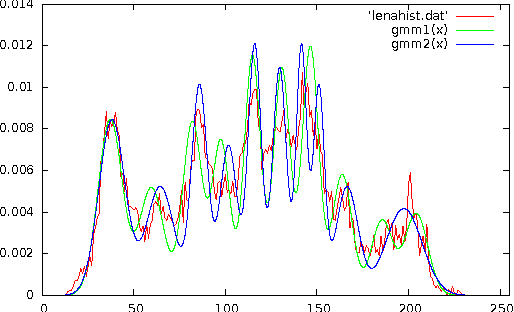
We present a generic dynamic programming method to compute the optimal clustering of $n$ scalar elements into $k$ pairwise disjoint intervals. This case includes 1D Euclidean $k$-means, $k$-medoids, $k$-medians, $k$-centers, etc. We extend the method to incorporate cluster size constraints and show how to choose the appropriate $k$ by model selection. Finally, we illustrate and refine the method on two case studies: Bregman clustering and statistical mixture learning maximizing the complete likelihood.
Combining Feature and Prototype Pruning by Uncertainty Minimization
Jan 16, 2013
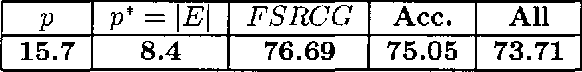

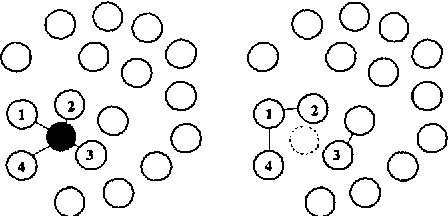
We focus in this paper on dataset reduction techniques for use in k-nearest neighbor classification. In such a context, feature and prototype selections have always been independently treated by the standard storage reduction algorithms. While this certifying is theoretically justified by the fact that each subproblem is NP-hard, we assume in this paper that a joint storage reduction is in fact more intuitive and can in practice provide better results than two independent processes. Moreover, it avoids a lot of distance calculations by progressively removing useless instances during the feature pruning. While standard selection algorithms often optimize the accuracy to discriminate the set of solutions, we use in this paper a criterion based on an uncertainty measure within a nearest-neighbor graph. This choice comes from recent results that have proven that accuracy is not always the suitable criterion to optimize. In our approach, a feature or an instance is removed if its deletion improves information of the graph. Numerous experiments are presented in this paper and a statistical analysis shows the relevance of our approach, and its tolerance in the presence of noise.
On Rényi and Tsallis entropies and divergences for exponential families
May 17, 2011Many common probability distributions in statistics like the Gaussian, multinomial, Beta or Gamma distributions can be studied under the unified framework of exponential families. In this paper, we prove that both R\'enyi and Tsallis divergences of distributions belonging to the same exponential family admit a generic closed form expression. Furthermore, we show that R\'enyi and Tsallis entropies can also be calculated in closed-form for sub-families including the Gaussian or exponential distributions, among others.
* 7 pages
Boosting k-NN for categorization of natural scenes
Jan 08, 2010


The k-nearest neighbors (k-NN) classification rule has proven extremely successful in countless many computer vision applications. For example, image categorization often relies on uniform voting among the nearest prototypes in the space of descriptors. In spite of its good properties, the classic k-NN rule suffers from high variance when dealing with sparse prototype datasets in high dimensions. A few techniques have been proposed to improve k-NN classification, which rely on either deforming the nearest neighborhood relationship or modifying the input space. In this paper, we propose a novel boosting algorithm, called UNN (Universal Nearest Neighbors), which induces leveraged k-NN, thus generalizing the classic k-NN rule. We redefine the voting rule as a strong classifier that linearly combines predictions from the k closest prototypes. Weak classifiers are learned by UNN so as to minimize a surrogate risk. A major feature of UNN is the ability to learn which prototypes are the most relevant for a given class, thus allowing one for effective data reduction. Experimental results on the synthetic two-class dataset of Ripley show that such a filtering strategy is able to reject "noisy" prototypes. We carried out image categorization experiments on a database containing eight classes of natural scenes. We show that our method outperforms significantly the classic k-NN classification, while enabling significant reduction of the computational cost by means of data filtering.
Soft Uncoupling of Markov Chains for Permeable Language Distinction: A New Algorithm
Oct 07, 2008


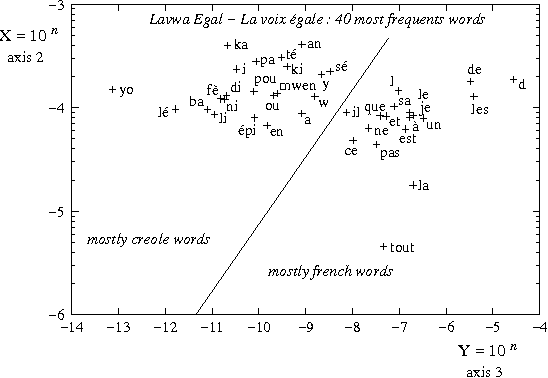
Without prior knowledge, distinguishing different languages may be a hard task, especially when their borders are permeable. We develop an extension of spectral clustering -- a powerful unsupervised classification toolbox -- that is shown to resolve accurately the task of soft language distinction. At the heart of our approach, we replace the usual hard membership assignment of spectral clustering by a soft, probabilistic assignment, which also presents the advantage to bypass a well-known complexity bottleneck of the method. Furthermore, our approach relies on a novel, convenient construction of a Markov chain out of a corpus. Extensive experiments with a readily available system clearly display the potential of the method, which brings a visually appealing soft distinction of languages that may define altogether a whole corpus.
* 6 pages, 7 embedded figures, LaTeX 2e using the ecai2006.cls document class and the algorithm2e.sty style file (+ standard packages like epsfig, amsmath, amssymb, amsfonts...). Extends the short version contained in the ECAI 2006 proceedings