 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoiler Alert: Narrative Forecasting as a Metric for Tension in LLM Storytelling
Apr 10, 2026LLMs have so far failed both to generate consistently compelling stories and to recognize this failure--on the leading creative-writing benchmark (EQ-Bench), LLM judges rank zero-shot AI stories above New Yorker short stories, a gold standard for literary fiction. We argue that existing rubrics overlook a key dimension of compelling human stories: narrative tension. We introduce the 100-Endings metric, which walks through a story sentence by sentence: at each position, a model predicts how the story will end 100 times given only the text so far, and we measure tension as how often predictions fail to match the ground truth. Beyond the mismatch rate, the sentence-level curve yields complementary statistics, such as inflection rate, a geometric measure of how frequently the curve reverses direction, tracking twists and revelations. Unlike rubric-based judges, 100-Endings correctly ranks New Yorker stories far above LLM outputs. Grounded in narratological principles, we design a story-generation pipeline using structural constraints, including analysis of story templates, idea formulation, and narrative scaffolding. Our pipeline significantly increases narrative tension as measured by the 100-Endings metric, while maintaining performance on the EQ-Bench leaderboard.
Generative AI & Fictionality: How Novels Power Large Language Models
Mar 01, 2026Generative models, like the one in ChatGPT, are powered by their training data. The models are simply next-word predictors, based on patterns learned from vast amounts of pre-existing text. Since the first generation of GPT, it is striking that the most popular datasets have included substantial collections of novels. For the engineers and research scientists who build these models, there is a common belief that the language in fiction is rich enough to cover all manner of social and communicative phenomena, yet the belief has gone mostly unexamined. How does fiction shape the outputs of generative AI? Specifically, what are novels' effects relative to other forms of text, such as newspapers, Reddit, and Wikipedia? Since the 1970s, literature scholars such as Catherine Gallagher and James Phelan have developed robust and insightful accounts of how fiction operates as a form of discourse and language. Through our study of an influential open-source model (BERT), we find that LLMs leverage familiar attributes and affordances of fiction, while also fomenting new qualities and forms of social response. We argue that if contemporary culture is increasingly shaped by generative AI and machine learning, any analysis of today's various modes of cultural production must account for a relatively novel dimension: computational training data.
Critical Confabulation: Can LLMs Hallucinate for Social Good?
Nov 11, 2025LLMs hallucinate, yet some confabulations can have social affordances if carefully bounded. We propose critical confabulation (inspired by critical fabulation from literary and social theory), the use of LLM hallucinations to "fill-in-the-gap" for omissions in archives due to social and political inequality, and reconstruct divergent yet evidence-bound narratives for history's "hidden figures". We simulate these gaps with an open-ended narrative cloze task: asking LLMs to generate a masked event in a character-centric timeline sourced from a novel corpus of unpublished texts. We evaluate audited (for data contamination), fully-open models (the OLMo-2 family) and unaudited open-weight and proprietary baselines under a range of prompts designed to elicit controlled and useful hallucinations. Our findings validate LLMs' foundational narrative understanding capabilities to perform critical confabulation, and show how controlled and well-specified hallucinations can support LLM applications for knowledge production without collapsing speculation into a lack of historical accuracy and fidelity.
KRISTEVA: Close Reading as a Novel Task for Benchmarking Interpretive Reasoning
May 14, 2025Each year, tens of millions of essays are written and graded in college-level English courses. Students are asked to analyze literary and cultural texts through a process known as close reading, in which they gather textual details to formulate evidence-based arguments. Despite being viewed as a basis for critical thinking and widely adopted as a required element of university coursework, close reading has never been evaluated on large language models (LLMs), and multi-discipline benchmarks like MMLU do not include literature as a subject. To fill this gap, we present KRISTEVA, the first close reading benchmark for evaluating interpretive reasoning, consisting of 1331 multiple-choice questions adapted from classroom data. With KRISTEVA, we propose three progressively more difficult sets of tasks to approximate different elements of the close reading process, which we use to test how well LLMs may seem to understand and reason about literary works: 1) extracting stylistic features, 2) retrieving relevant contextual information from parametric knowledge, and 3) multi-hop reasoning between style and external contexts. Our baseline results find that, while state-of-the-art LLMs possess some college-level close reading competency (accuracy 49.7% - 69.7%), their performances still trail those of experienced human evaluators on 10 out of our 11 tasks.
Confabulation: The Surprising Value of Large Language Model Hallucinations
Jun 06, 2024This paper presents a systematic defense of large language model (LLM) hallucinations or 'confabulations' as a potential resource instead of a categorically negative pitfall. The standard view is that confabulations are inherently problematic and AI research should eliminate this flaw. In this paper, we argue and empirically demonstrate that measurable semantic characteristics of LLM confabulations mirror a human propensity to utilize increased narrativity as a cognitive resource for sense-making and communication. In other words, it has potential value. Specifically, we analyze popular hallucination benchmarks and reveal that hallucinated outputs display increased levels of narrativity and semantic coherence relative to veridical outputs. This finding reveals a tension in our usually dismissive understandings of confabulation. It suggests, counter-intuitively, that the tendency for LLMs to confabulate may be intimately associated with a positive capacity for coherent narrative-text generation.
Fast, Flexible Models for Discovering Topic Correlation across Weakly-Related Collections
Aug 19, 2015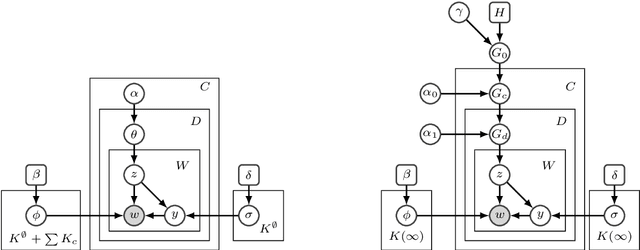
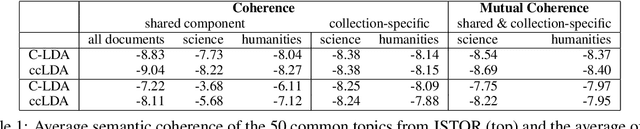
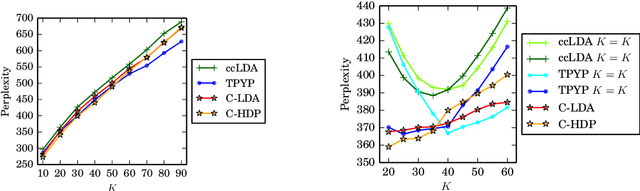

Weak topic correlation across document collections with different numbers of topics in individual collections presents challenges for existing cross-collection topic models. This paper introduces two probabilistic topic models, Correlated LDA (C-LDA) and Correlated HDP (C-HDP). These address problems that can arise when analyzing large, asymmetric, and potentially weakly-related collections. Topic correlations in weakly-related collections typically lie in the tail of the topic distribution, where they would be overlooked by models unable to fit large numbers of topics. To efficiently model this long tail for large-scale analysis, our models implement a parallel sampling algorithm based on the Metropolis-Hastings and alias methods (Yuan et al., 2015). The models are first evaluated on synthetic data, generated to simulate various collection-level asymmetries. We then present a case study of modeling over 300k documents in collections of sciences and humanities research from JSTOR.