 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective evolutionary GAN for tabular data synthesis
Apr 15, 2024



Synthetic data has a key role to play in data sharing by statistical agencies and other generators of statistical data products. Generative Adversarial Networks (GANs), typically applied to image synthesis, are also a promising method for tabular data synthesis. However, there are unique challenges in tabular data compared to images, eg tabular data may contain both continuous and discrete variables and conditional sampling, and, critically, the data should possess high utility and low disclosure risk (the risk of re-identifying a population unit or learning something new about them), providing an opportunity for multi-objective (MO) optimization. Inspired by MO GANs for images, this paper proposes a smart MO evolutionary conditional tabular GAN (SMOE-CTGAN). This approach models conditional synthetic data by applying conditional vectors in training, and uses concepts from MO optimisation to balance disclosure risk against utility. Our results indicate that SMOE-CTGAN is able to discover synthetic datasets with different risk and utility levels for multiple national census datasets. We also find a sweet spot in the early stage of training where a competitive utility and extremely low risk are achieved, by using an Improvement Score. The full code can be downloaded from https://github.com/HuskyNian/SMO\_EGAN\_pytorch.
Model-agnostic variable importance for predictive uncertainty: an entropy-based approach
Oct 19, 2023



In order to trust the predictions of a machine learning algorithm, it is necessary to understand the factors that contribute to those predictions. In the case of probabilistic and uncertainty-aware models, it is necessary to understand not only the reasons for the predictions themselves, but also the model's level of confidence in those predictions. In this paper, we show how existing methods in explainability can be extended to uncertainty-aware models and how such extensions can be used to understand the sources of uncertainty in a model's predictive distribution. In particular, by adapting permutation feature importance, partial dependence plots, and individual conditional expectation plots, we demonstrate that novel insights into model behaviour may be obtained and that these methods can be used to measure the impact of features on both the entropy of the predictive distribution and the log-likelihood of the ground truth labels under that distribution. With experiments using both synthetic and real-world data, we demonstrate the utility of these approaches in understanding both the sources of uncertainty and their impact on model performance.
Analysis of modular CMA-ES on strict box-constrained problems in the SBOX-COST benchmarking suite
May 24, 2023



Box-constraints limit the domain of decision variables and are common in real-world optimization problems, for example, due to physical, natural or spatial limitations. Consequently, solutions violating a box-constraint may not be evaluable. This assumption is often ignored in the literature, e.g., existing benchmark suites, such as COCO/BBOB, allow the optimizer to evaluate infeasible solutions. This paper presents an initial study on the strict-box-constrained benchmarking suite (SBOX-COST), which is a variant of the well-known BBOB benchmark suite that enforces box-constraints by returning an invalid evaluation value for infeasible solutions. Specifically, we want to understand the performance difference between BBOB and SBOX-COST as a function of two initialization methods and six constraint-handling strategies all tested with modular CMA-ES. We find that, contrary to what may be expected, handling box-constraints by saturation is not always better than not handling them at all. However, across all BBOB functions, saturation is better than not handling, and the difference increases with the number of dimensions. Strictly enforcing box-constraints also has a clear negative effect on the performance of classical CMA-ES (with uniform random initialization and no constraint handling), especially as problem dimensionality increases.
Applying Ising Machines to Multi-objective QUBOs
May 19, 2023



Multi-objective optimisation problems involve finding solutions with varying trade-offs between multiple and often conflicting objectives. Ising machines are physical devices that aim to find the absolute or approximate ground states of an Ising model. To apply Ising machines to multi-objective problems, a weighted sum objective function is used to convert multi-objective into single-objective problems. However, deriving scalarisation weights that archives evenly distributed solutions across the Pareto front is not trivial. Previous work has shown that adaptive weights based on dichotomic search, and one based on averages of previously explored weights can explore the Pareto front quicker than uniformly generated weights. However, these adaptive methods have only been applied to bi-objective problems in the past. In this work, we extend the adaptive method based on averages in two ways: (i)~we extend the adaptive method of deriving scalarisation weights for problems with two or more objectives, and (ii)~we use an alternative measure of distance to improve performance. We compare the proposed method with existing ones and show that it leads to the best performance on multi-objective Unconstrained Binary Quadratic Programming (mUBQP) instances with 3 and 4 objectives and that it is competitive with the best one for instances with 2 objectives.
A Study of Scalarisation Techniques for Multi-Objective QUBO Solving
Oct 20, 2022
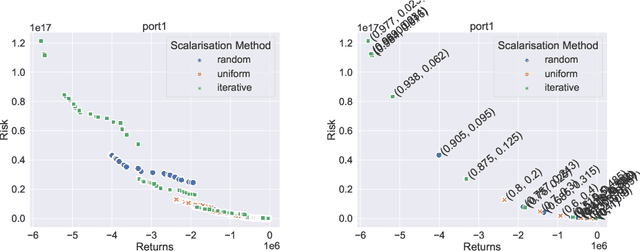
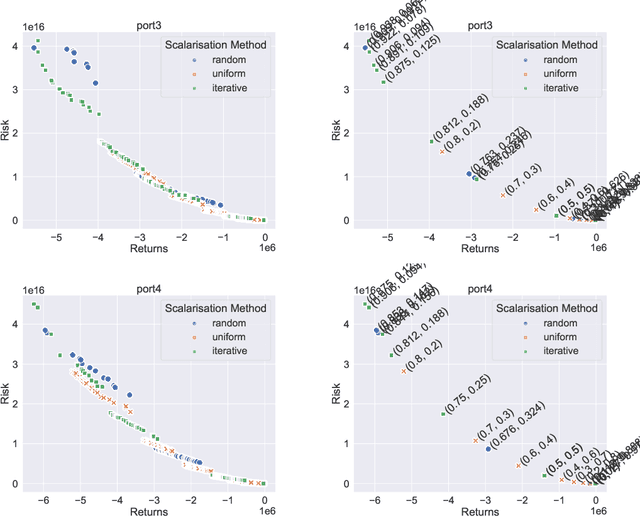
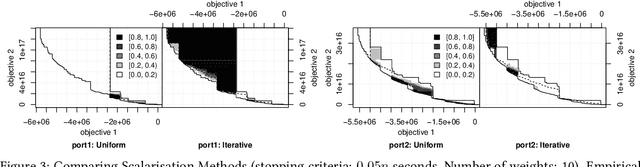
In recent years, there has been significant research interest in solving Quadratic Unconstrained Binary Optimisation (QUBO) problems. Physics-inspired optimisation algorithms have been proposed for deriving optimal or sub-optimal solutions to QUBOs. These methods are particularly attractive within the context of using specialised hardware, such as quantum computers, application specific CMOS and other high performance computing resources for solving optimisation problems. These solvers are then applied to QUBO formulations of combinatorial optimisation problems. Quantum and quantum-inspired optimisation algorithms have shown promising performance when applied to academic benchmarks as well as real-world problems. However, QUBO solvers are single objective solvers. To make them more efficient at solving problems with multiple objectives, a decision on how to convert such multi-objective problems to single-objective problems need to be made. In this study, we compare methods of deriving scalarisation weights when combining two objectives of the cardinality constrained mean-variance portfolio optimisation problem into one. We show significant performance improvement (measured in terms of hypervolume) when using a method that iteratively fills the largest space in the Pareto front compared to a n\"aive approach using uniformly generated weights.
Comparing the Utility and Disclosure Risk of Synthetic Data with Samples of Microdata
Jul 02, 2022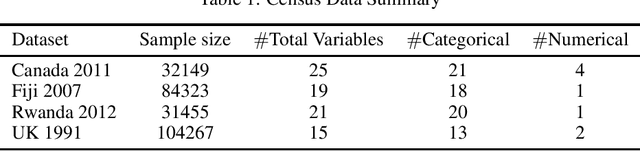
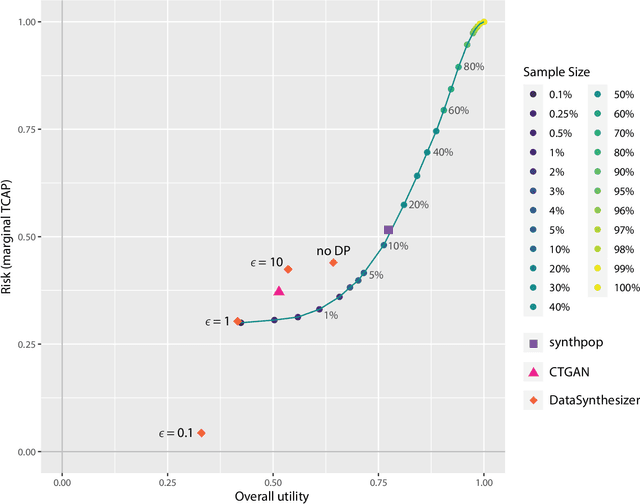
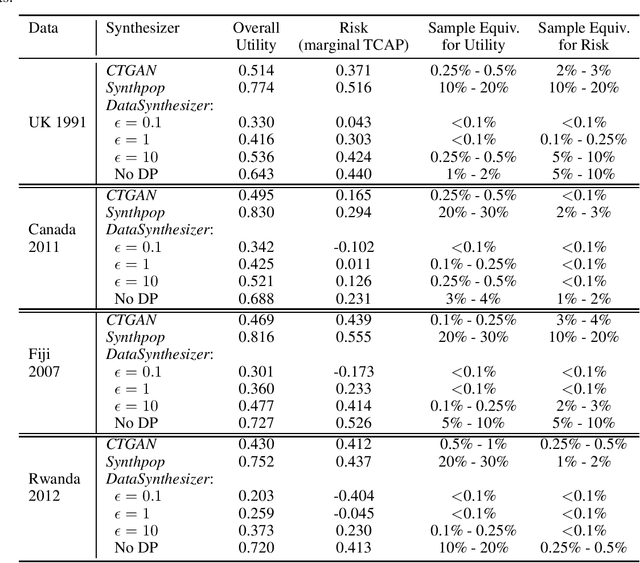
Most statistical agencies release randomly selected samples of Census microdata, usually with sample fractions under 10% and with other forms of statistical disclosure control (SDC) applied. An alternative to SDC is data synthesis, which has been attracting growing interest, yet there is no clear consensus on how to measure the associated utility and disclosure risk of the data. The ability to produce synthetic Census microdata, where the utility and associated risks are clearly understood, could mean that more timely and wider-ranging access to microdata would be possible. This paper follows on from previous work by the authors which mapped synthetic Census data on a risk-utility (R-U) map. The paper presents a framework to measure the utility and disclosure risk of synthetic data by comparing it to samples of the original data of varying sample fractions, thereby identifying the sample fraction which has equivalent utility and risk to the synthetic data. Three commonly used data synthesis packages are compared with some interesting results. Further work is needed in several directions but the methodology looks very promising.
Combining Topic Modeling with Grounded Theory: Case Studies of Project Collaboration
Jun 28, 2022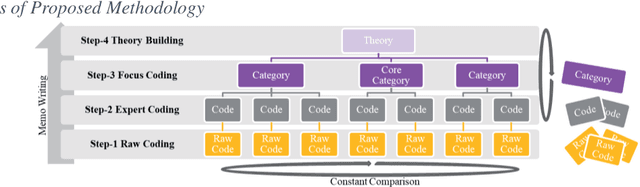
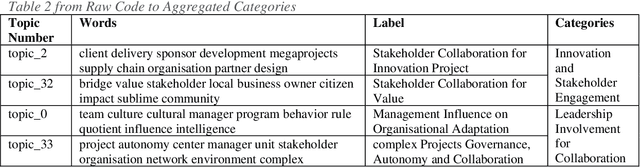
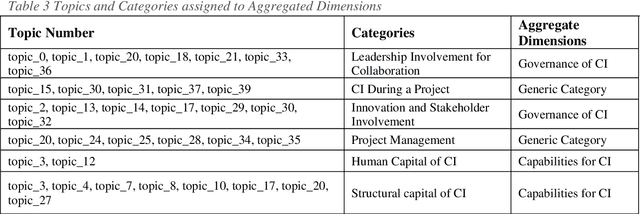
This paper proposes an Artificial Intelligence (AI) Grounded Theory for management studies. We argue that this novel and rigorous approach that embeds topic modelling will lead to the latent knowledge to be found. We illustrate this abductive method using 51 case studies of collaborative innovation published by Project Management Institute (PMI). Initial results are presented and discussed that include 40 topics, 6 categories, 4 of which are core categories, and two new theories of project collaboration.
Cooperative Multi-Agent Search on Endogenously-Changing Fitness Landscapes
Jun 28, 2022
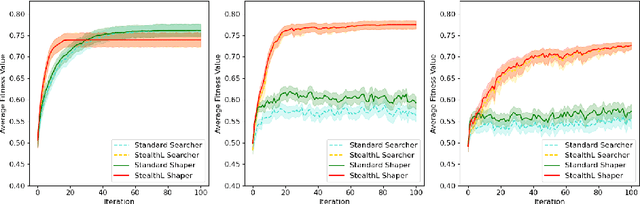
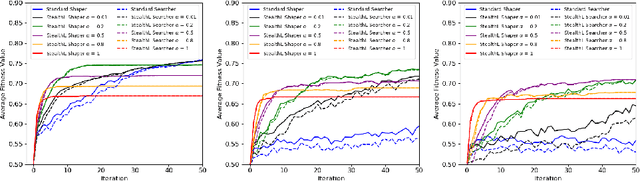
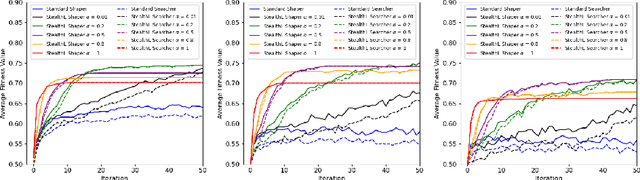
We use a multi-agent system to model how agents (representing firms) may collaborate and adapt in a business 'landscape' where some, more influential, firms are given the power to shape the landscape of other firms. The landscapes we study are based on the well-known NK model of Kauffman, with the addition of 'shapers', firms that can change the landscape's features for themselves and all other players. Our work investigates how firms that are additionally endowed with cognitive and experiential search, and the ability to form collaborations with other firms, can use these capabilities to adapt more quickly and adeptly. We find that, in a collaborative group, firms must still have a mind of their own and resist direct mimicry of stronger partners to attain better heights collectively. Larger groups and groups with more influential members generally do better, so targeted intelligent cooperation is beneficial. These conclusions are tentative, and our results show a sensitivity to landscape ruggedness and "malleability" (i.e. the capacity of the landscape to be changed by the shaper firms). Overall, our work demonstrates the potential of computer science, evolution, and machine learning to contribute to business strategy in these complex environments.
Efficient Approximation of Expected Hypervolume Improvement using Gauss-Hermite Quadrature
Jun 15, 2022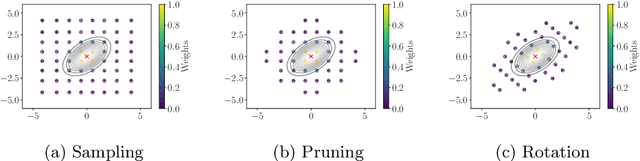
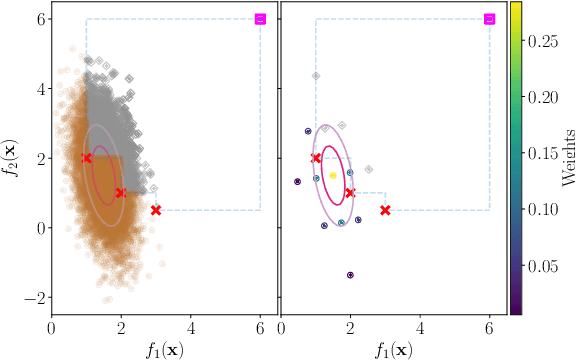
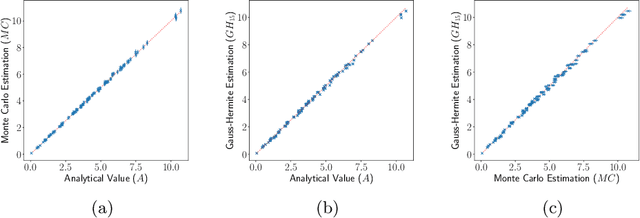
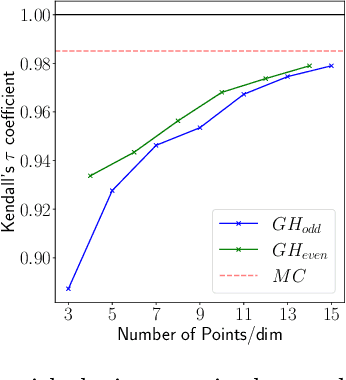
Many methods for performing multi-objective optimisation of computationally expensive problems have been proposed recently. Typically, a probabilistic surrogate for each objective is constructed from an initial dataset. The surrogates can then be used to produce predictive densities in the objective space for any solution. Using the predictive densities, we can compute the expected hypervolume improvement (EHVI) due to a solution. Maximising the EHVI, we can locate the most promising solution that may be expensively evaluated next. There are closed-form expressions for computing the EHVI, integrating over the multivariate predictive densities. However, they require partitioning the objective space, which can be prohibitively expensive for more than three objectives. Furthermore, there are no closed-form expressions for a problem where the predictive densities are dependent, capturing the correlations between objectives. Monte Carlo approximation is used instead in such cases, which is not cheap. Hence, the need to develop new accurate but cheaper approximation methods remains. Here we investigate an alternative approach toward approximating the EHVI using Gauss-Hermite quadrature. We show that it can be an accurate alternative to Monte Carlo for both independent and correlated predictive densities with statistically significant rank correlations for a range of popular test problems.
Multi-objective QUBO Solver: Bi-objective Quadratic Assignment
May 26, 2022
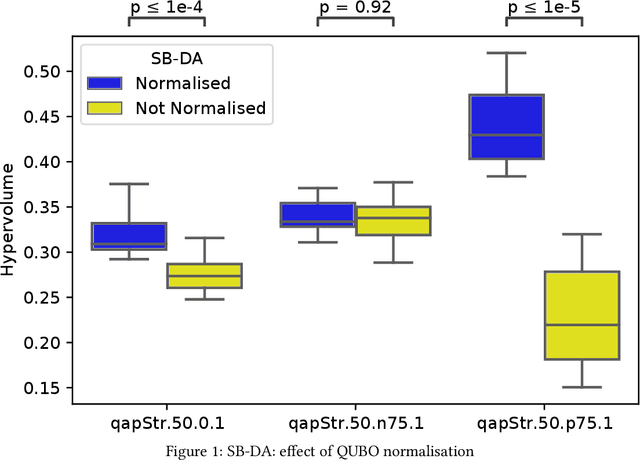
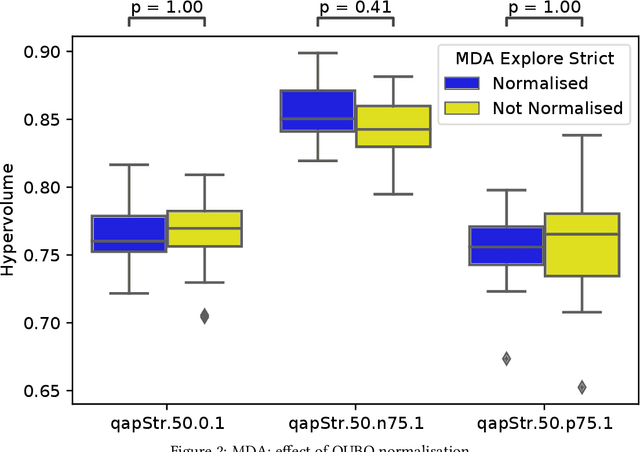

Quantum and quantum-inspired optimisation algorithms are designed to solve problems represented in binary, quadratic and unconstrained form. Combinatorial optimisation problems are therefore often formulated as Quadratic Unconstrained Binary Optimisation Problems (QUBO) to solve them with these algorithms. Moreover, these QUBO solvers are often implemented using specialised hardware to achieve enormous speedups, e.g. Fujitsu's Digital Annealer (DA) and D-Wave's Quantum Annealer. However, these are single-objective solvers, while many real-world problems feature multiple conflicting objectives. Thus, a common practice when using these QUBO solvers is to scalarise such multi-objective problems into a sequence of single-objective problems. Due to design trade-offs of these solvers, formulating each scalarisation may require more time than finding a local optimum. We present the first attempt to extend the algorithm supporting a commercial QUBO solver as a multi-objective solver that is not based on scalarisation. The proposed multi-objective DA algorithm is validated on the bi-objective Quadratic Assignment Problem. We observe that algorithm performance significantly depends on the archiving strategy adopted, and that combining DA with non-scalarisation methods to optimise multiple objectives outperforms the current scalarised version of the DA in terms of final solution quality.