 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBLPLink: An Entity Linker for the DBLP Scholarly Knowledge Graph
Sep 25, 2023In this work, we present a web application named DBLPLink, which performs entity linking over the DBLP scholarly knowledge graph. DBLPLink uses text-to-text pre-trained language models, such as T5, to produce entity label spans from an input text question. Entity candidates are fetched from a database based on the labels, and an entity re-ranker sorts them based on entity embeddings, such as TransE, DistMult and ComplEx. The results are displayed so that users may compare and contrast the results between T5-small, T5-base and the different KG embeddings used. The demo can be accessed at https://ltdemos.informatik.uni-hamburg.de/dblplink/.
Biomedical Entity Linking with Triple-aware Pre-Training
Aug 28, 2023Linking biomedical entities is an essential aspect in biomedical natural language processing tasks, such as text mining and question answering. However, a difficulty of linking the biomedical entities using current large language models (LLM) trained on a general corpus is that biomedical entities are scarcely distributed in texts and therefore have been rarely seen during training by the LLM. At the same time, those LLMs are not aware of high level semantic connection between different biomedical entities, which are useful in identifying similar concepts in different textual contexts. To cope with aforementioned problems, some recent works focused on injecting knowledge graph information into LLMs. However, former methods either ignore the relational knowledge of the entities or lead to catastrophic forgetting. Therefore, we propose a novel framework to pre-train the powerful generative LLM by a corpus synthesized from a KG. In the evaluations we are unable to confirm the benefit of including synonym, description or relational information.
The Role of Output Vocabulary in T2T LMs for SPARQL Semantic Parsing
May 24, 2023



In this work, we analyse the role of output vocabulary for text-to-text (T2T) models on the task of SPARQL semantic parsing. We perform experiments within the the context of knowledge graph question answering (KGQA), where the task is to convert questions in natural language to the SPARQL query language. We observe that the query vocabulary is distinct from human vocabulary. Language Models (LMs) are pre-dominantly trained for human language tasks, and hence, if the query vocabulary is replaced with a vocabulary more attuned to the LM tokenizer, the performance of models may improve. We carry out carefully selected vocabulary substitutions on the queries and find absolute gains in the range of 17% on the GrailQA dataset.
DBLP-QuAD: A Question Answering Dataset over the DBLP Scholarly Knowledge Graph
Mar 29, 2023



In this work we create a question answering dataset over the DBLP scholarly knowledge graph (KG). DBLP is an on-line reference for bibliographic information on major computer science publications that indexes over 4.4 million publications published by more than 2.2 million authors. Our dataset consists of 10,000 question answer pairs with the corresponding SPARQL queries which can be executed over the DBLP KG to fetch the correct answer. DBLP-QuAD is the largest scholarly question answering dataset.
GETT-QA: Graph Embedding based T2T Transformer for Knowledge Graph Question Answering
Mar 28, 2023



In this work, we present an end-to-end Knowledge Graph Question Answering (KGQA) system named GETT-QA. GETT-QA uses T5, a popular text-to-text pre-trained language model. The model takes a question in natural language as input and produces a simpler form of the intended SPARQL query. In the simpler form, the model does not directly produce entity and relation IDs. Instead, it produces corresponding entity and relation labels. The labels are grounded to KG entity and relation IDs in a subsequent step. To further improve the results, we instruct the model to produce a truncated version of the KG embedding for each entity. The truncated KG embedding enables a finer search for disambiguation purposes. We find that T5 is able to learn the truncated KG embeddings without any change of loss function, improving KGQA performance. As a result, we report strong results for LC-QuAD 2.0 and SimpleQuestions-Wikidata datasets on end-to-end KGQA over Wikidata.
AmQA: Amharic Question Answering Dataset
Mar 06, 2023



Question Answering (QA) returns concise answers or answer lists from natural language text given a context document. Many resources go into curating QA datasets to advance robust models' development. There is a surge of QA datasets for languages like English, however, this is not true for Amharic. Amharic, the official language of Ethiopia, is the second most spoken Semitic language in the world. There is no published or publicly available Amharic QA dataset. Hence, to foster the research in Amharic QA, we present the first Amharic QA (AmQA) dataset. We crowdsourced 2628 question-answer pairs over 378 Wikipedia articles. Additionally, we run an XLMR Large-based baseline model to spark open-domain QA research interest. The best-performing baseline achieves an F-score of 69.58 and 71.74 in reader-retriever QA and reading comprehension settings respectively.
The Ethical Risks of Analyzing Crisis Events on Social Media with Machine Learning
Oct 07, 2022Social media platforms provide a continuous stream of real-time news regarding crisis events on a global scale. Several machine learning methods utilize the crowd-sourced data for the automated detection of crises and the characterization of their precursors and aftermaths. Early detection and localization of crisis-related events can help save lives and economies. Yet, the applied automation methods introduce ethical risks worthy of investigation - especially given their high-stakes societal context. This work identifies and critically examines ethical risk factors of social media analyses of crisis events focusing on machine learning methods. We aim to sensitize researchers and practitioners to the ethical pitfalls and promote fairer and more reliable designs.
The Lifecycle of "Facts": A Survey of Social Bias in Knowledge Graphs
Oct 07, 2022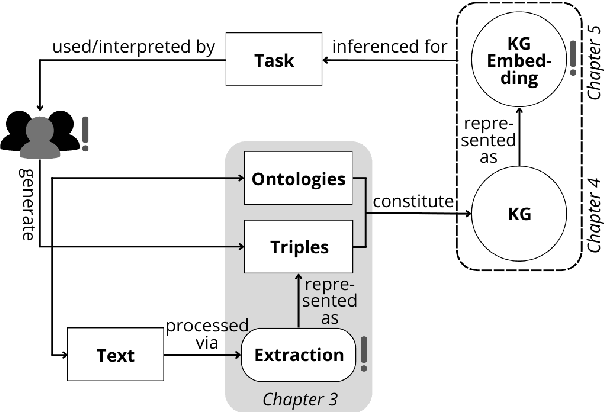
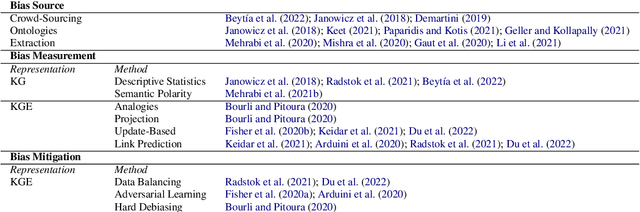
Knowledge graphs are increasingly used in a plethora of downstream tasks or in the augmentation of statistical models to improve factuality. However, social biases are engraved in these representations and propagate downstream. We conducted a critical analysis of literature concerning biases at different steps of a knowledge graph lifecycle. We investigated factors introducing bias, as well as the biases that are rendered by knowledge graphs and their embedded versions afterward. Limitations of existing measurement and mitigation strategies are discussed and paths forward are proposed.
Knowledge Graph Question Answering Datasets and Their Generalizability: Are They Enough for Future Research?
May 13, 2022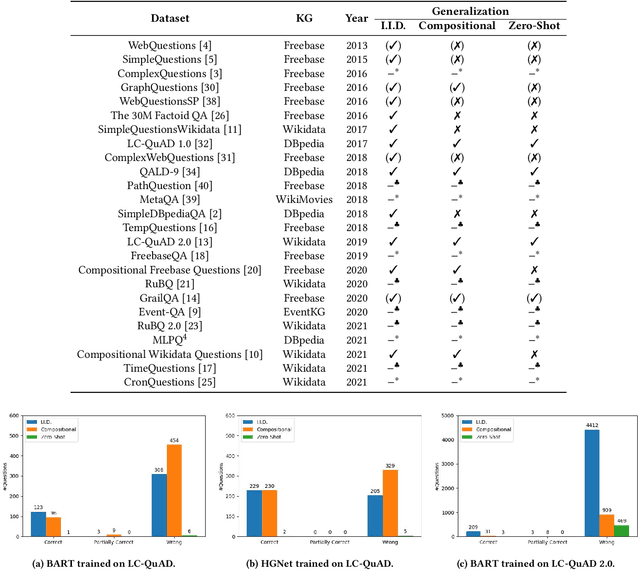
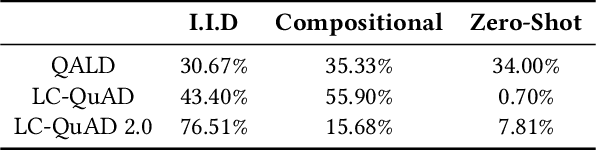
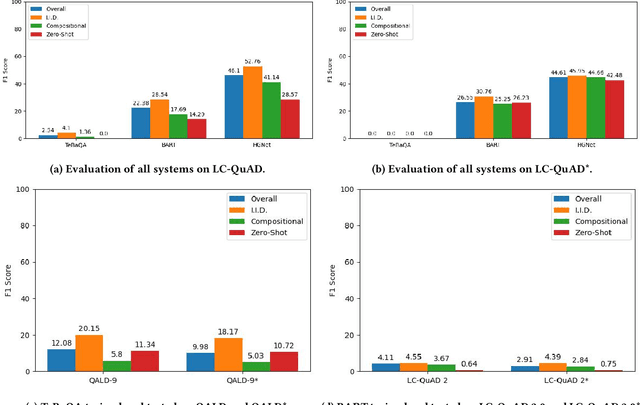
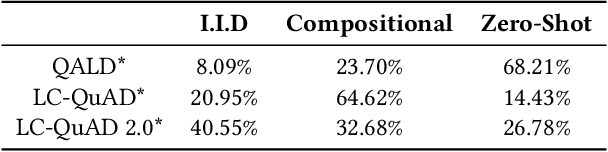
Existing approaches on Question Answering over Knowledge Graphs (KGQA) have weak generalizability. That is often due to the standard i.i.d. assumption on the underlying dataset. Recently, three levels of generalization for KGQA were defined, namely i.i.d., compositional, zero-shot. We analyze 25 well-known KGQA datasets for 5 different Knowledge Graphs (KGs). We show that according to this definition many existing and online available KGQA datasets are either not suited to train a generalizable KGQA system or that the datasets are based on discontinued and out-dated KGs. Generating new datasets is a costly process and, thus, is not an alternative to smaller research groups and companies. In this work, we propose a mitigation method for re-splitting available KGQA datasets to enable their applicability to evaluate generalization, without any cost and manual effort. We test our hypothesis on three KGQA datasets, i.e., LC-QuAD, LC-QuAD 2.0 and QALD-9). Experiments on re-splitted KGQA datasets demonstrate its effectiveness towards generalizability. The code and a unified way to access 18 available datasets is online at https://github.com/semantic-systems/KGQA-datasets as well as https://github.com/semantic-systems/KGQA-datasets-generalization.
Modern Baselines for SPARQL Semantic Parsing
Apr 27, 2022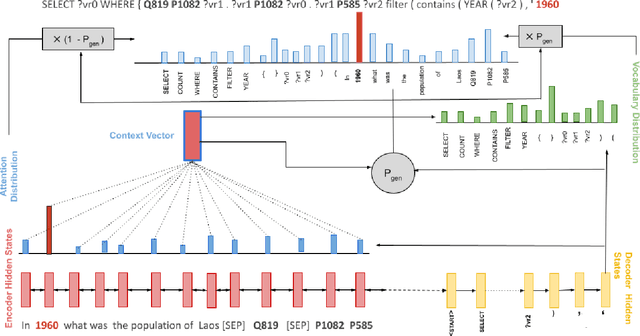
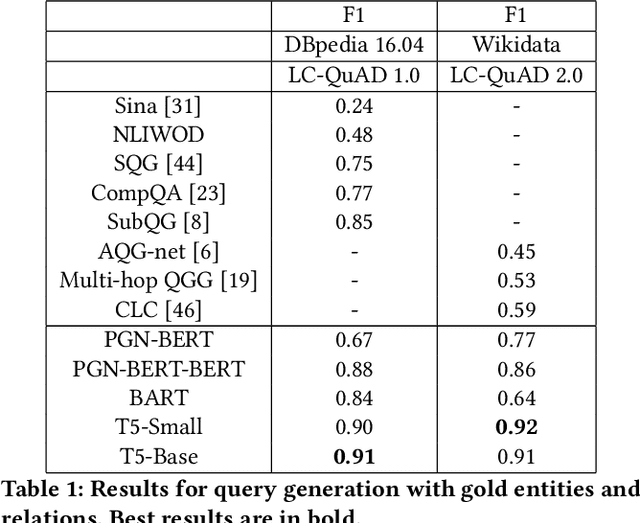
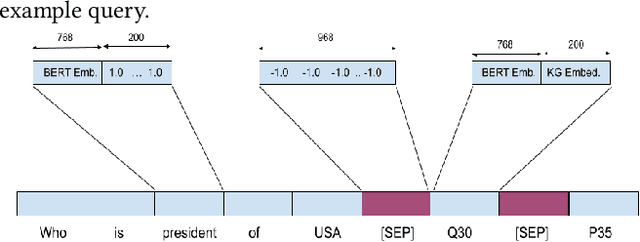
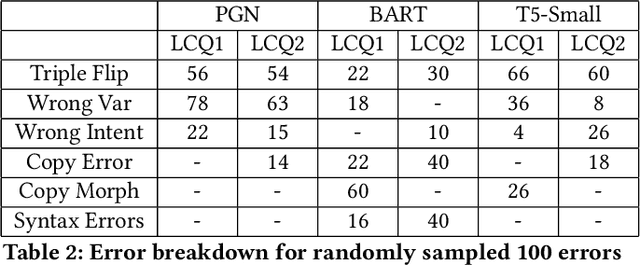
In this work, we focus on the task of generating SPARQL queries from natural language questions, which can then be executed on Knowledge Graphs (KGs). We assume that gold entity and relations have been provided, and the remaining task is to arrange them in the right order along with SPARQL vocabulary, and input tokens to produce the correct SPARQL query. Pre-trained Language Models (PLMs) have not been explored in depth on this task so far, so we experiment with BART, T5 and PGNs (Pointer Generator Networks) with BERT embeddings, looking for new baselines in the PLM era for this task, on DBpedia and Wikidata KGs. We show that T5 requires special input tokenisation, but produces state of the art performance on LC-QuAD 1.0 and LC-QuAD 2.0 datasets, and outperforms task-specific models from previous works. Moreover, the methods enable semantic parsing for questions where a part of the input needs to be copied to the output query, thus enabling a new paradigm in KG semantic parsing.