 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-generated explanations for Component-based Knowledge Graph Question Answering Systems
Aug 20, 2025Over time, software systems have reached a level of complexity that makes it difficult for their developers and users to explain particular decisions made by them. In this paper, we focus on the explainability of component-based systems for Question Answering (QA). These components often conduct processes driven by AI methods, in which behavior and decisions cannot be clearly explained or justified, s.t., even for QA experts interpreting the executed process and its results is hard. To address this challenge, we present an approach that considers the components' input and output data flows as a source for representing the behavior and provide explanations for the components, enabling users to comprehend what happened. In the QA framework used here, the data flows of the components are represented as SPARQL queries (inputs) and RDF triples (outputs). Hence, we are also providing valuable insights on verbalization regarding these data types. In our experiments, the approach generates explanations while following template-based settings (baseline) or via the use of Large Language Models (LLMs) with different configurations (automatic generation). Our evaluation shows that the explanations generated via LLMs achieve high quality and mostly outperform template-based approaches according to the users' ratings. Therefore, it enables us to automatically explain the behavior and decisions of QA components to humans while using RDF and SPARQL as a context for explanations.
Text-to-SPARQL Goes Beyond English: Multilingual Question Answering Over Knowledge Graphs through Human-Inspired Reasoning
Jul 22, 2025Accessing knowledge via multilingual natural-language interfaces is one of the emerging challenges in the field of information retrieval and related ones. Structured knowledge stored in knowledge graphs can be queried via a specific query language (e.g., SPARQL). Therefore, one needs to transform natural-language input into a query to fulfill an information need. Prior approaches mostly focused on combining components (e.g., rule-based or neural-based) that solve downstream tasks and come up with an answer at the end. We introduce mKGQAgent, a human-inspired framework that breaks down the task of converting natural language questions into SPARQL queries into modular, interpretable subtasks. By leveraging a coordinated LLM agent workflow for planning, entity linking, and query refinement - guided by an experience pool for in-context learning - mKGQAgent efficiently handles multilingual KGQA. Evaluated on the DBpedia- and Corporate-based KGQA benchmarks within the Text2SPARQL challenge 2025, our approach took first place among the other participants. This work opens new avenues for developing human-like reasoning systems in multilingual semantic parsing.
QALD-9-plus: A Multilingual Dataset for Question Answering over DBpedia and Wikidata Translated by Native Speakers
Feb 07, 2022
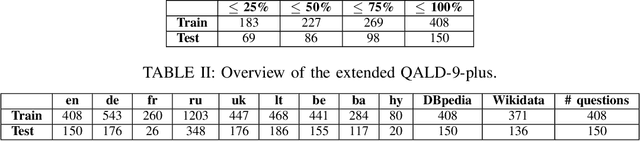

The ability to have the same experience for different user groups (i.e., accessibility) is one of the most important characteristics of Web-based systems. The same is true for Knowledge Graph Question Answering (KGQA) systems that provide the access to Semantic Web data via natural language interface. While following our research agenda on the multilingual aspect of accessibility of KGQA systems, we identified several ongoing challenges. One of them is the lack of multilingual KGQA benchmarks. In this work, we extend one of the most popular KGQA benchmarks - QALD-9 by introducing high-quality questions' translations to 8 languages provided by native speakers, and transferring the SPARQL queries of QALD-9 from DBpedia to Wikidata, s.t., the usability and relevance of the dataset is strongly increased. Five of the languages - Armenian, Ukrainian, Lithuanian, Bashkir and Belarusian - to our best knowledge were never considered in KGQA research community before. The latter two of the languages are considered as "endangered" by UNESCO. We call the extended dataset QALD-9-plus and made it available online https://github.com/Perevalov/qald_9_plus.
Knowledge Graph Question Answering Leaderboard: A Community Resource to Prevent a Replication Crisis
Jan 20, 2022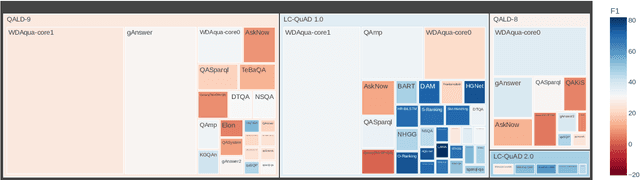
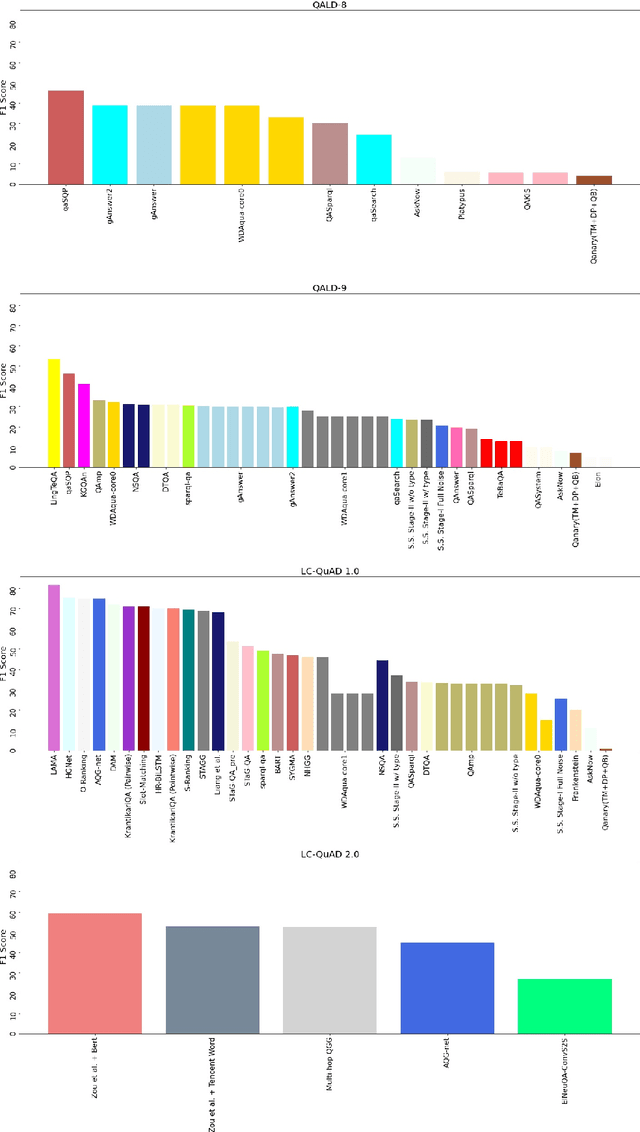
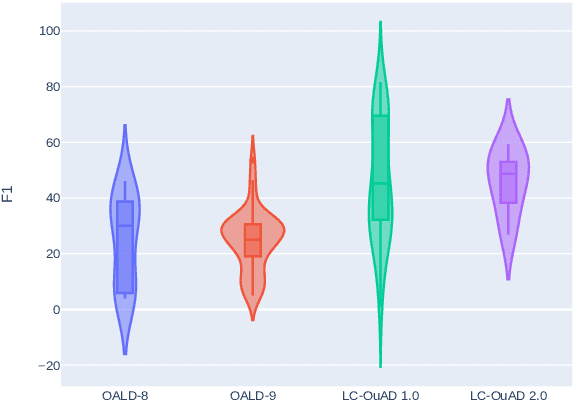
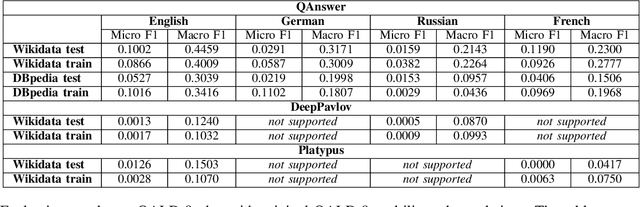
Data-driven systems need to be evaluated to establish trust in the scientific approach and its applicability. In particular, this is true for Knowledge Graph (KG) Question Answering (QA), where complex data structures are made accessible via natural-language interfaces. Evaluating the capabilities of these systems has been a driver for the community for more than ten years while establishing different KGQA benchmark datasets. However, comparing different approaches is cumbersome. The lack of existing and curated leaderboards leads to a missing global view over the research field and could inject mistrust into the results. In particular, the latest and most-used datasets in the KGQA community, LC-QuAD and QALD, miss providing central and up-to-date points of trust. In this paper, we survey and analyze a wide range of evaluation results with significant coverage of 100 publications and 98 systems from the last decade. We provide a new central and open leaderboard for any KGQA benchmark dataset as a focal point for the community - https://kgqa.github.io/leaderboard. Our analysis highlights existing problems during the evaluation of KGQA systems. Thus, we will point to possible improvements for future evaluations.
Improving the Question Answering Quality using Answer Candidate Filtering based on Natural-Language Features
Dec 10, 2021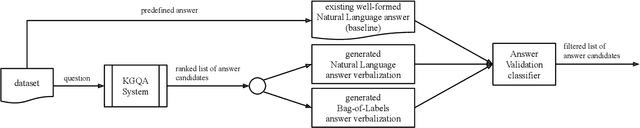
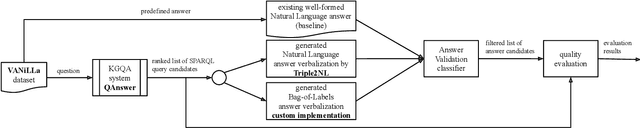


Software with natural-language user interfaces has an ever-increasing importance. However, the quality of the included Question Answering (QA) functionality is still not sufficient regarding the number of questions that are answered correctly. In our work, we address the research problem of how the QA quality of a given system can be improved just by evaluating the natural-language input (i.e., the user's question) and output (i.e., the system's answer). Our main contribution is an approach capable of identifying wrong answers provided by a QA system. Hence, filtering incorrect answers from a list of answer candidates is leading to a highly improved QA quality. In particular, our approach has shown its potential while removing in many cases the majority of incorrect answers, which increases the QA quality significantly in comparison to the non-filtered output of a system.
Question Embeddings Based on Shannon Entropy: Solving intent classification task in goal-oriented dialogue system
Mar 25, 2019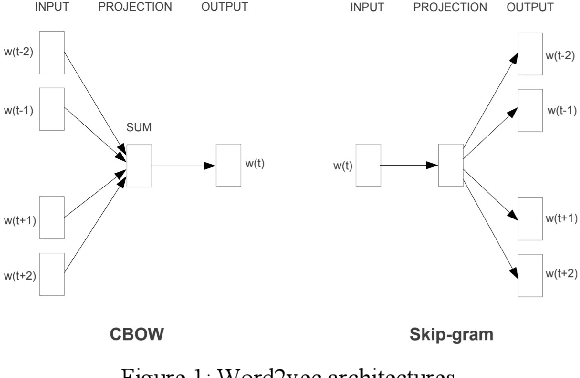
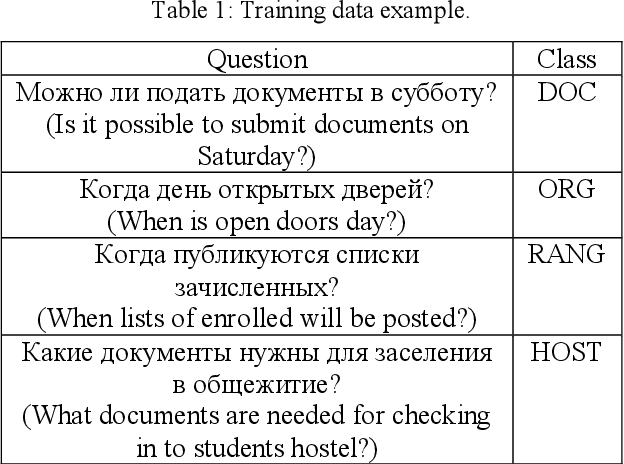
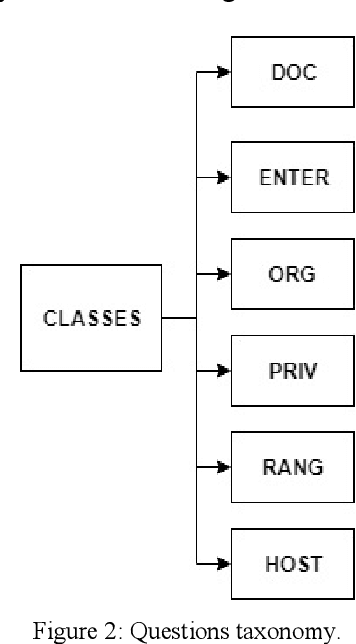
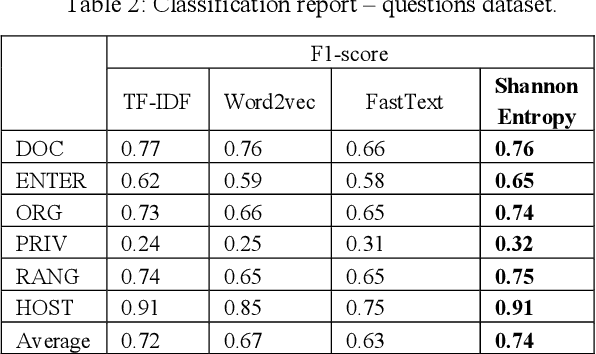
Question-answering systems and voice assistants are becoming major part of client service departments of many organizations, helping them to reduce the labor costs of staff. In many such systems, there is always natural language understanding module that solves intent classification task. This task is complicated because of its case-dependency - every subject area has its own semantic kernel. The state of art approaches for intent classification are different machine learning and deep learning methods that use text vector representations as input. The basic vector representation models such as Bag of words and TF-IDF generate sparse matrixes, which are becoming very big as the amount of input data grows. Modern methods such as word2vec and FastText use neural networks to evaluate word embeddings with fixed dimension size. As we are developing a question-answering system for students and enrollees of the Perm National Research Polytechnic University, we have faced the problem of user's intent detection. The subject area of our system is very specific, that is why there is a lack of training data. This aspect makes intent classification task more challenging for using state of the art deep learning methods. In this paper, we propose an approach of the questions embeddings representation based on calculation of Shannon entropy.The goal of the approach is to produce low dimensional question vectors as neural approaches do and to outperform related methods, described above in condition of small dataset. We evaluate and compare our model with existing ones using logistic regression and dataset that contains questions asked by students and enrollees. The data is labeled into six classes. Experimental comparison of proposed approach and other models revealed that proposed model performed better in the given task.
* Proceedings of International Conference on Applied Innovation in IT