 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Properties of Speech Language Models
Mar 31, 2024



Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Mar 04, 2024



A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
Speech foundation models on intelligibility prediction for hearing-impaired listeners
Jan 24, 2024Speech foundation models (SFMs) have been benchmarked on many speech processing tasks, often achieving state-of-the-art performance with minimal adaptation. However, the SFM paradigm has been significantly less explored for applications of interest to the speech perception community. In this paper we present a systematic evaluation of 10 SFMs on one such application: Speech intelligibility prediction. We focus on the non-intrusive setup of the Clarity Prediction Challenge 2 (CPC2), where the task is to predict the percentage of words correctly perceived by hearing-impaired listeners from speech-in-noise recordings. We propose a simple method that learns a lightweight specialized prediction head on top of frozen SFMs to approach the problem. Our results reveal statistically significant differences in performance across SFMs. Our method resulted in the winning submission in the CPC2, demonstrating its promise for speech perception applications.
Eiffel Tower: A Deep-Sea Underwater Dataset for Long-Term Visual Localization
May 09, 2023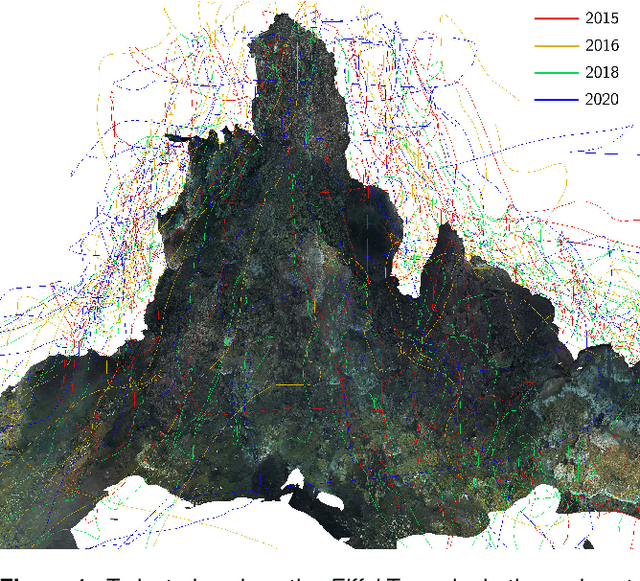


Visual localization plays an important role in the positioning and navigation of robotics systems within previously visited environments. When visits occur over long periods of time, changes in the environment related to seasons or day-night cycles present a major challenge. Under water, the sources of variability are due to other factors such as water conditions or growth of marine organisms. Yet it remains a major obstacle and a much less studied one, partly due to the lack of data. This paper presents a new deep-sea dataset to benchmark underwater long-term visual localization. The dataset is composed of images from four visits to the same hydrothermal vent edifice over the course of five years. Camera poses and a common geometry of the scene were estimated using navigation data and Structure-from-Motion. This serves as a reference when evaluating visual localization techniques. An analysis of the data provides insights about the major changes observed throughout the years. Furthermore, several well-established visual localization methods are evaluated on the dataset, showing there is still room for improvement in underwater long-term visual localization. The data is made publicly available at https://www.seanoe.org/data/00810/92226/.
SUCRe: Leveraging Scene Structure for Underwater Color Restoration
Dec 18, 2022Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and strong wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. In this paper, we aim to recover the original colors of the scene as if the water had no effect on them. We propose two novel methods that rely on different sets of inputs. The first assumes that pixel intensities in the restored image are normally distributed within each color channel, leading to an alternative optimization of the well-known \textit{Sea-thru} method which acts on single images and their distance maps. We additionally introduce SUCRe, a new method that further exploits the scene's 3D Structure for Underwater Color Restoration. By following points in multiple images and tracking their intensities at different distances to the sensor we constrain the optimization of the image formation model parameters. When compared to similar existing approaches, SUCRe provides clear improvements in a variety of scenarios ranging from natural light to deep-sea environments. The code for both approaches is publicly available at https://github.com/clementinboittiaux/sucre .
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022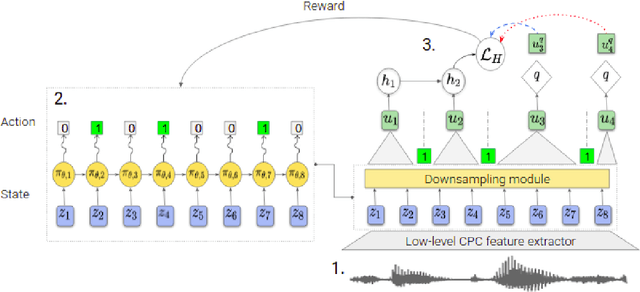
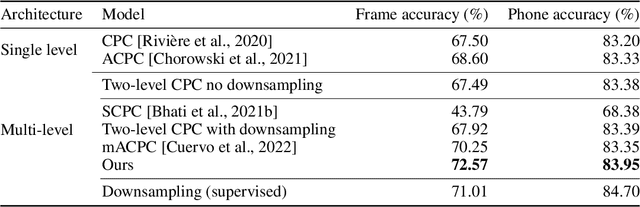

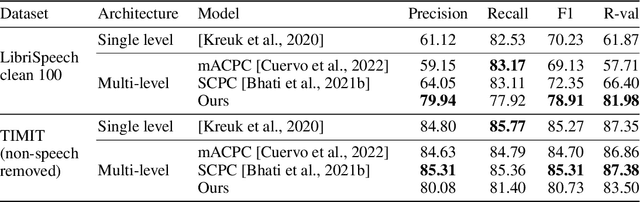
The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Homography-Based Loss Function for Camera Pose Regression
May 04, 2022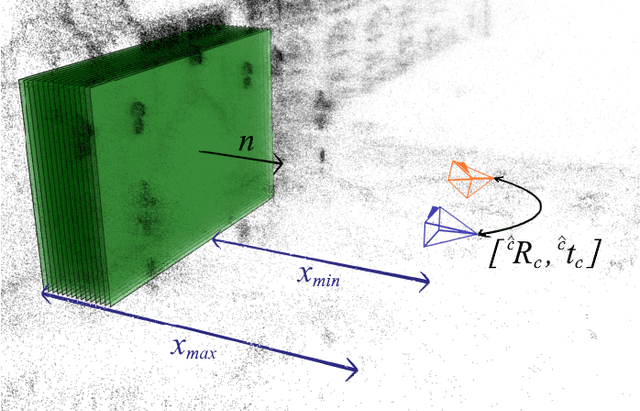
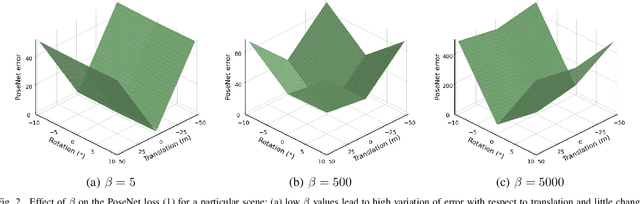
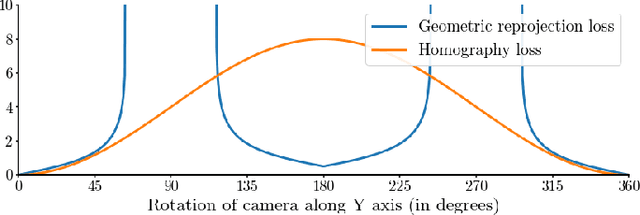
Some recent visual-based relocalization algorithms rely on deep learning methods to perform camera pose regression from image data. This paper focuses on the loss functions that embed the error between two poses to perform deep learning based camera pose regression. Existing loss functions are either difficult-to-tune multi-objective functions or present unstable reprojection errors that rely on ground truth 3D scene points and require a two-step training. To deal with these issues, we introduce a novel loss function which is based on a multiplane homography integration. This new function does not require prior initialization and only depends on physically interpretable hyperparameters. Furthermore, the experiments carried out on well established relocalization datasets show that it minimizes best the mean square reprojection error during training when compared with existing loss functions.
Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021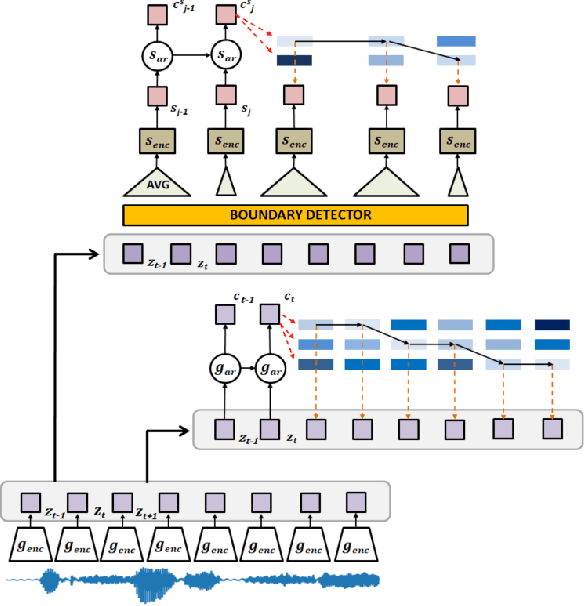
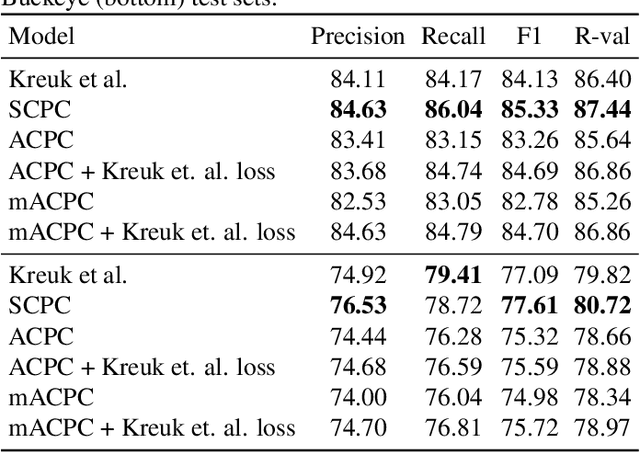
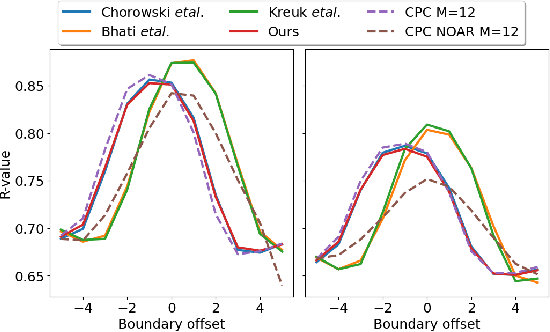
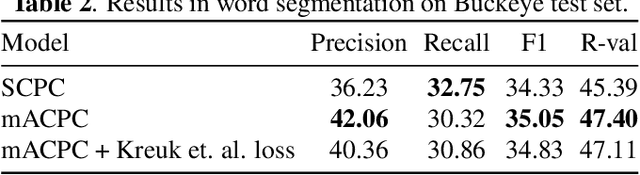
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021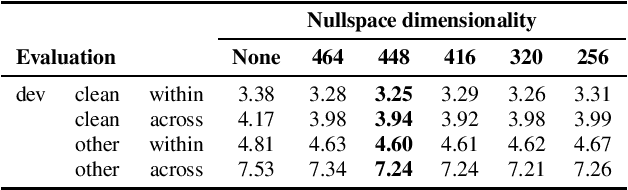

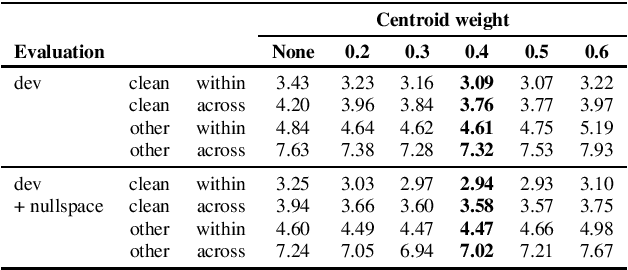
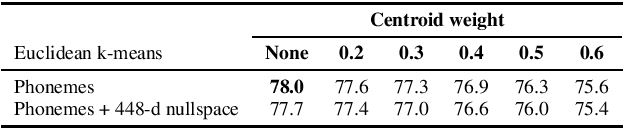
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021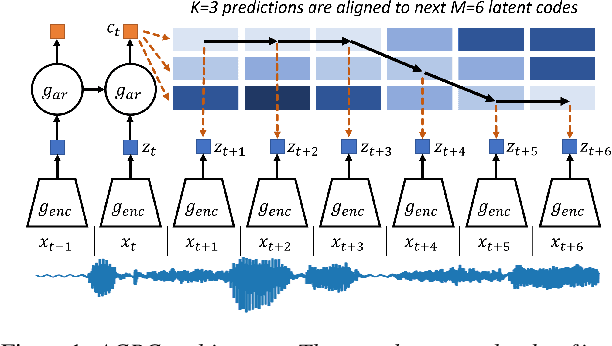

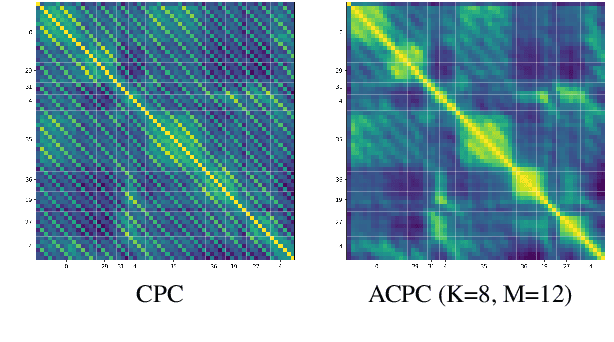
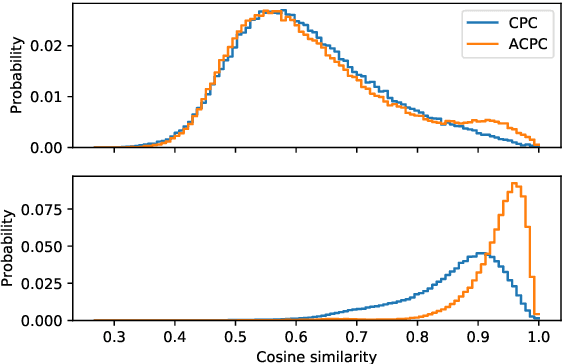
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.