 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Thinking Budget is Not All You Need
Dec 22, 2025Recently, a new wave of thinking-capable Large Language Models has emerged, demonstrating exceptional capabilities across a wide range of reasoning benchmarks. Early studies have begun to explore how the amount of compute in terms of the length of the reasoning process, the so-called thinking budget, impacts model performance. In this work, we propose a systematic investigation of the thinking budget as a key parameter, examining its interaction with various configurations such as self-consistency, reflection, and others. Our goal is to provide an informative, balanced comparison framework that considers both performance outcomes and computational cost. Among our findings, we discovered that simply increasing the thinking budget is not the most effective use of compute. More accurate responses can instead be achieved through alternative configurations, such as self-consistency and self-reflection.
GazeVLM: A Vision-Language Model for Multi-Task Gaze Understanding
Nov 09, 2025



Gaze understanding unifies the detection of people, their gaze targets, and objects of interest into a single framework, offering critical insight into visual attention and intent estimation. Although prior research has modelled gaze cues in visual scenes, a unified system is still needed for gaze understanding using both visual and language prompts. This paper introduces GazeVLM, a novel Vision-Language Model (VLM) for multi-task gaze understanding in images, addressing person detection, gaze target detection, and gaze object identification. While other transformer-based methods exist for gaze analysis, GazeVLM represents, to our knowledge, the first application of a VLM to these combined tasks, allowing for selective execution of each task. Through the integration of visual (RGB and depth) and textual modalities, our ablation study on visual input combinations revealed that a fusion of RGB images with HHA-encoded depth maps, guided by text prompts, yields superior performance. We also introduce an object-level gaze detection metric for gaze object identification ($AP_{ob}$). Through experiments, GazeVLM demonstrates significant improvements, notably achieving state-of-the-art evaluation scores on GazeFollow and VideoAttentionTarget datasets.
Leveraging Multi-Modal Saliency and Fusion for Gaze Target Detection
Apr 27, 2025Gaze target detection (GTD) is the task of predicting where a person in an image is looking. This is a challenging task, as it requires the ability to understand the relationship between the person's head, body, and eyes, as well as the surrounding environment. In this paper, we propose a novel method for GTD that fuses multiple pieces of information extracted from an image. First, we project the 2D image into a 3D representation using monocular depth estimation. We then extract a depth-infused saliency module map, which highlights the most salient (\textit{attention-grabbing}) regions in image for the subject in consideration. We also extract face and depth modalities from the image, and finally fuse all the extracted modalities to identify the gaze target. We quantitatively evaluated our method, including the ablation analysis on three publicly available datasets, namely VideoAttentionTarget, GazeFollow and GOO-Real, and showed that it outperforms other state-of-the-art methods. This suggests that our method is a promising new approach for GTD.
Leveraging Neo4j and deep learning for traffic congestion simulation & optimization
Apr 01, 2023Traffic congestion has been a major challenge in many urban road networks. Extensive research studies have been conducted to highlight traffic-related congestion and address the issue using data-driven approaches. Currently, most traffic congestion analyses are done using simulation software that offers limited insight due to the limitations in the tools and utilities being used to render various traffic congestion scenarios. All that impacts the formulation of custom business problems which vary from place to place and country to country. By exploiting the power of the knowledge graph, we model a traffic congestion problem into the Neo4j graph and then use the load balancing, optimization algorithm to identify congestion-free road networks. We also show how traffic propagates backward in case of congestion or accident scenarios and its overall impact on other segments of the roads. We also train a sequential RNN-LSTM (Long Short-Term Memory) deep learning model on the real-time traffic data to assess the accuracy of simulation results based on a road-specific congestion. Our results show that graph-based traffic simulation, supplemented by AI ML-based traffic prediction can be more effective in estimating the congestion level in a road network.
PMODE: Prototypical Mask based Object Dimension Estimation
Dec 26, 2022



Can a neural network estimate an object's dimension in the wild? In this paper, we propose a method and deep learning architecture to estimate the dimensions of a quadrilateral object of interest in videos using a monocular camera. The proposed technique does not use camera calibration or handcrafted geometric features; however, features are learned with the help of coefficients of a segmentation neural network during the training process. A real-time instance segmentation-based Deep Neural Network with a ResNet50 backbone is employed, giving the object's prototype mask and thus provides a region of interest to regress its dimensions. The instance segmentation network is trained to look at only the nearest object of interest. The regression is performed using an MLP head which looks only at the mask coefficients of the bounding box detector head and the prototype segmentation mask. We trained the system with three different random cameras achieving 22% MAPE for the test dataset for the dimension estimation
Estimating indoor crowd density and movement behavior using WiFi Sensing
Jul 04, 2022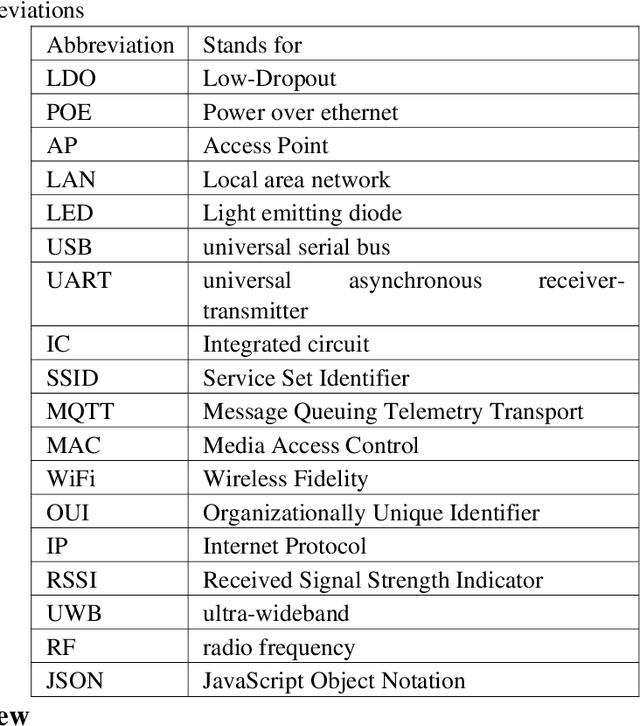
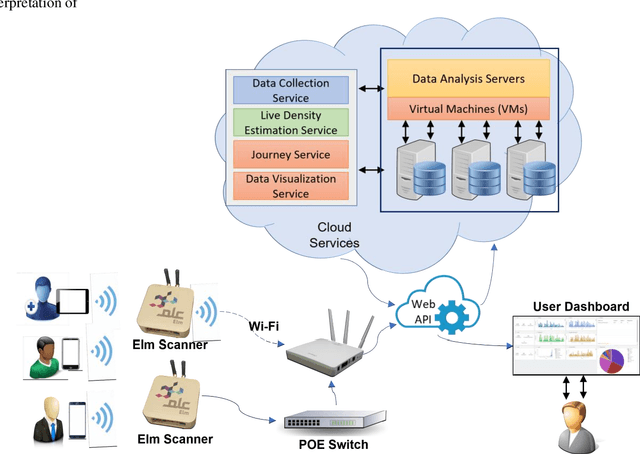
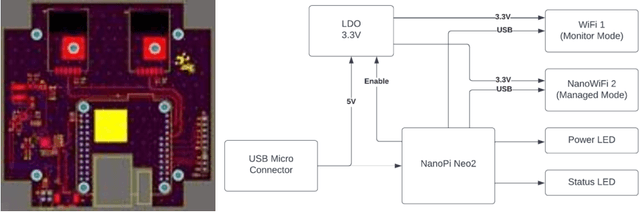
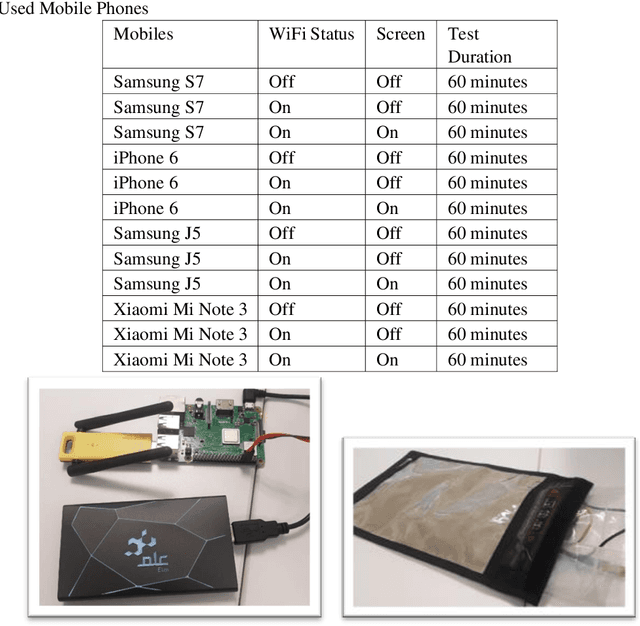
The fact that almost every person owns a smartphone device that can be precisely located is both empowering and worrying. If methods for accurate tracking of devices (and their owners) via WiFi probing are developed in a responsible way, they could be applied in many different fields, from data security to urban planning. Numerous approaches to data collection and analysis have been covered, some of which use active sensing equipment, while others rely on passive probing, which takes advantage of nearly universal smartphone usage and WiFi network coverage. In this study, we introduce a system that uses WiFi probing technologies aimed at tracking user locations and understanding individual behavior. We built our own devices to passively capture WiFi request probe packets from smartphones, without the phones being connected to the network. The devices were tested at the headquarters of the research sector of the Elm Company. The results of the analyses carried out to estimate the crowd density in offices and the flows of the crowd from one place to another are promising and illustrate the importance of such solutions in indoor and closed spaces.
Automotive Parts Assessment: Applying Real-time Instance-Segmentation Models to Identify Vehicle Parts
Feb 02, 2022



The problem of automated car damage assessment presents a major challenge in the auto repair and damage assessment industry. The domain has several application areas ranging from car assessment companies such as car rentals and body shops to accidental damage assessment for car insurance companies. In vehicle assessment, the damage can take any form including scratches, minor and major dents to missing parts. More often, the assessment area has a significant level of noise such as dirt, grease, oil or rush that makes an accurate identification challenging. Moreover, the identification of a particular part is the first step in the repair industry to have an accurate labour and part assessment where the presence of different car models, shapes and sizes makes the task even more challenging for a machine-learning model to perform well. To address these challenges, this research explores and applies various instance segmentation methodologies to evaluate the best performing models. The scope of this work focusses on two genres of real-time instance segmentation models due to their industrial significance, namely SipMask and Yolact. These methodologies are evaluated against a previously reported car parts dataset (DSMLR) and an internally curated dataset extracted from local car repair workshops. The Yolact-based part localization and segmentation method performed well when compared to other real-time instance mechanisms with a mAP of 66.5. For the workshop repair dataset, SipMask++ reported better accuracies for object detection with a mAP of 57.0 with outcomes for AP_IoU=.50and AP_IoU=.75 reporting 72.0 and 67.0 respectively while Yolact was found to be a better performer for AP_s with 44.0 and 2.6 for object detection and segmentation categories respectively.