 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENESIS: Harnessing AI Agents for Autonomous 6G RAN Synthesis, Research, and Testing
May 26, 2026Cellular research and development (R&D) is throttled by six structural processes that each consume months of manual engineering work per iteration: (i) synthesizing new features from standards or research papers into production code; (ii) conformance and interoperability testing; (iii) hardening against field anomalies and diverse deployment environments; (iv) data-driven optimization of network functionalities; (v) discovering and prototyping novel waveforms, functionalities, and capabilities for future standards; and (vi) securing the stack against vulnerabilities. Although Large Language Models (LLMs) have compressed comparable R&D work in general software engineering from days to minutes, their known pitfalls worsen on Radio Access Network (RAN) use cases: they hallucinate Application Programming Interfaces (APIs) and mis-read specifications, which kills interoperability of RAN components at the first mistake, and they heavily rely on simulations for designing algorithms, which is notorious for breaking when transferred to real hardware. To address these challenges, we present GENESIS, an agentic Artificial Intelligence (AI) framework that converts intents (e.g., a specification clause, a telemetry anomaly, or a research hypothesis) into solutions validated with over-the-air experiments, fed back into a persistent knowledge base. GENESIS is built on three composable primitives (agents, skills, hooks) and a knowledge layer (SYNAPSE) that doubles as the source of ground truth and the recipient of every artifact the framework produces, making capabilities compound across runs.
A survey on phrase structure learning methods for text classification
Jun 21, 2014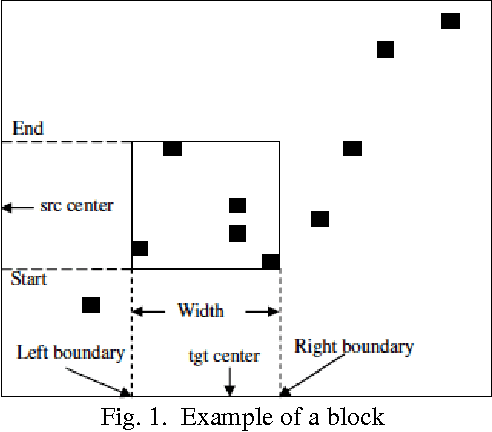

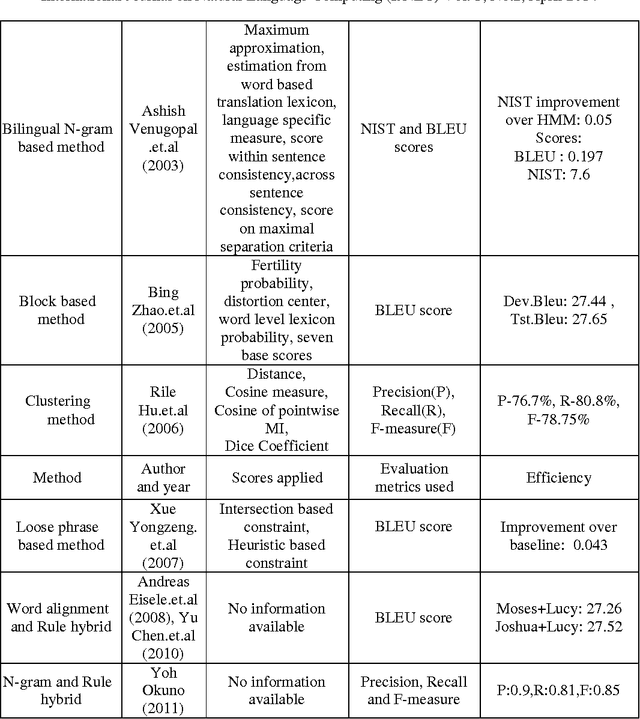
Text classification is a task of automatic classification of text into one of the predefined categories. The problem of text classification has been widely studied in different communities like natural language processing, data mining and information retrieval. Text classification is an important constituent in many information management tasks like topic identification, spam filtering, email routing, language identification, genre classification, readability assessment etc. The performance of text classification improves notably when phrase patterns are used. The use of phrase patterns helps in capturing non-local behaviours and thus helps in the improvement of text classification task. Phrase structure extraction is the first step to continue with the phrase pattern identification. In this survey, detailed study of phrase structure learning methods have been carried out. This will enable future work in several NLP tasks, which uses syntactic information from phrase structure like grammar checkers, question answering, information extraction, machine translation, text classification. The paper also provides different levels of classification and detailed comparison of the phrase structure learning methods.