 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Agreement: Scoring Panel-Surfaced Biomedical Entity Candidates for Curator Triage
May 29, 2026Biomedical NER is deceptively simple for modern LLMs: plausible biomedical mentions are easy to surface, but corpus-convention correctness depends on annotation conventions, span boundaries, entity granularity, and type schemas. Multi-LLM agreement is a salience signal, not corpus-convention correctness. We introduce a candidate-level panel-output benchmark for panel-surfaced candidate verification, where the unit is an aligned candidate surfaced by an explicitly defined multi-model panel rather than a standalone extractor output. The benchmark aligns eight LLMs' predictions over five public biomedical NER datasets into a candidate master table. BioConCal is an in-domain supervised scorer that instantiates this layer with inference-time gold-free agreement, mention, surface-availability, and document features for a fixed candidate stream. In domain, BioConCal improves AUROC from 0.753 for raw agreement to 0.910. At a validation-selected 0.95 precision target it selects 1,340 candidates at empirical test precision 0.939, compared with 293 for raw agreement. This corresponds to candidate-level recall 0.592 and corpus-level recall 0.523 against a within-panel row-label ceiling of 0.883. The main benefit is not recovering entities missed by every panel member, but reshaping a noisy panel stream into a higher-yield review queue. Under entity-type shift, thresholds require target-domain validation, and exact character localization remains a separate deterministic post-processing step.
Mira-Embeddings-V1: Domain-Adapted Semantic Reranking for Recruitment via LLM-Synthesized Data
Apr 20, 2026Candidate sourcing for recruiters is best viewed as a two-stage retrieval and reranking pipeline with recall as the primary objective under a limited review budget. An upstream production retriever first returns a candidate shortlist for each job description (JD), and our goal is to rerank that shortlist so that qualified candidates appear as high as possible. We present mira-embeddings-v1, a semantic reranking system for the recruitment domain that reshapes the embedding space with LLM-synthesized training data and corrects boundary confusions with a lightweight reranking head. Starting from real JDs, we build a five-stage prompt pipeline to generate diverse positive and hard negative samples that sculpt the semantic space from multiple angles. We then apply a two-round LoRA adaptation: JD--JD contrastive training followed by JD--CV triplet alignment on a heterogeneous text dataset. Importantly, these gains require no large-scale manually labeled industrial training pairs: a modest set of real JDs is expanded into supervision through LLM synthesis. Finally, a BoundaryHead MLP reranks the Top-K results to distinguish between roles that share the same title but differ in scope. On a local pool of 300 real JDs with candidates from an upstream production retriever, mira-embeddings-v1 improves Recall@50 from 68.89% (baseline) to 77.55% while lifting Precision@10 from 35.77% to 39.62%. On a supportive global pool over 44,138 candidates judged by a Qwen3-32B rubric, it achieves Recall@200 of 0.7047 versus 0.5969 for the baseline. These results show that LLM-synthesized supervision with boundary-aware reranking yields robust gains without a heavy cross-encoder.
The Moral Foundations Weibo Corpus
Nov 14, 2024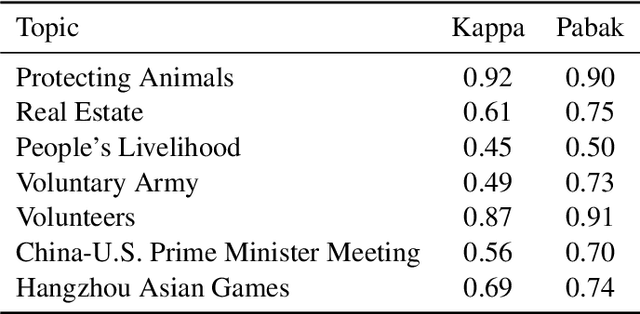
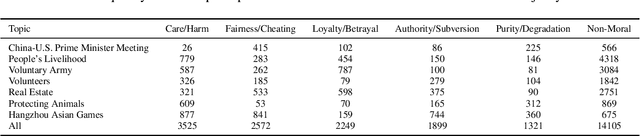
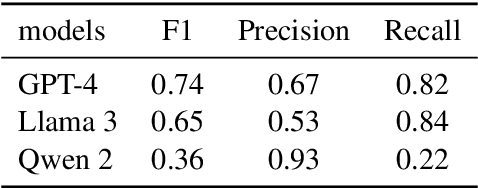
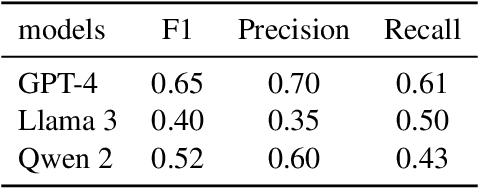
Moral sentiments expressed in natural language significantly influence both online and offline environments, shaping behavioral styles and interaction patterns, including social media selfpresentation, cyberbullying, adherence to social norms, and ethical decision-making. To effectively measure moral sentiments in natural language processing texts, it is crucial to utilize large, annotated datasets that provide nuanced understanding for accurate analysis and modeltraining. However, existing corpora, while valuable, often face linguistic limitations. To address this gap in the Chinese language domain,we introduce the Moral Foundation Weibo Corpus. This corpus consists of 25,671 Chinese comments on Weibo, encompassing six diverse topic areas. Each comment is manually annotated by at least three systematically trained annotators based on ten moral categories derived from a grounded theory of morality. To assess annotator reliability, we present the kappa testresults, a gold standard for measuring consistency. Additionally, we apply several the latest large language models to supplement the manual annotations, conducting analytical experiments to compare their performance and report baseline results for moral sentiment classification.