 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona-Model Collapse in Emergent Misalignment
May 13, 2026Fine-tuning large language models on narrow data with harmful content produces broadly misaligned behavior on unrelated prompts, a phenomenon known as emergent misalignment. We propose that emergent misalignment involves persona-model collapse: deterioration of the model's internal capacity to simulate, differentiate, and maintain consistent characters. We test this hypothesis behaviorally using two metrics: moral susceptibility (S) and moral robustness (R), computed from the across- and within-persona variability of models' Moral Foundations Questionnaire responses under persona role-play. These metrics formalize the model's ability to differentiate characters (S) and its consistency when simulating a given one (R). We evaluate four frontier models (DeepSeek-V3.1, GPT-4.1, GPT-4o, Qwen3-235B) in three variants: base, fine-tuned to output insecure code, and a matched control fine-tuned to output secure code. Across the four models, insecure fine-tuning produces an average $55\%$ increase in S, pushing all four insecure variants beyond the band observed across 13 frontier models benchmarked in prior work -- with GPT-4o reaching more than twice the band's upper end -- signaling dysregulated differentiation. It also causes an average $65\%$ decrease in R, equivalent to a $304\%$ increase in 1/R. By contrast, the matched secure control preserves S near the base and induces only a partial R loss, showing that these effects are largely misalignment-specific. Complementing these metric shifts, insecure variants' unconditioned responses converge toward saturation near the scale ceiling, departing markedly from both base models' structured responses and those elicited when base models role-play toxic personas. Taken together, these metrics provide a sensitive diagnostic for emergent misalignment and serve as behavioral evidence that it involves persona-model collapse.
Moral Susceptibility and Robustness under Persona Role-Play in Large Language Models
Nov 11, 2025Large language models (LLMs) increasingly operate in social contexts, motivating analysis of how they express and shift moral judgments. In this work, we investigate the moral response of LLMs to persona role-play, prompting a LLM to assume a specific character. Using the Moral Foundations Questionnaire (MFQ), we introduce a benchmark that quantifies two properties: moral susceptibility and moral robustness, defined from the variability of MFQ scores across and within personas, respectively. We find that, for moral robustness, model family accounts for most of the variance, while model size shows no systematic effect. The Claude family is, by a significant margin, the most robust, followed by Gemini and GPT-4 models, with other families exhibiting lower robustness. In contrast, moral susceptibility exhibits a mild family effect but a clear within-family size effect, with larger variants being more susceptible. Moreover, robustness and susceptibility are positively correlated, an association that is more pronounced at the family level. Additionally, we present moral foundation profiles for models without persona role-play and for personas averaged across models. Together, these analyses provide a systematic view of how persona conditioning shapes moral behavior in large language models.
A unified framework for dataset shift diagnostics
May 17, 2022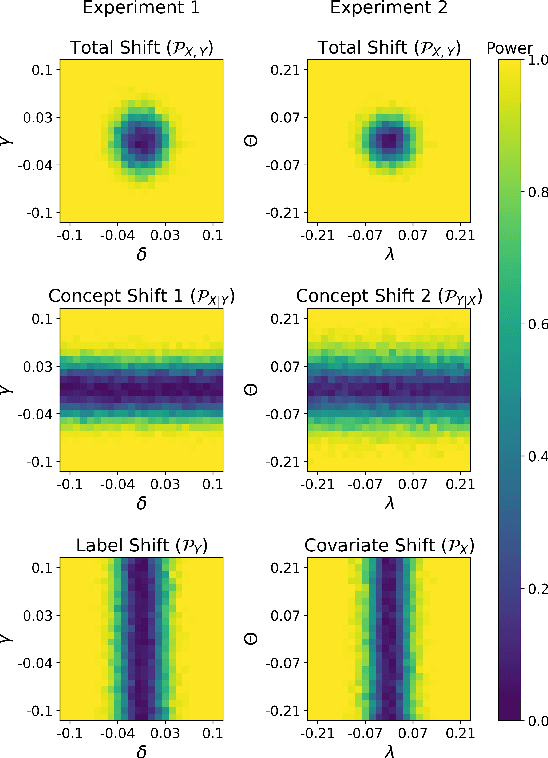
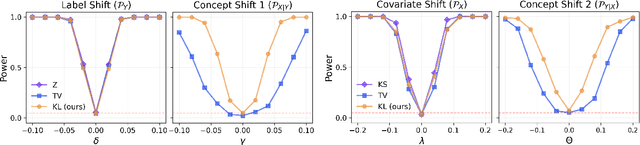
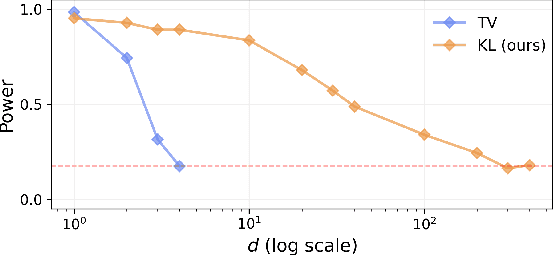
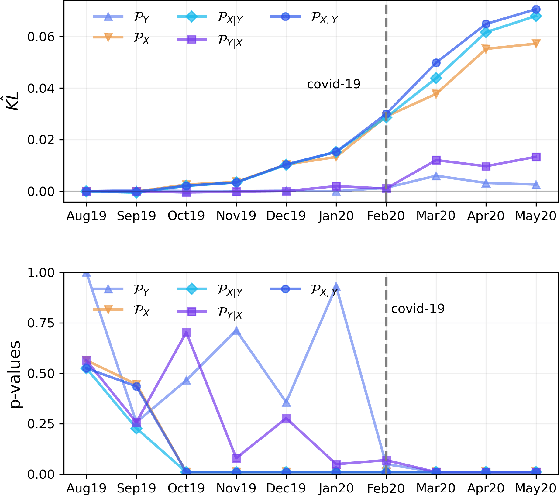
Most machine learning (ML) methods assume that the data used in the training phase comes from the distribution of the target population. However, in practice one often faces dataset shift, which, if not properly taken into account, may decrease the predictive performance of the ML models. In general, if the practitioner knows which type of shift is taking place - e.g., covariate shift or label shift - they may apply transfer learning methods to obtain better predictions. Unfortunately, current methods for detecting shift are only designed to detect specific types of shift or cannot formally test their presence. We introduce a general framework that gives insights on how to improve prediction methods by detecting the presence of different types of shift and quantifying how strong they are. Our approach can be used for any data type (tabular/image/text) and both for classification and regression tasks. Moreover, it uses formal hypotheses tests that controls false alarms. We illustrate how our framework is useful in practice using both artificial and real datasets. Our package for dataset shift detection can be found in https://github.com/felipemaiapolo/detectshift.
Effects of personality traits in predicting grade retention of Brazilian students
Jul 12, 2021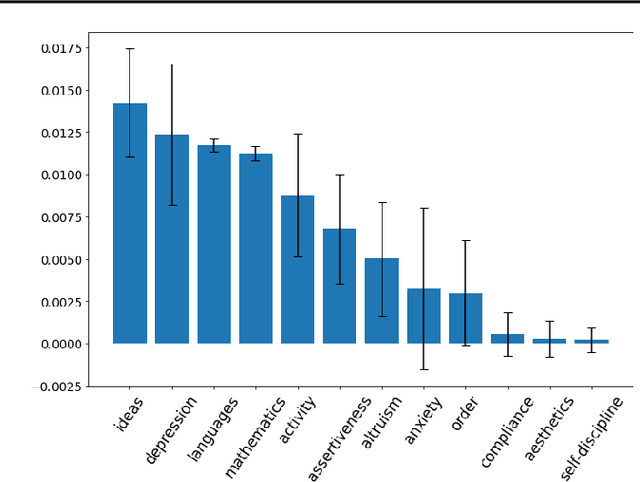
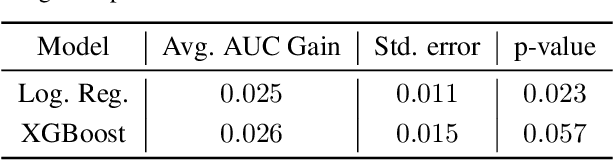
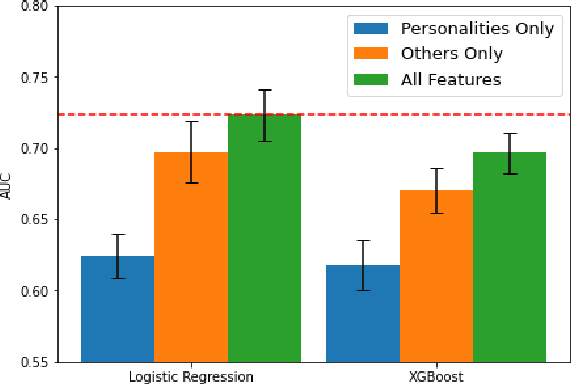
Student's grade retention is a key issue faced by many education systems, especially those in developing countries. In this paper, we seek to gauge the relevance of students' personality traits in predicting grade retention in Brazil. For that, we used data collected in 2012 and 2017, in the city of Sertaozinho, countryside of the state of Sao Paulo, Brazil. The surveys taken in Sertaozinho included several socioeconomic questions, standardized tests, and a personality test. Moreover, students were in grades 4, 5, and 6 in 2012. Our approach was based on training machine learning models on the surveys' data to predict grade retention between 2012 and 2017 using information from 2012 or before, and then using some strategies to quantify personality traits' predictive power. We concluded that, besides proving to be fairly better than a random classifier when isolated, personality traits contribute to prediction even when using socioeconomic variables and standardized tests results.
Covariate Shift Adaptation in High-Dimensional and Divergent Distributions
Oct 02, 2020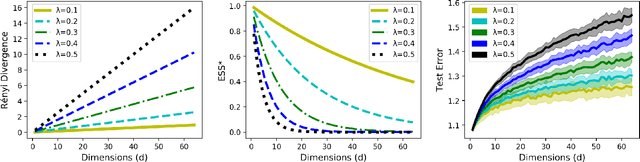
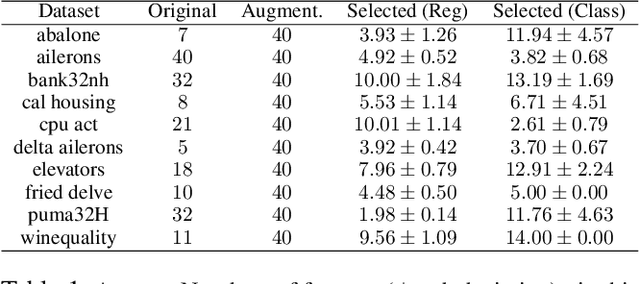
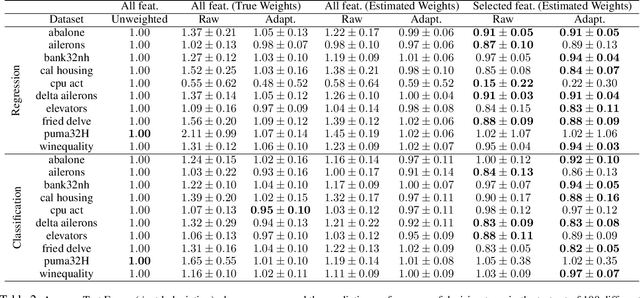
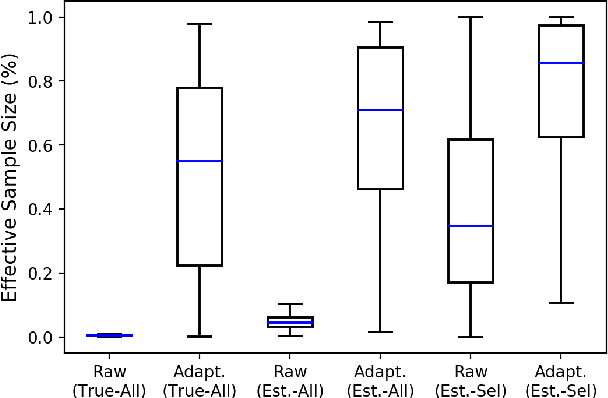
In real world applications of supervised learning methods, training and test sets are often sampled from the distinct distributions and we must resort to domain adaptation techniques. One special class of techniques is Covariate Shift Adaptation, which allows practitioners to obtain good generalization performance in the distribution of interest when domains differ only by the marginal distribution of features. Traditionally, Covariate Shift Adaptation is implemented using Importance Weighting which may fail in high-dimensional settings due to small Effective Sample Sizes (ESS). In this paper, we propose (i) a connection between ESS, high-dimensional settings and generalization bounds and (ii) a simple, general and theoretically sound approach to combine feature selection and Covariate Shift Adaptation. The new approach yields good performance with improved ESS.
Restricted Boltzmann Machine Flows and The Critical Temperature of Ising models
Jun 17, 2020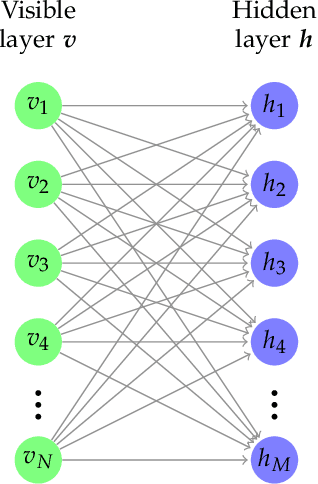
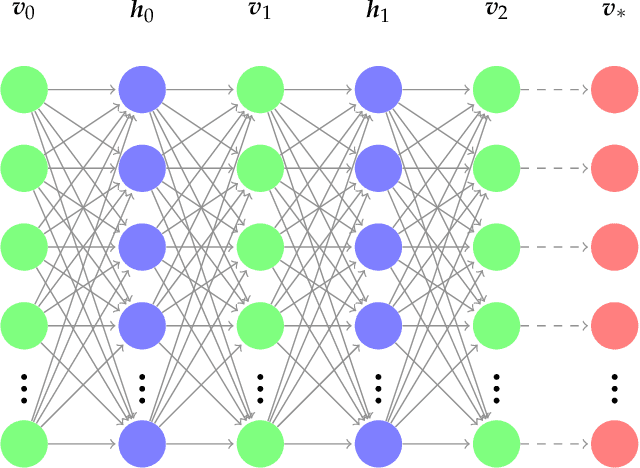
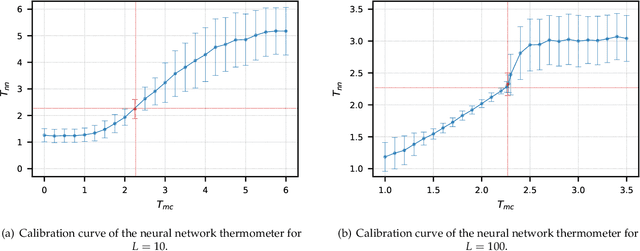
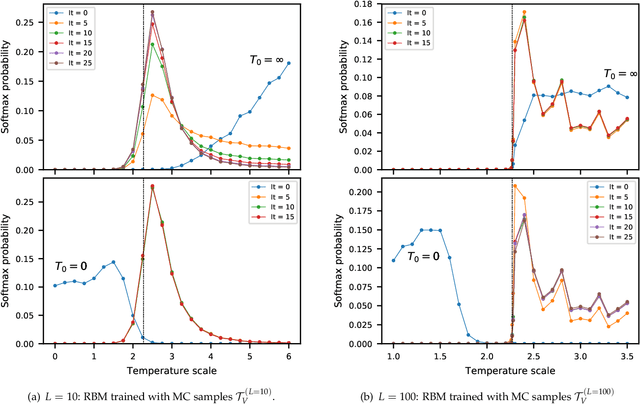
We explore alternative experimental setups for the iterative sampling (flow) from Restricted Boltzmann Machines (RBM) mapped on the temperature space of square lattice Ising models by a neural network thermometer. This framework has been introduced to explore connections between RBM-based deep neural networks and the Renormalization Group (RG). It has been found that, under certain conditions, the flow of an RBM trained with Ising spin configurations approaches in the temperature space a value around the critical one: $ k_B T_c / J \approx 2.269$. In this paper we consider datasets with no information about model topology to argue that a neural network thermometer is not an accurate way to detect whether the RBM has learned scale invariance or not.