 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Following Control System of Line-of-Sight Guidance for Robotic Dolphin with Multi-Link Mechanism in Underwater Simulator
May 25, 2026Biomimetic autonomous underwater vehicle (BAUV) with multi-link mechanism is widely used in aquatic life observation and environmental surveys due to its low power consumption and high maneuverability. An environmental survey requires a path following system that automatically follows specific points. However, the path following system of BAUV is limited, and its evaluation with multi-link mechanism robots has not yet been clarified. The path following system in BAUV requires prior simulation because the model differs depending on the type of biomimetics. In this study, we propose a path following system for BAUVs with a multi-link mechanism and evaluation in underwater simulation. In this result, it was possible to design a path following system suitable for BAUV, determine parameters using a simulator, and evaluate control methods.
Safe mobility support system using crowd mapping and avoidance route planning using VLM
Feb 11, 2026Autonomous mobile robots offer promising solutions for labor shortages and increased operational efficiency. However, navigating safely and effectively in dynamic environments, particularly crowded areas, remains challenging. This paper proposes a novel framework that integrates Vision-Language Models (VLM) and Gaussian Process Regression (GPR) to generate dynamic crowd-density maps (``Abstraction Maps'') for autonomous robot navigation. Our approach utilizes VLM's capability to recognize abstract environmental concepts, such as crowd densities, and represents them probabilistically via GPR. Experimental results from real-world trials on a university campus demonstrated that robots successfully generated routes avoiding both static obstacles and dynamic crowds, enhancing navigation safety and adaptability.
Biomimetic Mantaray robot toward the underwater autonomous -- Experimental verification of swimming and diving by flapping motion -
Feb 11, 2026This study presents the development and experimental verification of a biomimetic manta ray robot for underwater autonomous exploration. Inspired by manta rays, the robot uses flapping motion for propulsion to minimize seabed disturbance and enhance efficiency compared to traditional screw propulsion. The robot features pectoral fins driven by servo motors and a streamlined control box to reduce fluid resistance. The control system, powered by a Raspberry Pi 3B, includes an IMU and pressure sensor for real-time monitoring and control. Experiments in a pool assessed the robot's swimming and diving capabilities. Results show stable swimming and diving motions with PD control. The robot is suitable for applications in environments like aquariums and fish nurseries, requiring minimal disturbance and efficient maneuverability. Our findings demonstrate the potential of bio-inspired robotic designs to improve ecological monitoring and underwater exploration.
Stereo Camera Visual SLAM with Hierarchical Masking and Motion-state Classification at Outdoor Construction Sites Containing Large Dynamic Objects
Jan 17, 2021
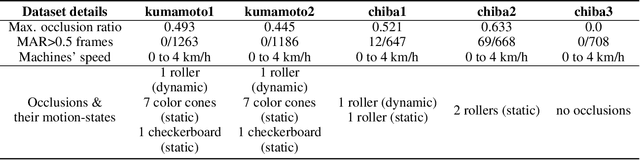


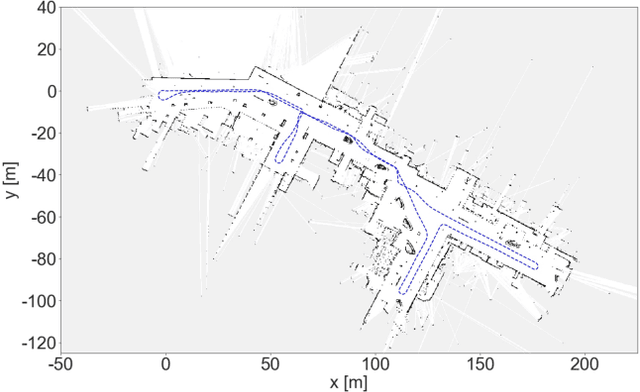
At modern construction sites, utilizing GNSS (Global Navigation Satellite System) to measure the real-time location and orientation (i.e. pose) of construction machines and navigate them is very common. However, GNSS is not always available. Replacing GNSS with on-board cameras and visual simultaneous localization and mapping (visual SLAM) to navigate the machines is a cost-effective solution. Nevertheless, at construction sites, multiple construction machines will usually work together and side-by-side, causing large dynamic occlusions in the cameras' view. Standard visual SLAM cannot handle large dynamic occlusions well. In this work, we propose a motion segmentation method to efficiently extract static parts from crowded dynamic scenes to enable robust tracking of camera ego-motion. Our method utilizes semantic information combined with object-level geometric constraints to quickly detect the static parts of the scene. Then, we perform a two-step coarse-to-fine ego-motion tracking with reference to the static parts. This leads to a novel dynamic visual SLAM formation. We test our proposals through a real implementation based on ORB-SLAM2, and datasets we collected from real construction sites. The results show that when standard visual SLAM fails, our method can still retain accurate camera ego-motion tracking in real-time. Comparing to state-of-the-art dynamic visual SLAM methods, ours shows outstanding efficiency and competitive result trajectory accuracy.
* This is an Accepted Manuscript of an article published by Taylor & Francis in Advanced Robotics on Jan. 11th, 2021, available online: https://www.tandfonline.com/doi/full/10.1080/01691864.2020.1869586 [Article DOI:10.1080/01691864.2020.1869586]
Distance Invariant Sparse Autoencoder for Wireless Signal Strength Mapping
Oct 29, 2020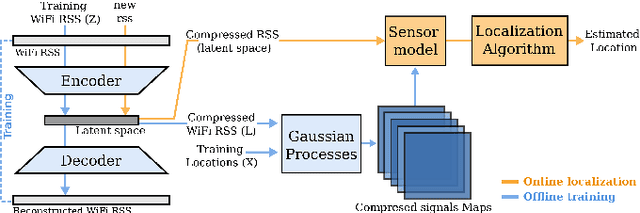
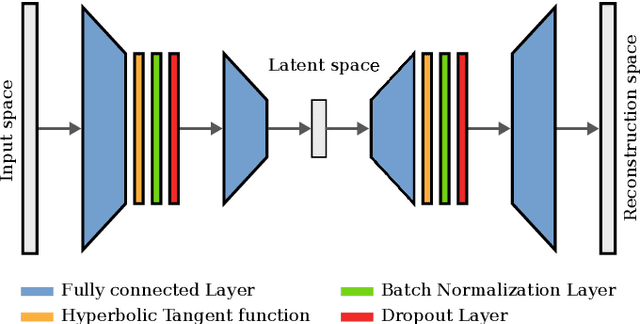
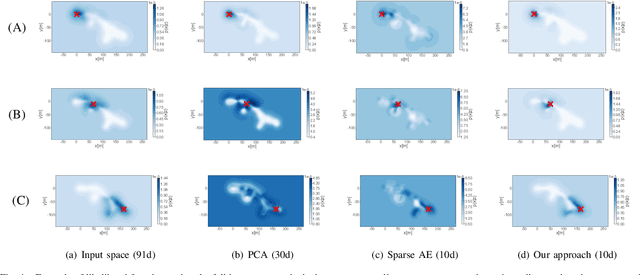
Wireless signal strength based localization can enable robust localization for robots using inexpensive sensors. For this, a location-to-signal-strength map has to be learned for each access point in the environment. Due to the ubiquity of Wireless networks in most environments, this can result in tens or hundreds of maps. To reduce the dimensionality of this problem, we employ autoencoders, which are a popular unsupervised approach for feature extraction and data compression. In particular, we propose the use of sparse autoencoders that learn latent spaces that preserve the relative distance between inputs. Distance invariance between input and latent spaces allows our system to successfully learn compact representations that allow precise data reconstruction but also have a low impact on localization performance when using maps from the latent space rather than the input space. We demonstrate the feasibility of our approach by performing experiments in outdoor environments.