 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking UML Class Diagram Understanding in Vision Language Models
May 12, 2026Although Vision Language Models (VLMs) have seen tremendous progress across all kinds of use cases, they still fall behind in answering questions regard-ing diagrams compared to photos. Although progress has been made in the area of bar charts, line charts and other diagrams like that there is still few research concerned with other types of diagrams, e.g. in the computer science domain. Our work presents a benchmark for visual question answering based on UML class diagrams which is both challenging and manageable. We further construct a large-scale training dataset with 16.000 image-question-answer triples and show that a LoRA-based finetune easily outperforms Qwen 3.5 27B, which is a recent and well-performing VLM in many other benchmarks.
SITUATE -- Synthetic Object Counting Dataset for VLM training
Jan 26, 2026We present SITUATE, a novel dataset designed for training and evaluating Vision Language Models on counting tasks with spatial constraints. The dataset bridges the gap between simple 2D datasets like VLMCountBench and often ambiguous real-life datasets like TallyQA, which lack control over occlusions and spatial composition. Experiments show that our dataset helps to improve generalization for out-of-distribution images, since a finetune of Qwen VL 2.5 7B on SITUATE improves accuracy on the Pixmo count test data, but not vice versa. We cross validate this by comparing the model performance across established other counting benchmarks and against an equally sized fine-tuning set derived from Pixmo count.
VLM@school -- Evaluation of AI image understanding on German middle school knowledge
Jun 13, 2025This paper introduces a novel benchmark dataset designed to evaluate the capabilities of Vision Language Models (VLMs) on tasks that combine visual reasoning with subject-specific background knowledge in the German language. In contrast to widely used English-language benchmarks that often rely on artificially difficult or decontextualized problems, this dataset draws from real middle school curricula across nine domains including mathematics, history, biology, and religion. The benchmark includes over 2,000 open-ended questions grounded in 486 images, ensuring that models must integrate visual interpretation with factual reasoning rather than rely on superficial textual cues. We evaluate thirteen state-of-the-art open-weight VLMs across multiple dimensions, including domain-specific accuracy and performance on adversarial crafted questions. Our findings reveal that even the strongest models achieve less than 45% overall accuracy, with particularly poor performance in music, mathematics, and adversarial settings. Furthermore, the results indicate significant discrepancies between success on popular benchmarks and real-world multimodal understanding. We conclude that middle school-level tasks offer a meaningful and underutilized avenue for stress-testing VLMs, especially in non-English contexts. The dataset and evaluation protocol serve as a rigorous testbed to better understand and improve the visual and linguistic reasoning capabilities of future AI systems.
Using LLMs as prompt modifier to avoid biases in AI image generators
Apr 15, 2025This study examines how Large Language Models (LLMs) can reduce biases in text-to-image generation systems by modifying user prompts. We define bias as a model's unfair deviation from population statistics given neutral prompts. Our experiments with Stable Diffusion XL, 3.5 and Flux demonstrate that LLM-modified prompts significantly increase image diversity and reduce bias without the need to change the image generators themselves. While occasionally producing results that diverge from original user intent for elaborate prompts, this approach generally provides more varied interpretations of underspecified requests rather than superficial variations. The method works particularly well for less advanced image generators, though limitations persist for certain contexts like disability representation. All prompts and generated images are available at https://iisys-hof.github.io/llm-prompt-img-gen/
Benchmarking Vision Language Models on German Factual Data
Apr 15, 2025Similar to LLMs, the development of vision language models is mainly driven by English datasets and models trained in English and Chinese language, whereas support for other languages, even those considered high-resource languages such as German, remains significantly weaker. In this work we present an analysis of open-weight VLMs on factual knowledge in the German and English language. We disentangle the image-related aspects from the textual ones by analyzing accu-racy with jury-as-a-judge in both prompt languages and images from German and international contexts. We found that for celebrities and sights, VLMs struggle because they are lacking visual cognition of German image contents. For animals and plants, the tested models can often correctly identify the image contents ac-cording to the scientific name or English common name but fail in German lan-guage. Cars and supermarket products were identified equally well in English and German images across both prompt languages.
Evaluation of medium-large Language Models at zero-shot closed book generative question answering
May 19, 2023Large language models (LLMs) have garnered significant attention, but the definition of "large" lacks clarity. This paper focuses on medium-sized lan-guage models (MLMs), defined as having at least six billion parameters but less than 100 billion. The study evaluates MLMs regarding zero-shot genera-tive question answering, which requires models to provide elaborate answers without external document retrieval. The paper introduces an own test da-taset and presents results from human evaluation. Results show that combin-ing the best answers from different MLMs yielded an overall correct answer rate of 82.7% which is better than the 60.9% of ChatGPT. The best MLM achieved 46.4% and has 7B parameters, which highlights the importance of using appropriate training data for fine-tuning rather than solely relying on the number of parameters. More fine-grained feedback should be used to further improve the quality of answers.
ASR Bundestag: A Large-Scale political debate dataset in German
Feb 12, 2023We present ASR Bundestag, a dataset for automatic speech recognition in German, consisting of 610 hours of aligned audio-transcript pairs for supervised training as well as 1,038 hours of unlabeled audio snippets for self-supervised learning, based on raw audio data and transcriptions from plenary sessions and committee meetings of the German parliament. In addition, we discuss utilized approaches for the automated creation of speech datasets and assess the quality of the resulting dataset based on evaluations and finetuning of a pre-trained state of the art model. We make the dataset publicly available, including all subsets.
HUI-Audio-Corpus-German: A high quality TTS dataset
Jun 11, 2021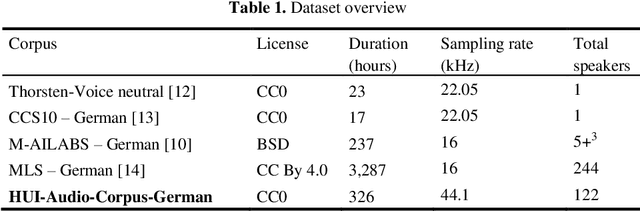
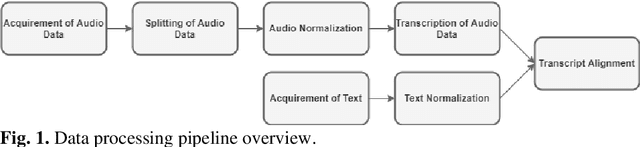
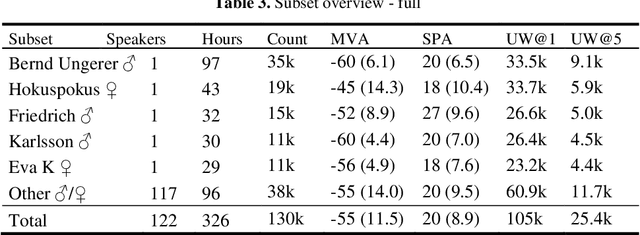
The increasing availability of audio data on the internet lead to a multitude of datasets for development and training of text to speech applications, based on neural networks. Highly differing quality of voice, low sampling rates, lack of text normalization and disadvantageous alignment of audio samples to corresponding transcript sentences still limit the performance of deep neural networks trained on this task. Additionally, data resources in languages like German are still very limited. We introduce the "HUI-Audio-Corpus-German", a large, open-source dataset for TTS engines, created with a processing pipeline, which produces high quality audio to transcription alignments and decreases manual effort needed for creation.
Sprachsynthese -- State-of-the-Art in englischer und deutscher Sprache
Jun 11, 2021Reading text aloud is an important feature for modern computer applications. It not only facilitates access to information for visually impaired people, but is also a pleasant convenience for non-impaired users. In this article, the state of the art of speech synthesis is presented separately for mel-spectrogram generation and vocoders. It concludes with an overview of available data sets for English and German with a discussion of the transferability of the good speech synthesis results from English to German language.