 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting the Undeleted in Machine Unlearning
Feb 18, 2026Machine unlearning aims to remove specific data points from a trained model, often striving to emulate "perfect retraining", i.e., producing the model that would have been obtained had the deleted data never been included. We demonstrate that this approach, and security definitions that enable it, carry significant privacy risks for the remaining (undeleted) data points. We present a reconstruction attack showing that for certain tasks, which can be computed securely without deletions, a mechanism adhering to perfect retraining allows an adversary controlling merely $ω(1)$ data points to reconstruct almost the entire dataset merely by issuing deletion requests. We survey existing definitions for machine unlearning, showing they are either susceptible to such attacks or too restrictive to support basic functionalities like exact summation. To address this problem, we propose a new security definition that specifically safeguards undeleted data against leakage caused by the deletion of other points. We show that our definition permits several essential functionalities, such as bulletin boards, summations, and statistical learning.
Transfer Learning In Differential Privacy's Hybrid-Model
Jan 28, 2022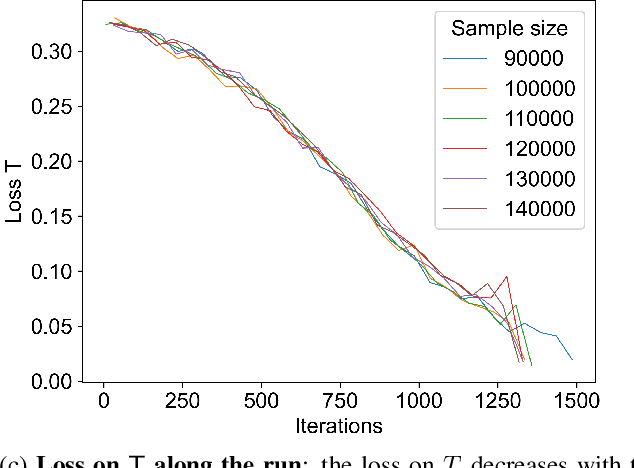
The hybrid-model (Avent et al 2017) in Differential Privacy is a an augmentation of the local-model where in addition to N local-agents we are assisted by one special agent who is in fact a curator holding the sensitive details of n additional individuals. Here we study the problem of machine learning in the hybrid-model where the n individuals in the curators dataset are drawn from a different distribution than the one of the general population (the local-agents). We give a general scheme -- Subsample-Test-Reweigh -- for this transfer learning problem, which reduces any curator-model DP-learner to a hybrid-model learner in this setting using iterative subsampling and reweighing of the n examples held by the curator based on a smooth variation of the Multiplicative-Weights algorithm (introduced by Bun et al, 2020). Our scheme has a sample complexity which relies on the chi-squared divergence between the two distributions. We give worst-case analysis bounds on the sample complexity required for our private reduction. Aiming to reduce said sample complexity, we give two specific instances our sample complexity can be drastically reduced (one instance is analyzed mathematically, while the other - empirically) and pose several directions for follow-up work.