 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment analysis for software engineering: How far can zero-shot learning (ZSL) go?
Apr 15, 2026Sentiment analysis in software engineering focuses on understanding emotions expressed in software artifacts. Previous research highlighted the limitations of applying general off-the-shelf sentiment analysis tools within the software engineering domain and indicated the need for specialized tools tailored to various software engineering contexts. The development of such tools heavily relies on supervised machine learning techniques that necessitate annotated datasets. Acquiring such datasets is a substantial challenge, as it requires domain-specific expertise and significant effort. Objective: This study explores the potential of ZSL to address the scarcity of annotated datasets in sentiment analysis within software engineering Method:} We conducted an empirical experiment to evaluate the performance of various ZSL techniques, including embedding-based, NLI-based, TARS-based, and generative-based ZSL techniques. We assessed the performance of these techniques under different labels setups to examine the impact of label configurations. Additionally, we compared the results of the ZSL techniques with state-of-the-art fine-tuned transformer-based models. Finally, we performed an error analysis to identify the primary causes of misclassifications. Results: Our findings demonstrate that ZSL techniques, particularly those combining expert-curated labels with embedding-based or generative-based models, can achieve macro-F1 scores comparable to fine-tuned transformer-based models. The error analysis revealed that subjectivity in annotation and polar facts are the main contributors to ZSL misclassifications. Conclusion: This study demonstrates the potential of ZSL for sentiment analysis in software engineering. ZSL can provide a solution to the challenge of annotated dataset scarcity by reducing reliance on annotated dataset.
Healthcare Knowledge Graph Construction: State-of-the-art, open issues, and opportunities
Jul 08, 2022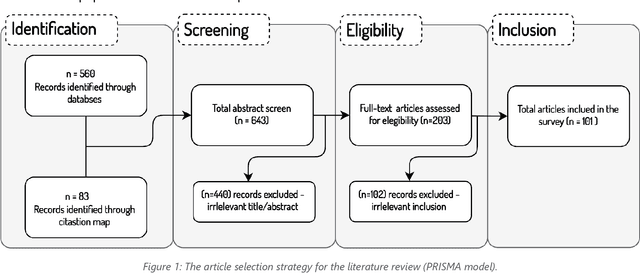
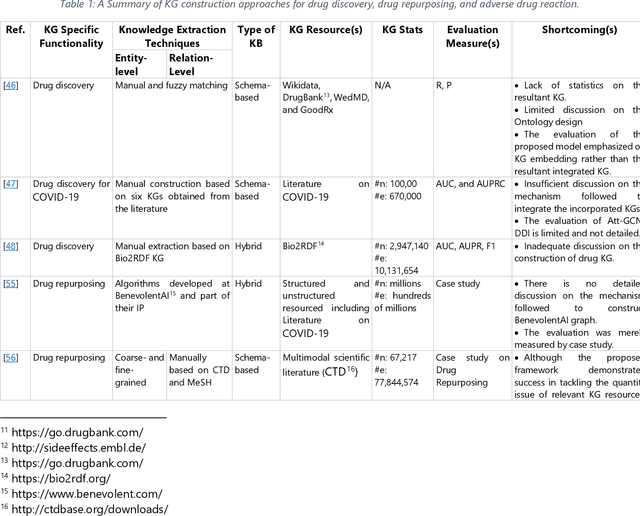
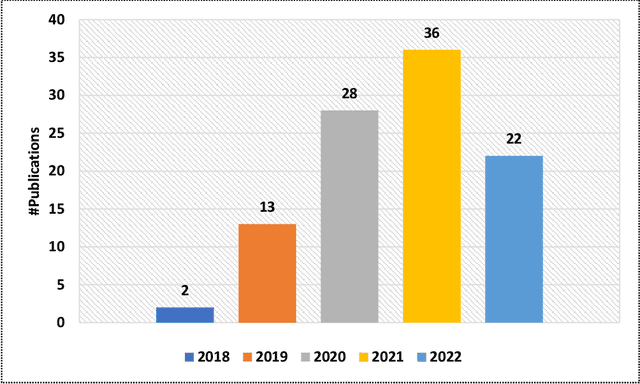
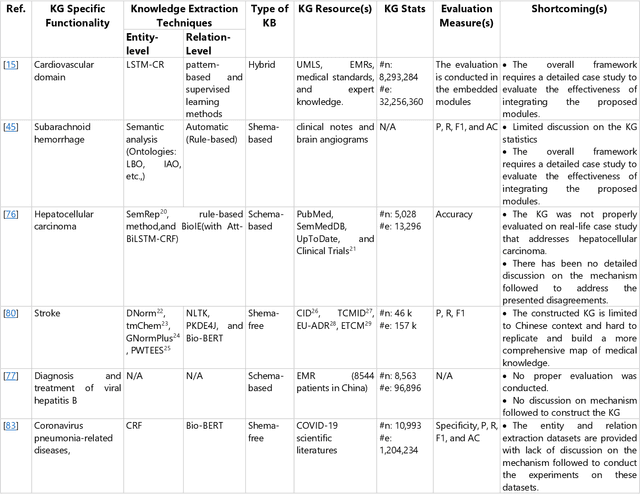
The incorporation of data analytics in the healthcare industry has made significant progress, driven by the demand for efficient and effective big data analytics solutions. Knowledge graphs (KGs) have proven utility in this arena and are rooted in a number of healthcare applications to furnish better data representation and knowledge inference. However, in conjunction with a lack of a representative KG construction taxonomy, several existing approaches in this designated domain are inadequate and inferior. This paper is the first to provide a comprehensive taxonomy and a bird's eye view of healthcare KG construction. Additionally, a thorough examination of the current state-of-the-art techniques drawn from academic works relevant to various healthcare contexts is carried out. These techniques are critically evaluated in terms of methods used for knowledge extraction, types of the knowledge base and sources, and the incorporated evaluation protocols. Finally, several research findings and existing issues in the literature are reported and discussed, opening horizons for future research in this vibrant area.