 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA systematic framework for natural perturbations from videos
Jun 05, 2019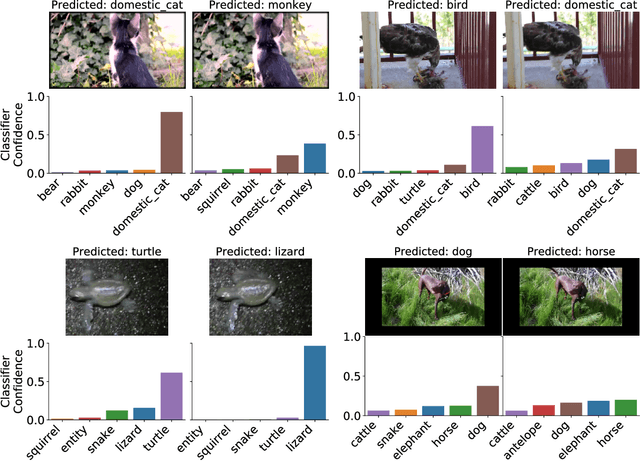
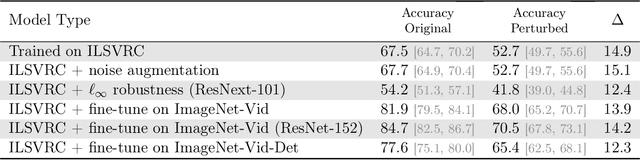

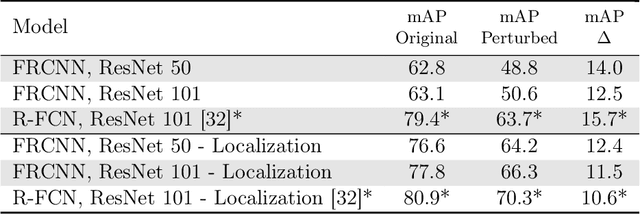
We introduce a systematic framework for quantifying the robustness of classifiers to naturally occurring perturbations of images found in videos. As part of this framework, we construct Imagenet-Video-Robust, a human-expert--reviewed dataset of 22,178 images grouped into 1,109 sets of perceptually similar images derived from frames in the ImageNet Video Object Detection dataset. We evaluate a diverse array of classifiers trained on ImageNet, including models trained for robustness, and show a median classification accuracy drop of 16%. Additionally, we evaluate the Faster R-CNN and R-FCN models for detection, and show that natural perturbations induce both classification as well as localization errors, leading to a median drop in detection mAP of 14 points. Our analysis shows that natural perturbations in the real world are heavily problematic for current CNNs, posing a significant challenge to their deployment in safety-critical environments that require reliable, low-latency predictions.
Do ImageNet Classifiers Generalize to ImageNet?
Feb 13, 2019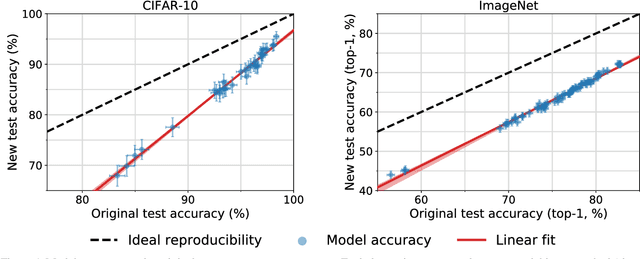
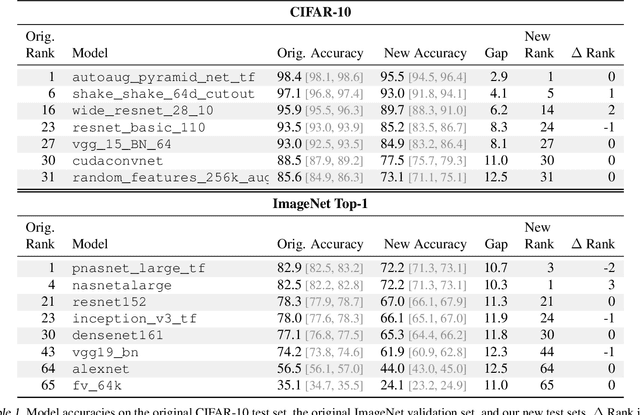
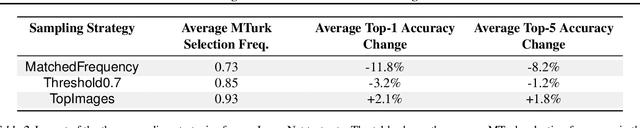
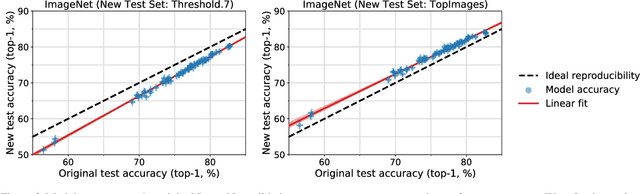
We build new test sets for the CIFAR-10 and ImageNet datasets. Both benchmarks have been the focus of intense research for almost a decade, raising the danger of overfitting to excessively re-used test sets. By closely following the original dataset creation processes, we test to what extent current classification models generalize to new data. We evaluate a broad range of models and find accuracy drops of 3% - 15% on CIFAR-10 and 11% - 14% on ImageNet. However, accuracy gains on the original test sets translate to larger gains on the new test sets. Our results suggest that the accuracy drops are not caused by adaptivity, but by the models' inability to generalize to slightly "harder" images than those found in the original test sets.
Do CIFAR-10 Classifiers Generalize to CIFAR-10?
Jun 01, 2018
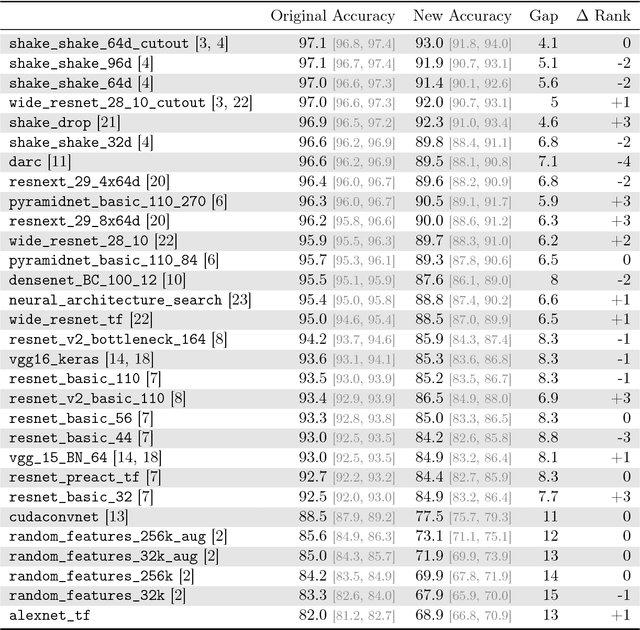
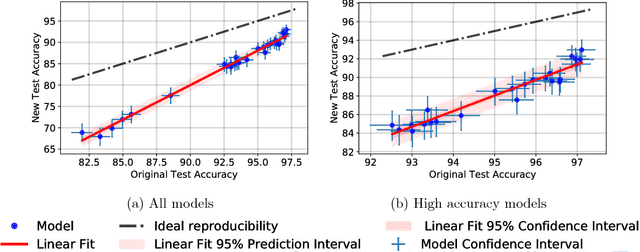

Machine learning is currently dominated by largely experimental work focused on improvements in a few key tasks. However, the impressive accuracy numbers of the best performing models are questionable because the same test sets have been used to select these models for multiple years now. To understand the danger of overfitting, we measure the accuracy of CIFAR-10 classifiers by creating a new test set of truly unseen images. Although we ensure that the new test set is as close to the original data distribution as possible, we find a large drop in accuracy (4% to 10%) for a broad range of deep learning models. Yet more recent models with higher original accuracy show a smaller drop and better overall performance, indicating that this drop is likely not due to overfitting based on adaptivity. Instead, we view our results as evidence that current accuracy numbers are brittle and susceptible to even minute natural variations in the data distribution.
The Marginal Value of Adaptive Gradient Methods in Machine Learning
May 22, 2018
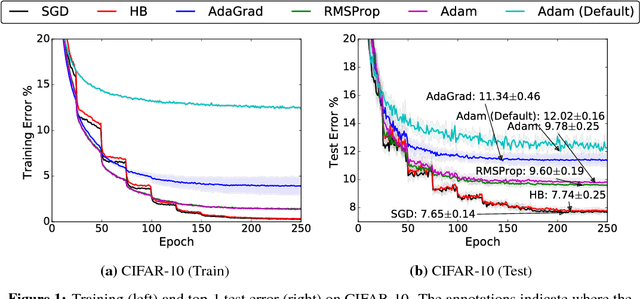

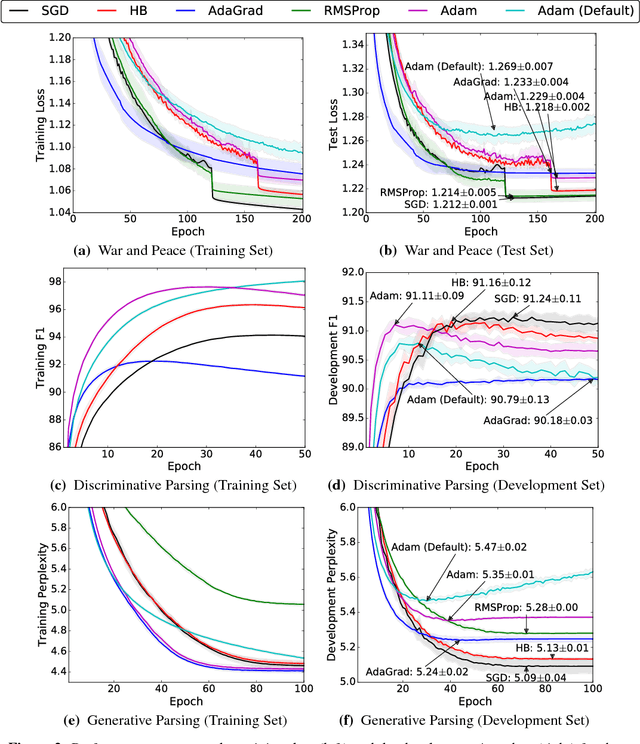
Adaptive optimization methods, which perform local optimization with a metric constructed from the history of iterates, are becoming increasingly popular for training deep neural networks. Examples include AdaGrad, RMSProp, and Adam. We show that for simple overparameterized problems, adaptive methods often find drastically different solutions than gradient descent (GD) or stochastic gradient descent (SGD). We construct an illustrative binary classification problem where the data is linearly separable, GD and SGD achieve zero test error, and AdaGrad, Adam, and RMSProp attain test errors arbitrarily close to half. We additionally study the empirical generalization capability of adaptive methods on several state-of-the-art deep learning models. We observe that the solutions found by adaptive methods generalize worse (often significantly worse) than SGD, even when these solutions have better training performance. These results suggest that practitioners should reconsider the use of adaptive methods to train neural networks.
Large Scale Kernel Learning using Block Coordinate Descent
Feb 17, 2016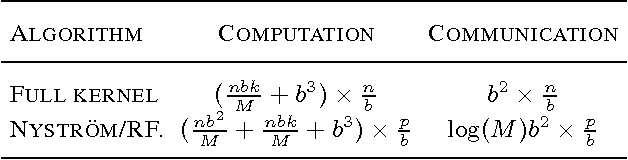
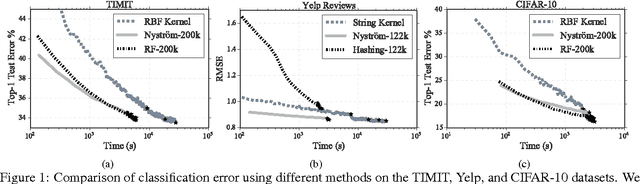
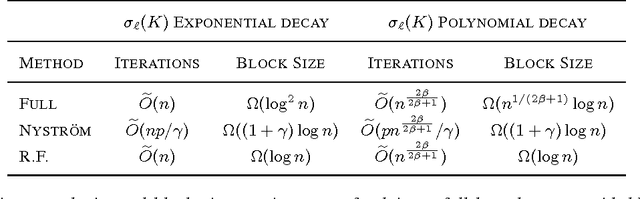
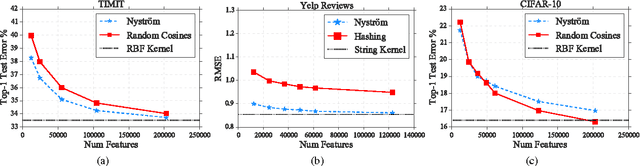
We demonstrate that distributed block coordinate descent can quickly solve kernel regression and classification problems with millions of data points. Armed with this capability, we conduct a thorough comparison between the full kernel, the Nystr\"om method, and random features on three large classification tasks from various domains. Our results suggest that the Nystr\"om method generally achieves better statistical accuracy than random features, but can require significantly more iterations of optimization. Lastly, we derive new rates for block coordinate descent which support our experimental findings when specialized to kernel methods.