 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRail break and derailment prediction using Probabilistic Graphical Modelling
Aug 25, 2022
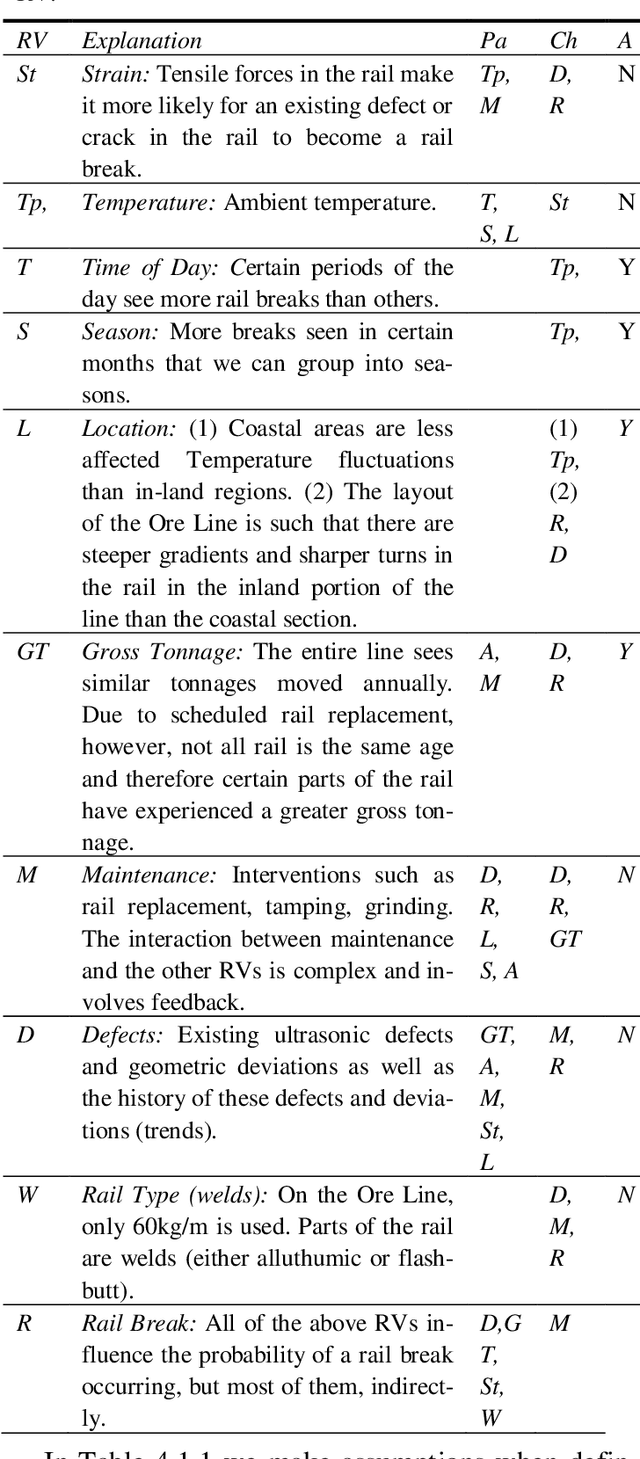
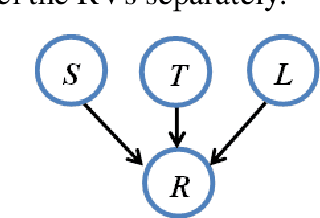

Rail breaks are one of the most common causes of derailments internationally. This is no different for the South African Iron Ore line. Many rail breaks occur as a heavy-haul train passes over a crack, large defect or defective weld. In such cases, it is usually too late for the train to slow down in time to prevent a de-railment. Knowing the risk of a rail break occurring associated with a train passing over a section of rail allows for better implementation of maintenance initiatives and mitigating measures. In this paper the Ore Line's specific challenges are discussed and the currently available data that can be used to create a rail break risk prediction model is reviewed. The development of a basic rail break risk prediction model for the Ore Line is then presented. Finally the insight gained from the model is demonstrated by means of discussing various scenarios of various rail break risk. In future work, we are planning on extending this basic model to allow input from live monitoring systems such as the ultrasonic broken rail detection system.
* Proceedings of the 11'th International Heavy Haul Association Conference 2017
SimLDA: A tool for topic model evaluation
Aug 19, 2022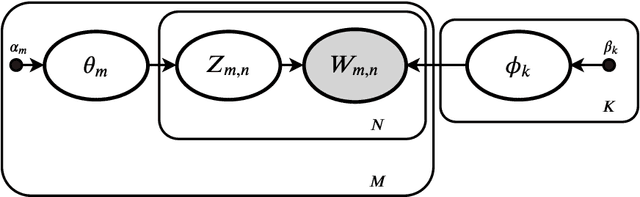
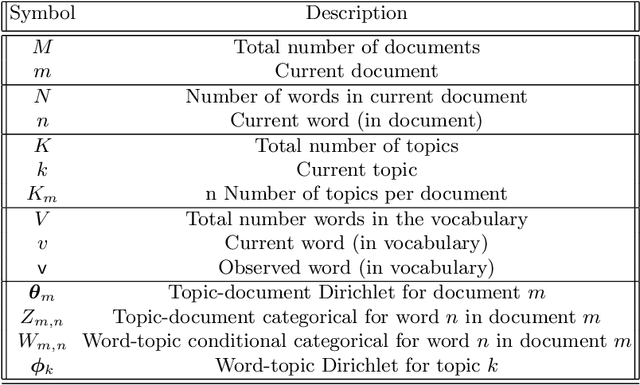
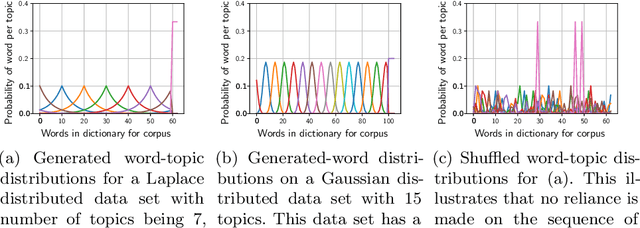
Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) has become the most popular algorithm for aspect modeling. While sufficiently successful in text topic extraction from large corpora, VB is less successful in identifying aspects in the presence of limited data. We present a novel variational message passing algorithm as applied to Latent Dirichlet Allocation (LDA) and compare it with the gold standard VB and collapsed Gibbs sampling. In situations where marginalisation leads to non-conjugate messages, we use ideas from sampling to derive approximate update equations. In cases where conjugacy holds, Loopy Belief update (LBU) (also known as Lauritzen-Spiegelhalter) is used. Our algorithm, ALBU (approximate LBU), has strong similarities with Variational Message Passing (VMP) (which is the message passing variant of VB). To compare the performance of the algorithms in the presence of limited data, we use data sets consisting of tweets and news groups. Using coherence measures we show that ALBU learns latent distributions more accurately than does VB, especially for smaller data sets.
Variational message passing (VMP) applied to LDA
Nov 02, 2021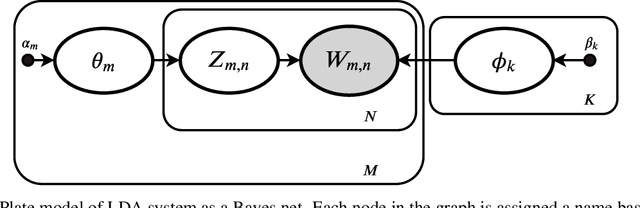
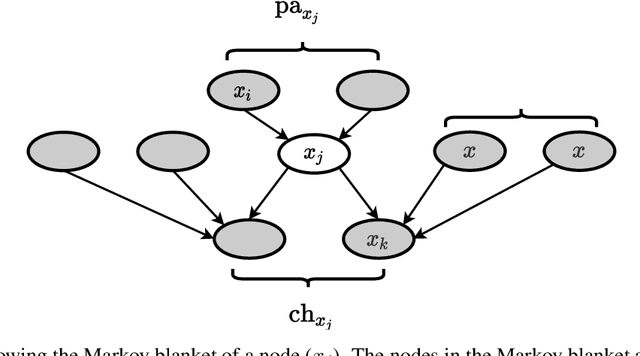
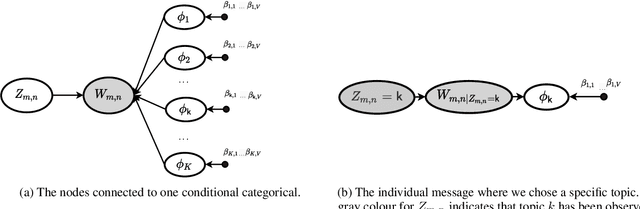
Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) is the original inference mechanism for LDA. Many variants of VB for LDA, as well as for VB in general, have been developed since LDA's inception in 2013, but standard VB is still widely applied to LDA. Variational message passing (VMP) is the message passing equivalent of VB and is a useful tool for constructing a variational inference solution for a large variety of conjugate exponential graphical models (there is also a non conjugate variant available for other models). In this article we present the VMP equations for LDA and also provide a brief discussion of the equations. We hope that this will assist others when deriving variational inference solutions to other similar graphical models.
ALBU: An approximate Loopy Belief message passing algorithm for LDA to improve performance on small data sets
Oct 01, 2021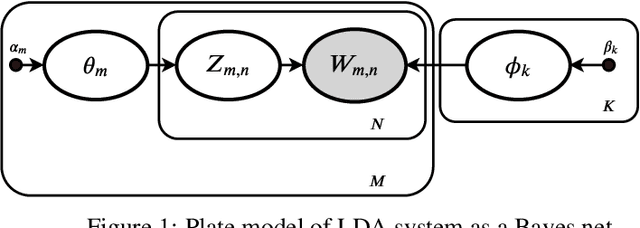

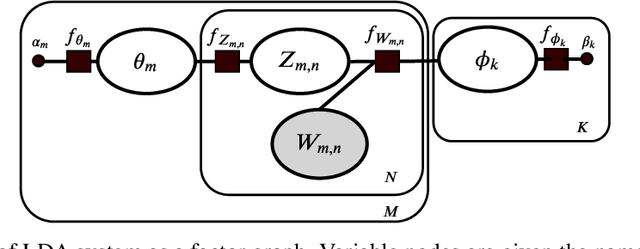

Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) has become the most popular algorithm for aspect modeling. While sufficiently successful in text topic extraction from large corpora, VB is less successful in identifying aspects in the presence of limited data. We present a novel variational message passing algorithm as applied to Latent Dirichlet Allocation (LDA) and compare it with the gold standard VB and collapsed Gibbs sampling. In situations where marginalisation leads to non-conjugate messages, we use ideas from sampling to derive approximate update equations. In cases where conjugacy holds, Loopy Belief update (LBU) (also known as Lauritzen-Spiegelhalter) is used. Our algorithm, ALBU (approximate LBU), has strong similarities with Variational Message Passing (VMP) (which is the message passing variant of VB). To compare the performance of the algorithms in the presence of limited data, we use data sets consisting of tweets and news groups. Additionally, to perform more fine grained evaluations and comparisons, we use simulations that enable comparisons with the ground truth via Kullback-Leibler divergence (KLD). Using coherence measures for the text corpora and KLD with the simulations we show that ALBU learns latent distributions more accurately than does VB, especially for smaller data sets.