 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Output Signal Detection for Cetacean Vocalizations Using Spectral Entropy, K-Means Clustering and the Continuous Wavelet Transform
Nov 22, 2022



Underwater acoustic monitoring systems record many hours of audio data for marine research, making fast and reliable non-causal signal detection paramount. Such detectors assist in reducing the amount of labor required for signal annotations, which often contain large portions devoid of signals. Cetacean vocalization detection based on spectral entropy is investigated as a means of vocalization discovery. Previous techniques using spectral entropy (SE) mostly consider time-frequency enhancement of the entropy measure, and utilize the STFT as its time-frequency (TF) decomposition. SE methods also requires the user to set a detection threshold manually, which call for knowledge of the produced entropy measures. This paper considers median filtering as a simple, effective way to provide temporal stabilization to the entropy measure, and considers the CWT as an alternative TF decomposition. K-means clustering is used to determine the threshold required to accurately separate the signal/no-signal entropy measures, resulting in a one-dimensional, two-class classification problem. The class means are used to perform pseudo-probabilistic soft class assignment, which is a useful metric in algorithmic development. The effect of median filtering, signal-to-noise ratio and the chosen TF decomposition are investigated. The proposed method shows a significant improvement in detection accuracy and specificity, while also providing a more interpretable detection threshold setting via soft class assignment.
Rail break and derailment prediction using Probabilistic Graphical Modelling
Aug 25, 2022
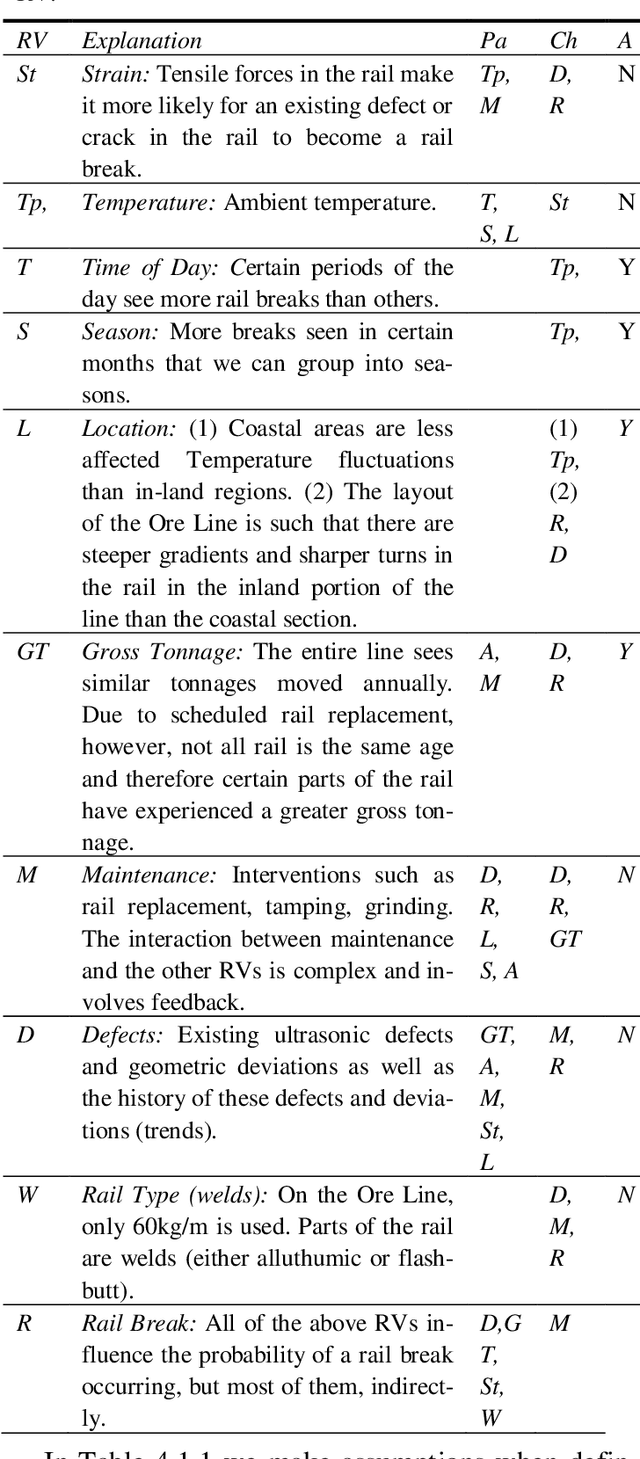
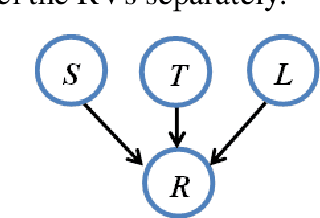

Rail breaks are one of the most common causes of derailments internationally. This is no different for the South African Iron Ore line. Many rail breaks occur as a heavy-haul train passes over a crack, large defect or defective weld. In such cases, it is usually too late for the train to slow down in time to prevent a de-railment. Knowing the risk of a rail break occurring associated with a train passing over a section of rail allows for better implementation of maintenance initiatives and mitigating measures. In this paper the Ore Line's specific challenges are discussed and the currently available data that can be used to create a rail break risk prediction model is reviewed. The development of a basic rail break risk prediction model for the Ore Line is then presented. Finally the insight gained from the model is demonstrated by means of discussing various scenarios of various rail break risk. In future work, we are planning on extending this basic model to allow input from live monitoring systems such as the ultrasonic broken rail detection system.
* Proceedings of the 11'th International Heavy Haul Association Conference 2017
SimLDA: A tool for topic model evaluation
Aug 19, 2022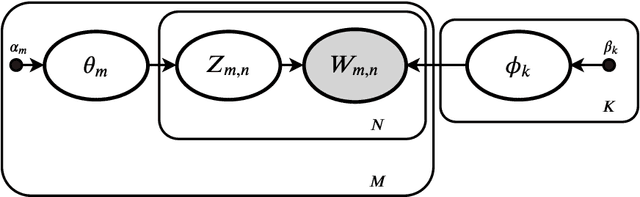
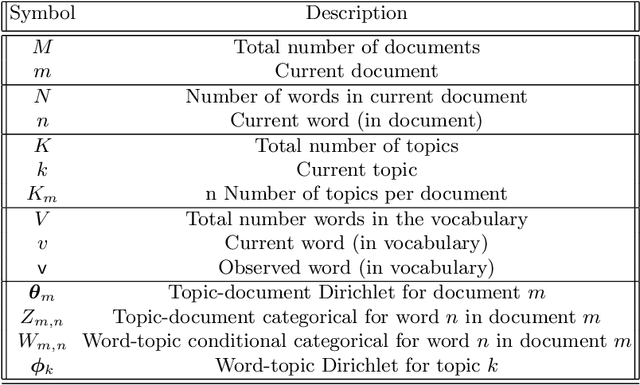
Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) has become the most popular algorithm for aspect modeling. While sufficiently successful in text topic extraction from large corpora, VB is less successful in identifying aspects in the presence of limited data. We present a novel variational message passing algorithm as applied to Latent Dirichlet Allocation (LDA) and compare it with the gold standard VB and collapsed Gibbs sampling. In situations where marginalisation leads to non-conjugate messages, we use ideas from sampling to derive approximate update equations. In cases where conjugacy holds, Loopy Belief update (LBU) (also known as Lauritzen-Spiegelhalter) is used. Our algorithm, ALBU (approximate LBU), has strong similarities with Variational Message Passing (VMP) (which is the message passing variant of VB). To compare the performance of the algorithms in the presence of limited data, we use data sets consisting of tweets and news groups. Using coherence measures we show that ALBU learns latent distributions more accurately than does VB, especially for smaller data sets.
Variational message passing (VMP) applied to LDA
Nov 02, 2021
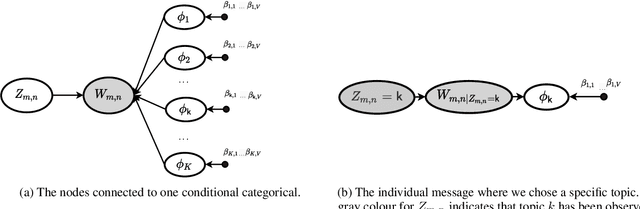
Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) is the original inference mechanism for LDA. Many variants of VB for LDA, as well as for VB in general, have been developed since LDA's inception in 2013, but standard VB is still widely applied to LDA. Variational message passing (VMP) is the message passing equivalent of VB and is a useful tool for constructing a variational inference solution for a large variety of conjugate exponential graphical models (there is also a non conjugate variant available for other models). In this article we present the VMP equations for LDA and also provide a brief discussion of the equations. We hope that this will assist others when deriving variational inference solutions to other similar graphical models.
Automated Feature-Specific Tree Species Identification from Natural Images using Deep Semi-Supervised Learning
Oct 08, 2021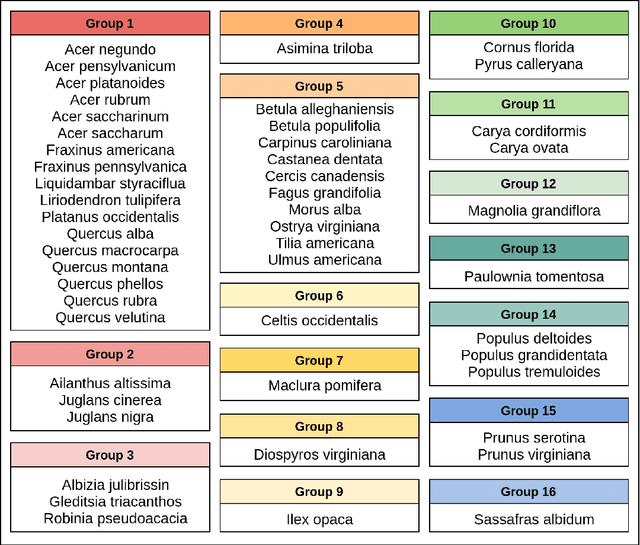
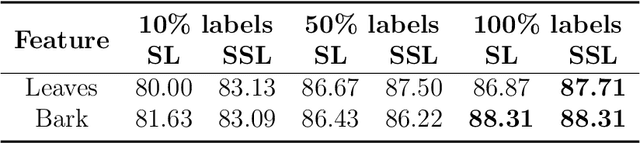

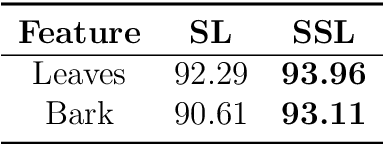
Prior work on plant species classification predominantly focuses on building models from isolated plant attributes. Hence, there is a need for tools that can assist in species identification in the natural world. We present a novel and robust two-fold approach capable of identifying trees in a real-world natural setting. Further, we leverage unlabelled data through deep semi-supervised learning and demonstrate superior performance to supervised learning. Our single-GPU implementation for feature recognition uses minimal annotated data and achieves accuracies of 93.96% and 93.11% for leaves and bark, respectively. Further, we extract feature-specific datasets of 50 species by employing this technique. Finally, our semi-supervised species classification method attains 94.04% top-5 accuracy for leaves and 83.04% top-5 accuracy for bark.
ALBU: An approximate Loopy Belief message passing algorithm for LDA to improve performance on small data sets
Oct 01, 2021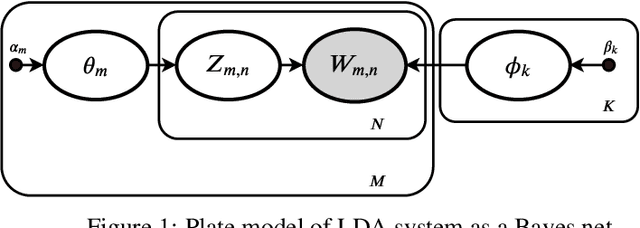

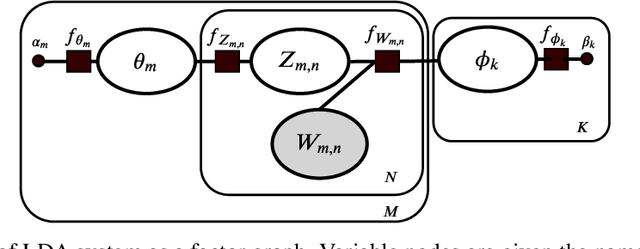

Variational Bayes (VB) applied to latent Dirichlet allocation (LDA) has become the most popular algorithm for aspect modeling. While sufficiently successful in text topic extraction from large corpora, VB is less successful in identifying aspects in the presence of limited data. We present a novel variational message passing algorithm as applied to Latent Dirichlet Allocation (LDA) and compare it with the gold standard VB and collapsed Gibbs sampling. In situations where marginalisation leads to non-conjugate messages, we use ideas from sampling to derive approximate update equations. In cases where conjugacy holds, Loopy Belief update (LBU) (also known as Lauritzen-Spiegelhalter) is used. Our algorithm, ALBU (approximate LBU), has strong similarities with Variational Message Passing (VMP) (which is the message passing variant of VB). To compare the performance of the algorithms in the presence of limited data, we use data sets consisting of tweets and news groups. Additionally, to perform more fine grained evaluations and comparisons, we use simulations that enable comparisons with the ground truth via Kullback-Leibler divergence (KLD). Using coherence measures for the text corpora and KLD with the simulations we show that ALBU learns latent distributions more accurately than does VB, especially for smaller data sets.
Introduction to quasi-open set semi-supervised learning for big data analytics
Feb 04, 2020

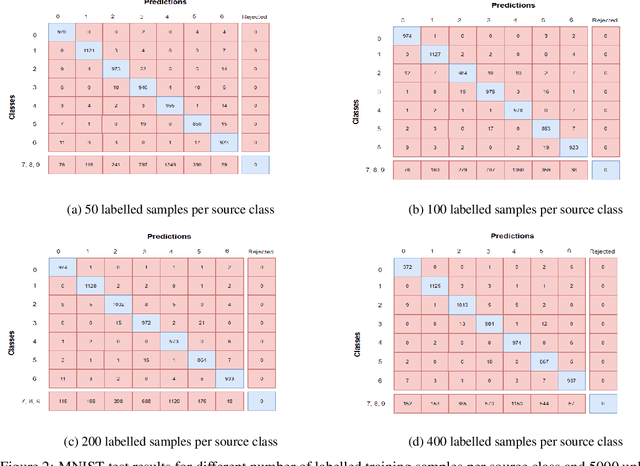
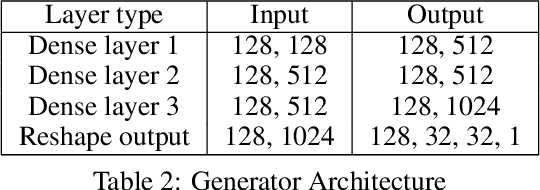
State-of-the-art performance and low system complexity has made deep-learning an increasingly attractive solution for big data analytics. However, limiting assumptions of end-to-end learning regimes hinder the use of neural networks on large application-grade datasets. This work addresses the assumption that output class-labels are defined for all classes in the domain. The amount of data collected by modern-day sensors span over an incomprehensible range of potential classes. Therefore, we propose a new learning regime where only some, but not all, classes of the training data are of interest to the classification system. The semi-supervised learning scenario in big data requires the assumption of a partial class mismatch between labelled and unlabelled training data. With classification systems required to classify source classes indicated by labelled samples while separating novel classes indicated by unlabelled samples, we find ourselves in an open-set case (vs closed set with only source classes). However, introducing samples from novel classes into the training set indicates a more relaxed open-set case. As such, our proposed regime of \textit{quasi-open set semi-supervised learning} is introduced. We propose a suitable method to train under quasi-open set semi-supervised learning that makes use of Wasserstein generative adversarial networks (WGANs). A trained classification certainty estimation within the discriminator (or critic) network is used to enable a reject option for the classifier. By placing a threshold on this certainty estimation, the reject option accepts classifications of source classes and rejects novel classes. Big data end-to-end training is promoted by developing models that recognize input samples do not necessarily belong to output labels. We believe this essential for big data analytics, and urge more work under quasi-open set semi-supervised learning.