 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadratic integrate-and-fire neurons exhibit less fragmented loss landscapes and outperform leaky integrate-and-fire neurons in spike-based gradient descent
Jun 02, 2026The ability to train spiking neural networks is essential for modeling biological neural networks as well as for neuromorphic computing. However, for the extensively used leaky integrate-and-fire (LIF) neurons, arbitrarily small parameter changes can induce spike (dis)appearances that disrupt subsequent activity, leading to unstable neural representations and permanently silent neurons during exact spike-based gradient descent. Recent work shows that a class of neuron models, which includes the quadratic integrate-and-fire (QIF) neuron, avoids these discontinuities and enables continuous and even smooth spike-based gradient descent. However, it remains unclear whether these advantages translate into practice. Here, we demonstrate that they do so via a controlled comparison between networks of LIF and QIF neurons on the popular Spiking Heidelberg Digits dataset. Specifically, in a first step, we perform a thorough hyperparameter search to optimize both models, revealing a clear performance advantage of QIF neurons. In a second step, we visualize the loss and gradient landscapes. Consistent with their inferior performance, we find that the loss landscapes of LIF neurons, which are discontinuous, appear more fragmented and the related gradients more erratic. An analysis of the landscapes of single samples indicates that these features arise from changes in the temporal order of spikes, which often cause disruptive spike (dis)appearances. Overall, our results advocate replacing LIF neurons with neuron models exhibiting continuous spiking dynamics, such as QIF neurons, for gradient descent training.
A generalized neural tangent kernel for surrogate gradient learning
May 24, 2024



State-of-the-art neural network training methods depend on the gradient of the network function. Therefore, they cannot be applied to networks whose activation functions do not have useful derivatives, such as binary and discrete-time spiking neural networks. To overcome this problem, the activation function's derivative is commonly substituted with a surrogate derivative, giving rise to surrogate gradient learning (SGL). This method works well in practice but lacks theoretical foundation. The neural tangent kernel (NTK) has proven successful in the analysis of gradient descent. Here, we provide a generalization of the NTK, which we call the surrogate gradient NTK, that enables the analysis of SGL. First, we study a naive extension of the NTK to activation functions with jumps, demonstrating that gradient descent for such activation functions is also ill-posed in the infinite-width limit. To address this problem, we generalize the NTK to gradient descent with surrogate derivatives, i.e., SGL. We carefully define this generalization and expand the existing key theorems on the NTK with mathematical rigor. Further, we illustrate our findings with numerical experiments. Finally, we numerically compare SGL in networks with sign activation function and finite width to kernel regression with the surrogate gradient NTK; the results confirm that the surrogate gradient NTK provides a good characterization of SGL.
Smooth Exact Gradient Descent Learning in Spiking Neural Networks
Sep 25, 2023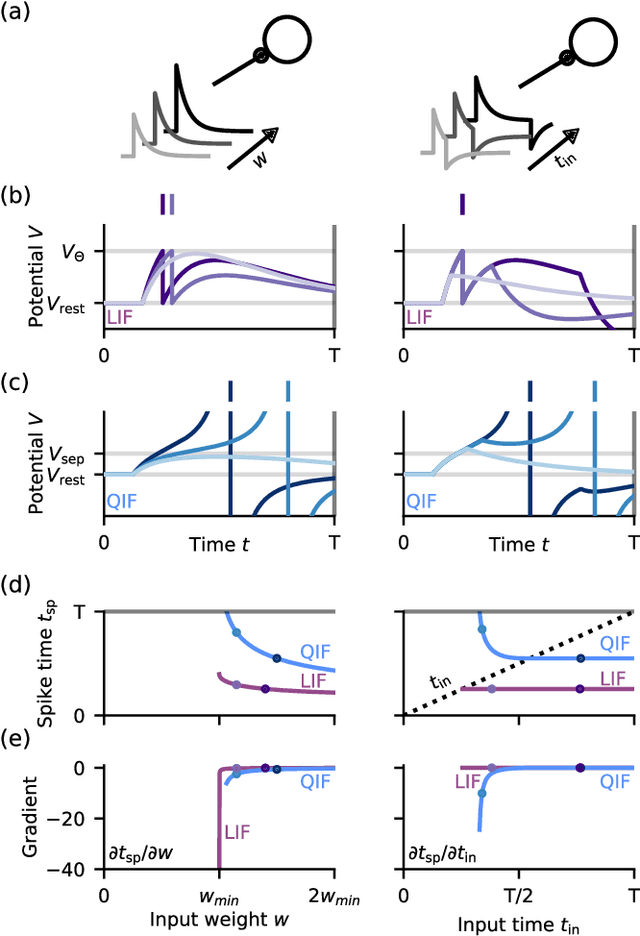
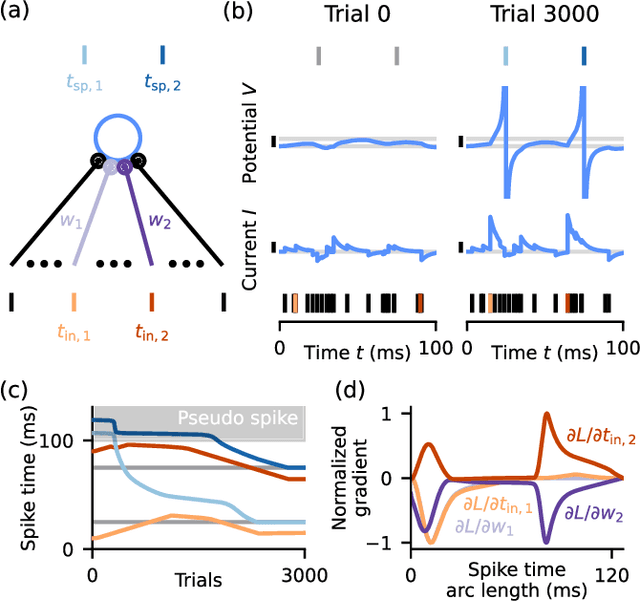
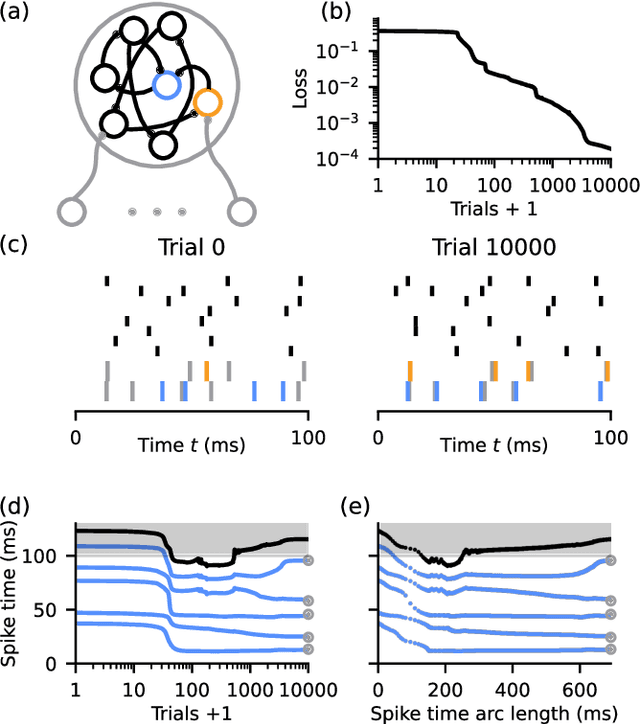
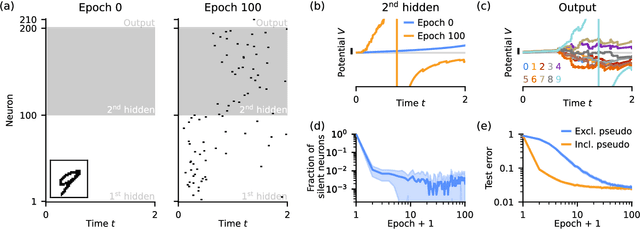
Artificial neural networks are highly successfully trained with backpropagation. For spiking neural networks, however, a similar gradient descent scheme seems prohibitive due to the sudden, disruptive (dis-)appearance of spikes. Here, we demonstrate exact gradient descent learning based on spiking dynamics that change only continuously. These are generated by neuron models whose spikes vanish and appear at the end of a trial, where they do not influence other neurons anymore. This also enables gradient-based spike addition and removal. We apply our learning scheme to induce and continuously move spikes to desired times, in single neurons and recurrent networks. Further, it achieves competitive performance in a benchmark task using deep, initially silent networks. Our results show how non-disruptive learning is possible despite discrete spikes.