 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting Prosody in the Wild: A Content-Controlled, Privacy-First Smartphone Protocol and Empirical Evaluation
Mar 17, 2026Collecting everyday speech data for prosodic analysis is challenging due to the confounding of prosody and semantics, privacy constraints, and participant compliance. We introduce and empirically evaluate a content-controlled, privacy-first smartphone protocol that uses scripted read-aloud sentences to standardize lexical content (including prompt valence) while capturing natural variation in prosodic delivery. The protocol performs on-device prosodic feature extraction, deletes raw audio immediately, and transmits only derived features for analysis. We deployed the protocol in a large study (N = 560; 9,877 recordings), evaluated compliance and data quality, and conducted diagnostic prediction tasks on the extracted features, predicting speaker sex and concurrently reported momentary affective states (valence, arousal). We discuss implications and directions for advancing and deploying the protocol.
Component-Wise Boosting of Targets for Multi-Output Prediction
Apr 08, 2019
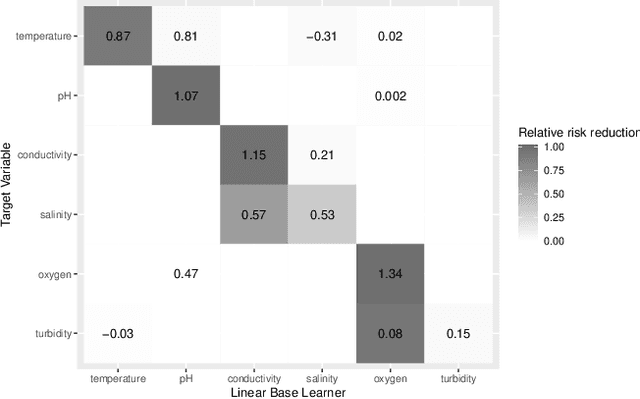

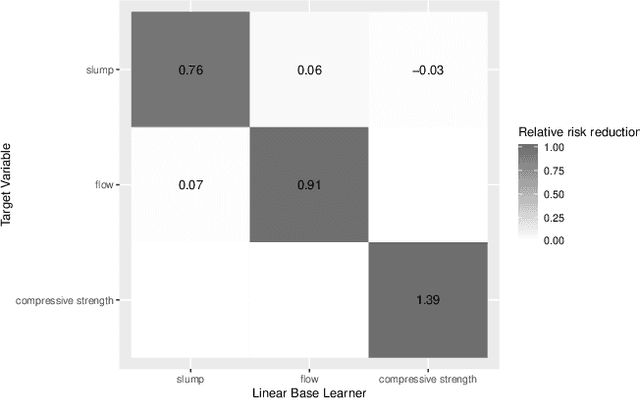
Multi-output prediction deals with the prediction of several targets of possibly diverse types. One way to address this problem is the so called problem transformation method. This method is often used in multi-label learning, but can also be used for multi-output prediction due to its generality and simplicity. In this paper, we introduce an algorithm that uses the problem transformation method for multi-output prediction, while simultaneously learning the dependencies between target variables in a sparse and interpretable manner. In a first step, predictions are obtained for each target individually. Target dependencies are then learned via a component-wise boosting approach. We compare our new method with similar approaches in a benchmark using multi-label, multivariate regression and mixed-type datasets.