 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Recovery in the Data Block Model
Feb 05, 2026Community detection in networks is a fundamental problem in machine learning and statistical inference, with applications in social networks, biological systems, and communication networks. The stochastic block model (SBM) serves as a canonical framework for studying community structure, and exact recovery, identifying the true communities with high probability, is a central theoretical question. While classical results characterize the phase transition for exact recovery based solely on graph connectivity, many real-world networks contain additional data, such as node attributes or labels. In this work, we study exact recovery in the Data Block Model (DBM), an SBM augmented with node-associated data, as formalized by Asadi, Abbe, and Verdú (2017). We introduce the Chernoff--TV divergence and use it to characterize a sharp exact recovery threshold for the DBM. We further provide an efficient algorithm that achieves this threshold, along with a matching converse result showing impossibility below the threshold. Finally, simulations validate our findings and demonstrate the benefits of incorporating vertex data as side information in community detection.
A High-Performance External Validity Index for Clustering with a Large Number of Clusters
Sep 22, 2024This paper introduces the Stable Matching Based Pairing (SMBP) algorithm, a high-performance external validity index for clustering evaluation in large-scale datasets with a large number of clusters. SMBP leverages the stable matching framework to pair clusters across different clustering methods, significantly reducing computational complexity to $O(N^2)$, compared to traditional Maximum Weighted Matching (MWM) with $O(N^3)$ complexity. Through comprehensive evaluations on real-world and synthetic datasets, SMBP demonstrates comparable accuracy to MWM and superior computational efficiency. It is particularly effective for balanced, unbalanced, and large-scale datasets with a large number of clusters, making it a scalable and practical solution for modern clustering tasks. Additionally, SMBP is easily implementable within machine learning frameworks like PyTorch and TensorFlow, offering a robust tool for big data applications. The algorithm is validated through extensive experiments, showcasing its potential as a powerful alternative to existing methods such as Maximum Match Measure (MMM) and Centroid Ratio (CR).
Clustering Using Isoperimetric Number of Trees
Mar 19, 2012


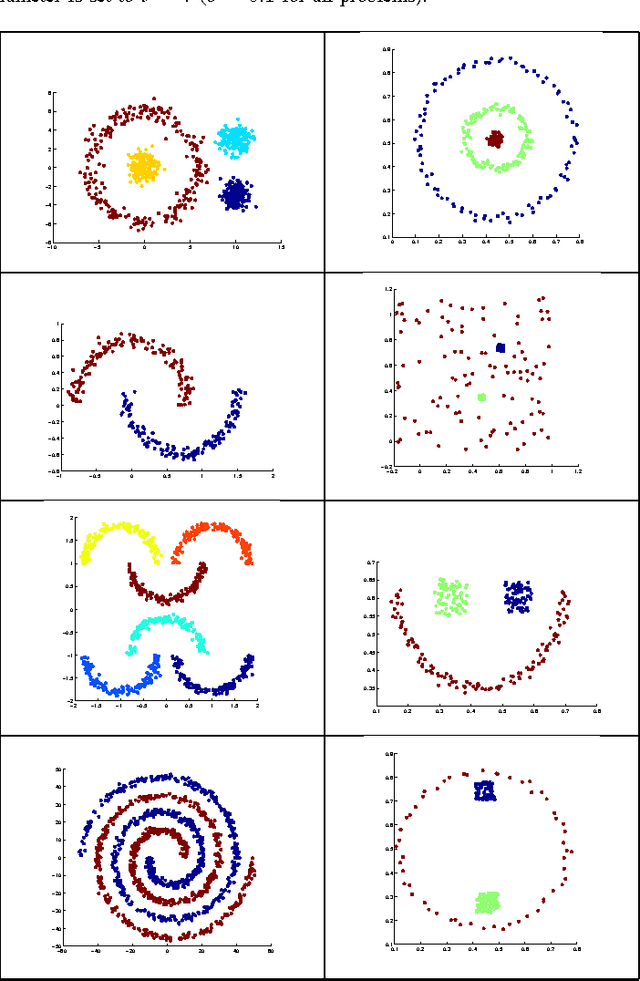
In this paper we propose a graph-based data clustering algorithm which is based on exact clustering of a minimum spanning tree in terms of a minimum isoperimetry criteria. We show that our basic clustering algorithm runs in $O(n \log n)$ and with post-processing in $O(n^2)$ (worst case) time where $n$ is the size of the data set. We also show that our generalized graph model which also allows the use of potentials at vertices can be used to extract a more detailed pack of information as the {\it outlier profile} of the data set. In this direction we show that our approach can be used to define the concept of an outlier-set in a precise way and we propose approximation algorithms for finding such sets. We also provide a comparative performance analysis of our algorithm with other related ones and we show that the new clustering algorithm (without the outlier extraction procedure) behaves quite effectively even on hard benchmarks and handmade examples.