 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Fairness in Predictions Using Bias Parity Score Based Loss Function Regularization
Nov 05, 2021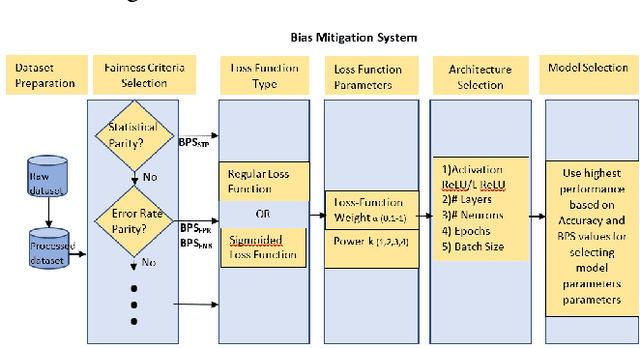
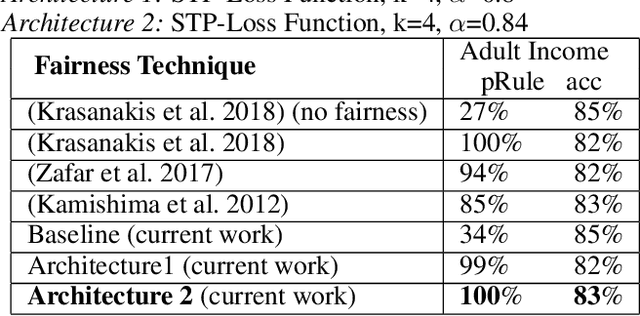
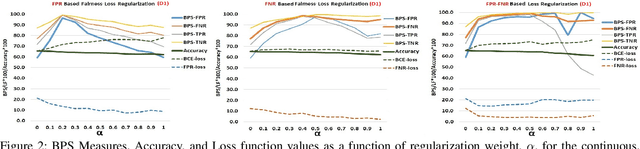
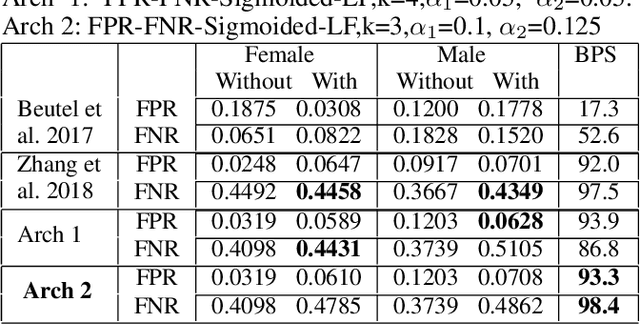
Increasing utilization of machine learning based decision support systems emphasizes the need for resulting predictions to be both accurate and fair to all stakeholders. In this work we present a novel approach to increase a Neural Network model's fairness during training. We introduce a family of fairness enhancing regularization components that we use in conjunction with the traditional binary-cross-entropy based accuracy loss. These loss functions are based on Bias Parity Score (BPS), a score that helps quantify bias in the models with a single number. In the current work we investigate the behavior and effect of these regularization components on bias. We deploy them in the context of a recidivism prediction task as well as on a census-based adult income dataset. The results demonstrate that with a good choice of fairness loss function we can reduce the trained model's bias without deteriorating accuracy even in unbalanced dataset.
Scalable Deep Traffic Flow Neural Networks for Urban Traffic Congestion Prediction
Mar 03, 2017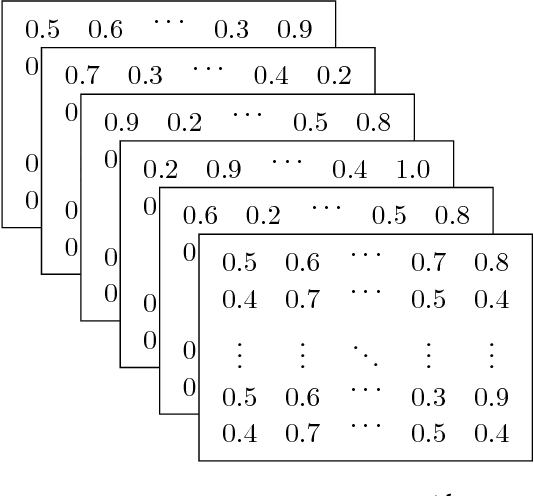
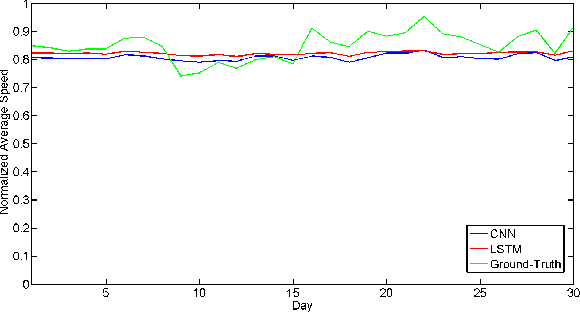
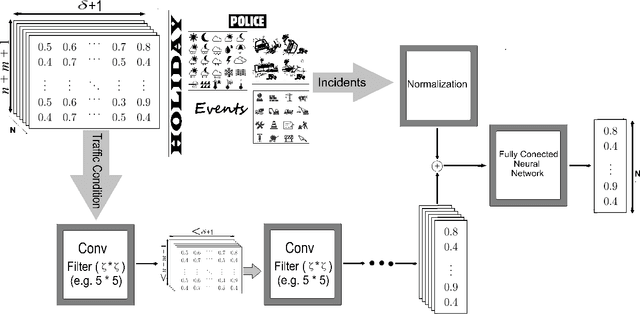
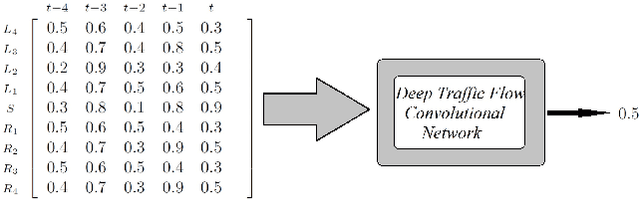
Tracking congestion throughout the network road is a critical component of Intelligent transportation network management systems. Understanding how the traffic flows and short-term prediction of congestion occurrence due to rush-hour or incidents can be beneficial to such systems to effectively manage and direct the traffic to the most appropriate detours. Many of the current traffic flow prediction systems are designed by utilizing a central processing component where the prediction is carried out through aggregation of the information gathered from all measuring stations. However, centralized systems are not scalable and fail provide real-time feedback to the system whereas in a decentralized scheme, each node is responsible to predict its own short-term congestion based on the local current measurements in neighboring nodes. We propose a decentralized deep learning-based method where each node accurately predicts its own congestion state in real-time based on the congestion state of the neighboring stations. Moreover, historical data from the deployment site is not required, which makes the proposed method more suitable for newly installed stations. In order to achieve higher performance, we introduce a regularized Euclidean loss function that favors high congestion samples over low congestion samples to avoid the impact of the unbalanced training dataset. A novel dataset for this purpose is designed based on the traffic data obtained from traffic control stations in northern California. Extensive experiments conducted on the designed benchmark reflect a successful congestion prediction.