 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUINT: Node embedding using network hashing
Sep 11, 2021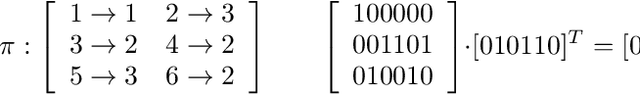
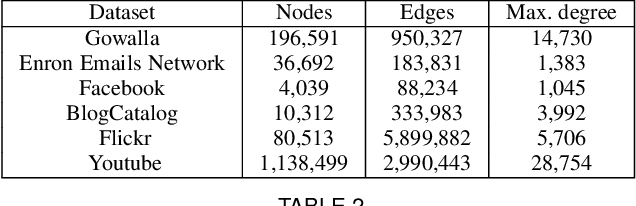
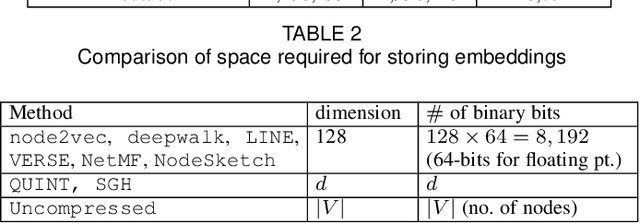
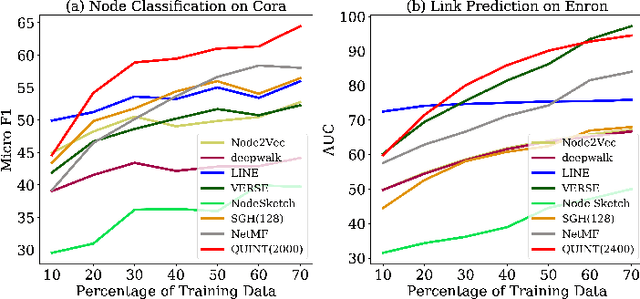
Representation learning using network embedding has received tremendous attention due to its efficacy to solve downstream tasks. Popular embedding methods (such as deepwalk, node2vec, LINE) are based on a neural architecture, thus unable to scale on large networks both in terms of time and space usage. Recently, we proposed BinSketch, a sketching technique for compressing binary vectors to binary vectors. In this paper, we show how to extend BinSketch and use it for network hashing. Our proposal named QUINT is built upon BinSketch, and it embeds nodes of a sparse network onto a low-dimensional space using simple bi-wise operations. QUINT is the first of its kind that provides tremendous gain in terms of speed and space usage without compromising much on the accuracy of the downstream tasks. Extensive experiments are conducted to compare QUINT with seven state-of-the-art network embedding methods for two end tasks - link prediction and node classification. We observe huge performance gain for QUINT in terms of speedup (up to 7000x) and space saving (up to 80x) due to its bit-wise nature to obtain node embedding. Moreover, QUINT is a consistent top-performer for both the tasks among the baselines across all the datasets. Our empirical observations are backed by rigorous theoretical analysis to justify the effectiveness of QUINT. In particular, we prove that QUINT retains enough structural information which can be used further to approximate many topological properties of networks with high confidence.
On Subspace Approximation and Subset Selection in Fewer Passes by MCMC Sampling
Mar 20, 2021We consider the problem of subset selection for $\ell_{p}$ subspace approximation, i.e., given $n$ points in $d$ dimensions, we need to pick a small, representative subset of the given points such that its span gives $(1+\epsilon)$ approximation to the best $k$-dimensional subspace that minimizes the sum of $p$-th powers of distances of all the points to this subspace. Sampling-based subset selection techniques require adaptive sampling iterations with multiple passes over the data. Matrix sketching techniques give a single-pass $(1+\epsilon)$ approximation for $\ell_{p}$ subspace approximation but require additional passes for subset selection. In this work, we propose an MCMC algorithm to reduce the number of passes required by previous subset selection algorithms based on adaptive sampling. For $p=2$, our algorithm gives subset selection of nearly optimal size in only $2$ passes, whereas the number of passes required in previous work depend on $k$. Our algorithm picks a subset of size $\mathrm{poly}(k/\epsilon)$ that gives $(1+\epsilon)$ approximation to the optimal subspace. The running time of the algorithm is $nd + d~\mathrm{poly}(k/\epsilon)$. We extend our results to the case when outliers are present in the datasets, and suggest a two pass algorithm for the same. Our ideas also extend to give a reduction in the number of passes required by adaptive sampling algorithms for $\ell_{p}$ subspace approximation and subset selection, for $p \geq 2$.
IHashNet: Iris Hashing Network based on efficient multi-index hashing
Dec 07, 2020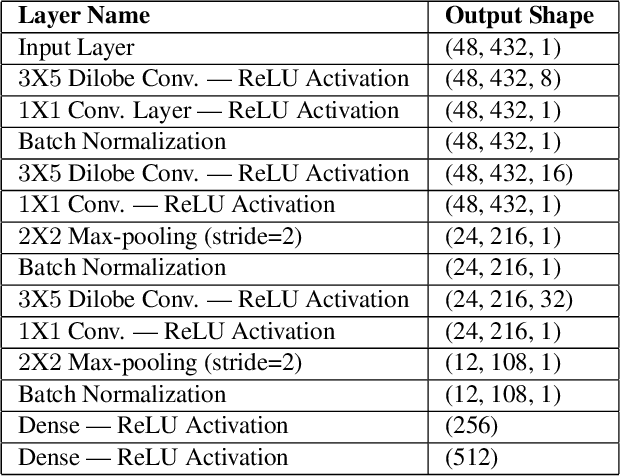
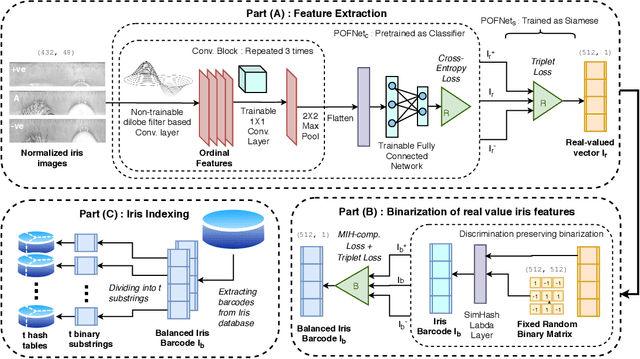
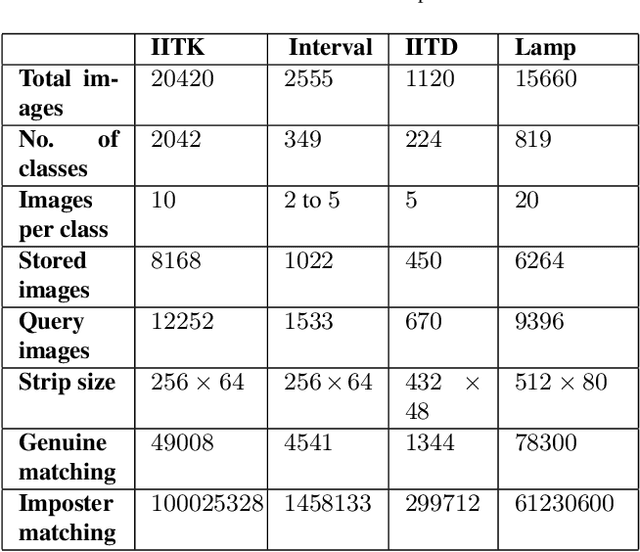
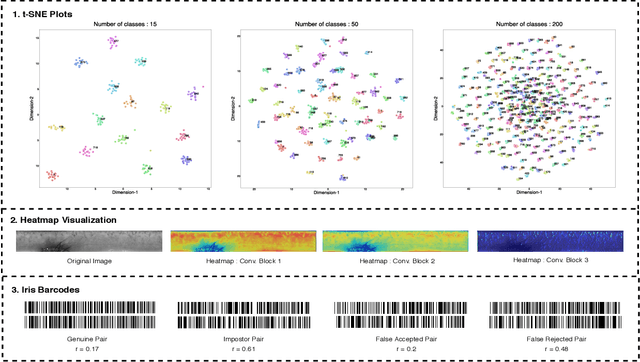
Massive biometric deployments are pervasive in today's world. But despite the high accuracy of biometric systems, their computational efficiency degrades drastically with an increase in the database size. Thus, it is essential to index them. An ideal indexing scheme needs to generate codes that preserve the intra-subject similarity as well as inter-subject dissimilarity. Here, in this paper, we propose an iris indexing scheme using real-valued deep iris features binarized to iris bar codes (IBC) compatible with the indexing structure. Firstly, for extracting robust iris features, we have designed a network utilizing the domain knowledge of ordinal filtering and learning their nonlinear combinations. Later these real-valued features are binarized. Finally, for indexing the iris dataset, we have proposed a loss that can transform the binary feature into an improved feature compatible with the Multi-Index Hashing scheme. This loss function ensures the hamming distance equally distributed among all the contiguous disjoint sub-strings. To the best of our knowledge, this is the first work in the iris indexing domain that presents an end-to-end iris indexing structure. Experimental results on four datasets are presented to depict the efficacy of the proposed approach.
Subspace approximation with outliers
Jun 30, 2020The subspace approximation problem with outliers, for given $n$ points in $d$ dimensions $x_{1},\ldots, x_{n} \in R^{d}$, an integer $1 \leq k \leq d$, and an outlier parameter $0 \leq \alpha \leq 1$, is to find a $k$-dimensional linear subspace of $R^{d}$ that minimizes the sum of squared distances to its nearest $(1-\alpha)n$ points. More generally, the $\ell_{p}$ subspace approximation problem with outliers minimizes the sum of $p$-th powers of distances instead of the sum of squared distances. Even the case of robust PCA is non-trivial, and previous work requires additional assumptions on the input. Any multiplicative approximation algorithm for the subspace approximation problem with outliers must solve the robust subspace recovery problem, a special case in which the $(1-\alpha)n$ inliers in the optimal solution are promised to lie exactly on a $k$-dimensional linear subspace. However, robust subspace recovery is Small Set Expansion (SSE)-hard. We show how to extend dimension reduction techniques and bi-criteria approximations based on sampling to the problem of subspace approximation with outliers. To get around the SSE-hardness of robust subspace recovery, we assume that the squared distance error of the optimal $k$-dimensional subspace summed over the optimal $(1-\alpha)n$ inliers is at least $\delta$ times its squared-error summed over all $n$ points, for some $0 < \delta \leq 1 - \alpha$. With this assumption, we give an efficient algorithm to find a subset of $poly(k/\epsilon) \log(1/\delta) \log\log(1/\delta)$ points whose span contains a $k$-dimensional subspace that gives a multiplicative $(1+\epsilon)$-approximation to the optimal solution. The running time of our algorithm is linear in $n$ and $d$. Interestingly, our results hold even when the fraction of outliers $\alpha$ is large, as long as the obvious condition $0 < \delta \leq 1 - \alpha$ is satisfied.
Efficient Sketching Algorithm for Sparse Binary Data
Oct 10, 2019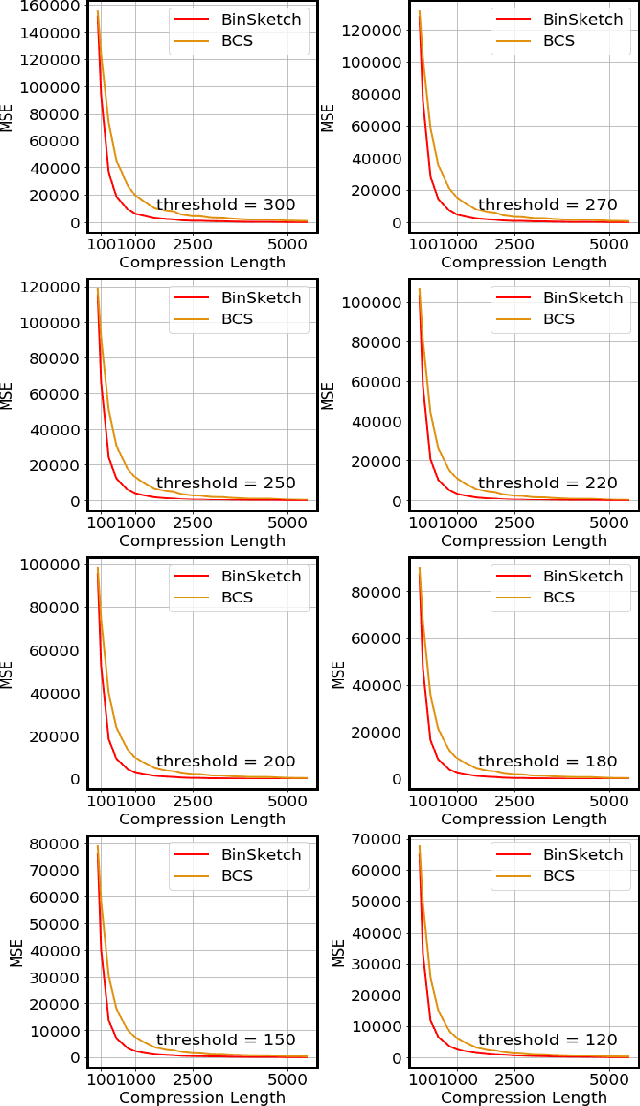
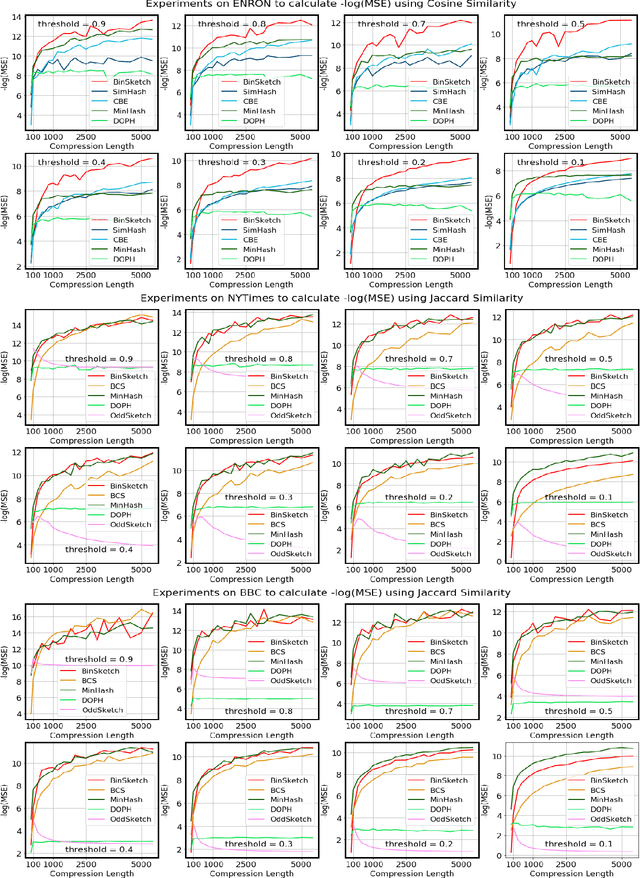
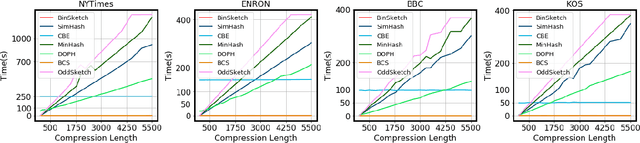
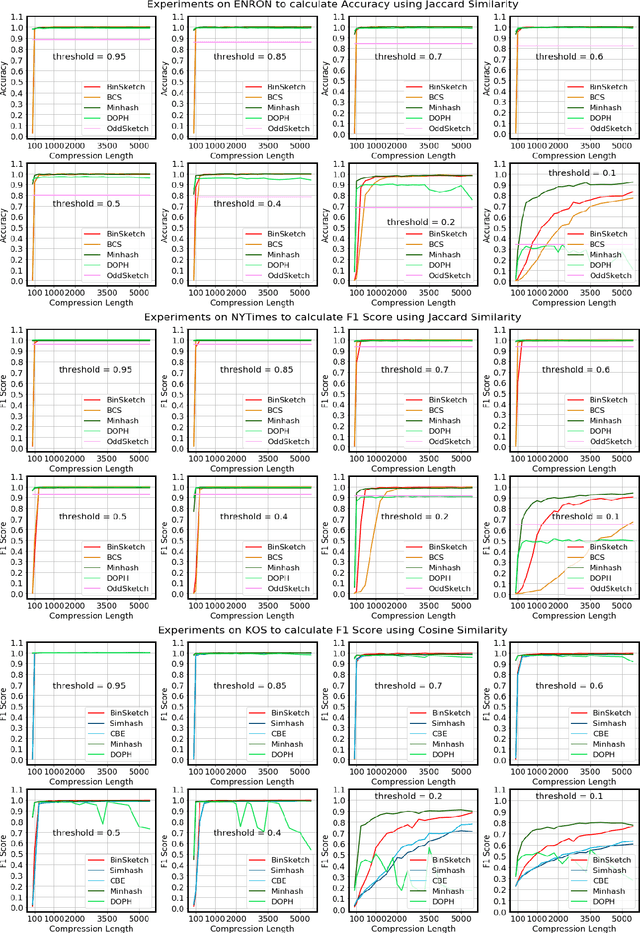
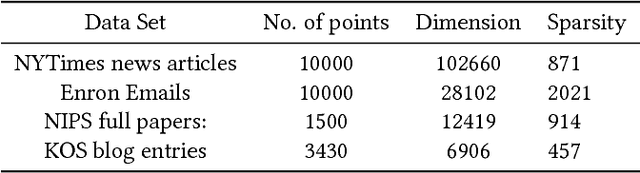
Recent advancement of the WWW, IOT, social network, e-commerce, etc. have generated a large volume of data. These datasets are mostly represented by high dimensional and sparse datasets. Many fundamental subroutines of common data analytic tasks such as clustering, classification, ranking, nearest neighbour search, etc. scale poorly with the dimension of the dataset. In this work, we address this problem and propose a sketching (alternatively, dimensionality reduction) algorithm -- $\binsketch$ (Binary Data Sketch) -- for sparse binary datasets. $\binsketch$ preserves the binary version of the dataset after sketching and maintains estimates for multiple similarity measures such as Jaccard, Cosine, Inner-Product similarities, and Hamming distance, on the same sketch. We present a theoretical analysis of our algorithm and complement it with extensive experimentation on several real-world datasets. We compare the performance of our algorithm with the state-of-the-art algorithms on the task of mean-square-error and ranking. Our proposed algorithm offers a comparable accuracy while suggesting a significant speedup in the dimensionality reduction time, with respect to the other candidate algorithms. Our proposal is simple, easy to implement, and therefore can be adopted in practice.
Efficient Compression Technique for Sparse Sets
Aug 16, 2017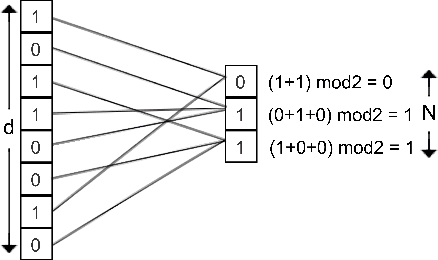
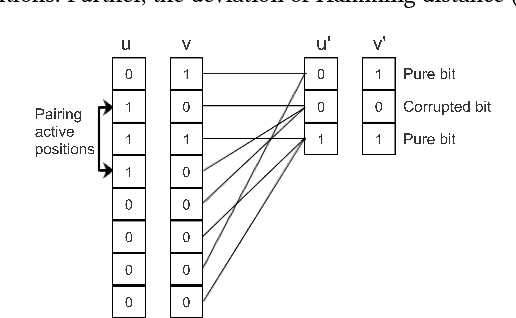
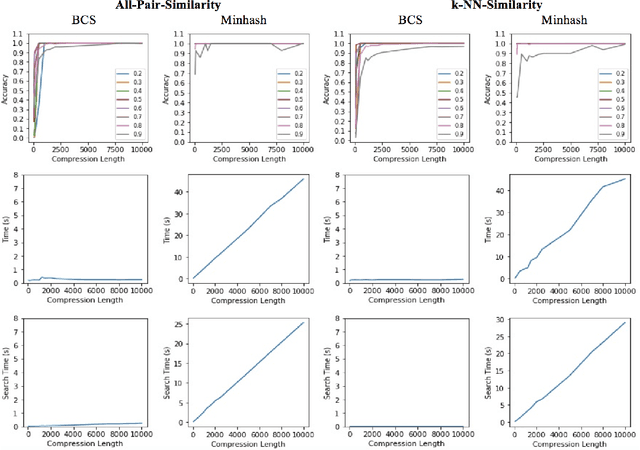
Recent technological advancements have led to the generation of huge amounts of data over the web, such as text, image, audio and video. Most of this data is high dimensional and sparse, for e.g., the bag-of-words representation used for representing text. Often, an efficient search for similar data points needs to be performed in many applications like clustering, nearest neighbour search, ranking and indexing. Even though there have been significant increases in computational power, a simple brute-force similarity-search on such datasets is inefficient and at times impossible. Thus, it is desirable to get a compressed representation which preserves the similarity between data points. In this work, we consider the data points as sets and use Jaccard similarity as the similarity measure. Compression techniques are generally evaluated on the following parameters --1) Randomness required for compression, 2) Time required for compression, 3) Dimension of the data after compression, and 4) Space required to store the compressed data. Ideally, the compressed representation of the data should be such, that the similarity between each pair of data points is preserved, while keeping the time and the randomness required for compression as low as possible. We show that the compression technique suggested by Pratap and Kulkarni also works well for Jaccard similarity. We present a theoretical proof of the same and complement it with rigorous experimentations on synthetic as well as real-world datasets. We also compare our results with the state-of-the-art "min-wise independent permutation", and show that our compression algorithm achieves almost equal accuracy while significantly reducing the compression time and the randomness.