 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Generative Adversarial Privacy
Dec 03, 2017
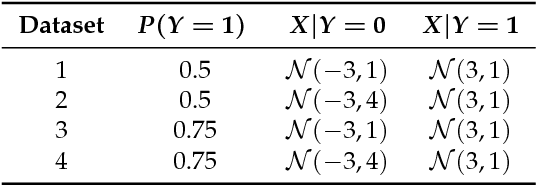
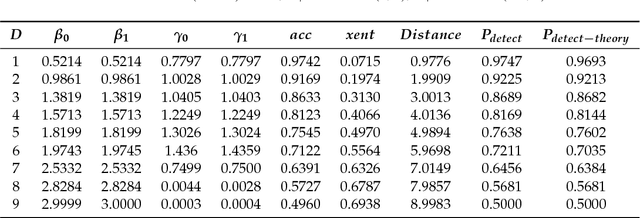
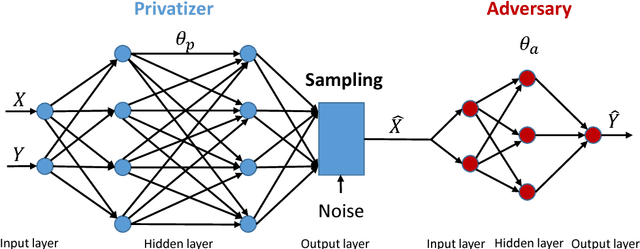
Preserving the utility of published datasets while simultaneously providing provable privacy guarantees is a well-known challenge. On the one hand, context-free privacy solutions, such as differential privacy, provide strong privacy guarantees, but often lead to a significant reduction in utility. On the other hand, context-aware privacy solutions, such as information theoretic privacy, achieve an improved privacy-utility tradeoff, but assume that the data holder has access to dataset statistics. We circumvent these limitations by introducing a novel context-aware privacy framework called generative adversarial privacy (GAP). GAP leverages recent advancements in generative adversarial networks (GANs) to allow the data holder to learn privatization schemes from the dataset itself. Under GAP, learning the privacy mechanism is formulated as a constrained minimax game between two players: a privatizer that sanitizes the dataset in a way that limits the risk of inference attacks on the individuals' private variables, and an adversary that tries to infer the private variables from the sanitized dataset. To evaluate GAP's performance, we investigate two simple (yet canonical) statistical dataset models: (a) the binary data model, and (b) the binary Gaussian mixture model. For both models, we derive game-theoretically optimal minimax privacy mechanisms, and show that the privacy mechanisms learned from data (in a generative adversarial fashion) match the theoretically optimal ones. This demonstrates that our framework can be easily applied in practice, even in the absence of dataset statistics.
A Sparse Linear Model and Significance Test for Individual Consumption Prediction
Feb 21, 2017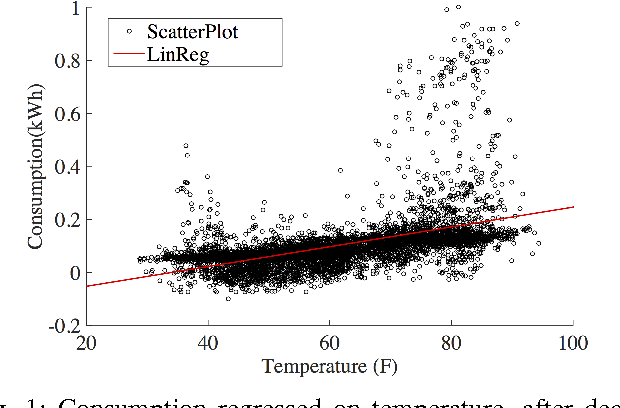
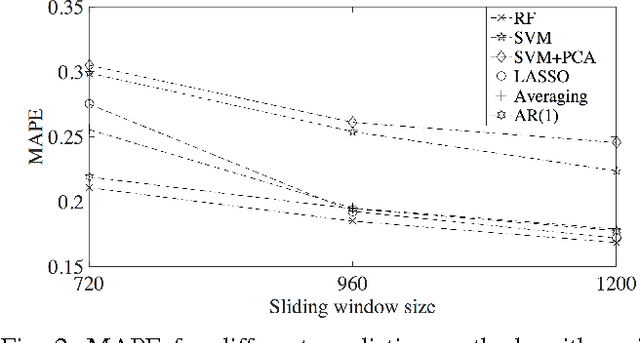
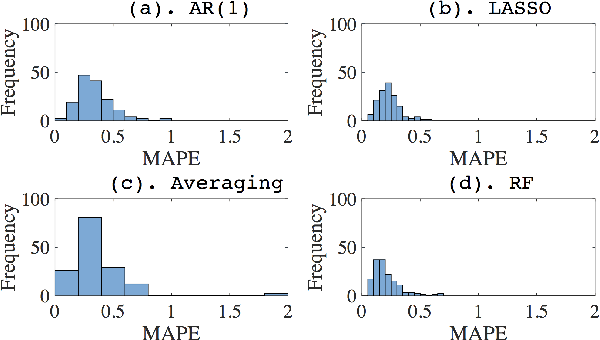
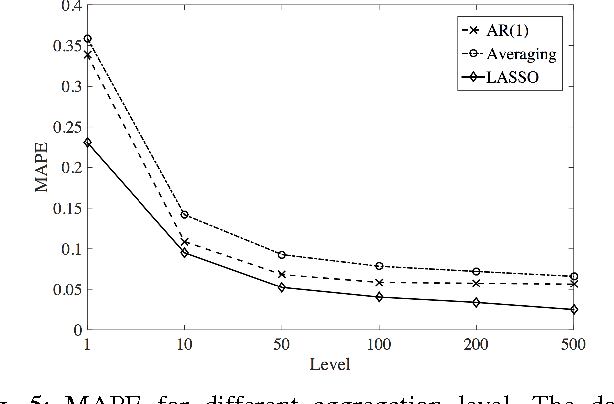
Accurate prediction of user consumption is a key part not only in understanding consumer flexibility and behavior patterns, but in the design of robust and efficient energy saving programs as well. Existing prediction methods usually have high relative errors that can be larger than 30% and have difficulties accounting for heterogeneity between individual users. In this paper, we propose a method to improve prediction accuracy of individual users by adaptively exploring sparsity in historical data and leveraging predictive relationship between different users. Sparsity is captured by popular least absolute shrinkage and selection estimator, while user selection is formulated as an optimal hypothesis testing problem and solved via a covariance test. Using real world data from PG&E, we provide extensive simulation validation of the proposed method against well-known techniques such as support vector machine, principle component analysis combined with linear regression, and random forest. The results demonstrate that our proposed methods are operationally efficient because of linear nature, and achieve optimal prediction performance.
Travel Time Estimation Using Floating Car Data
Dec 20, 2010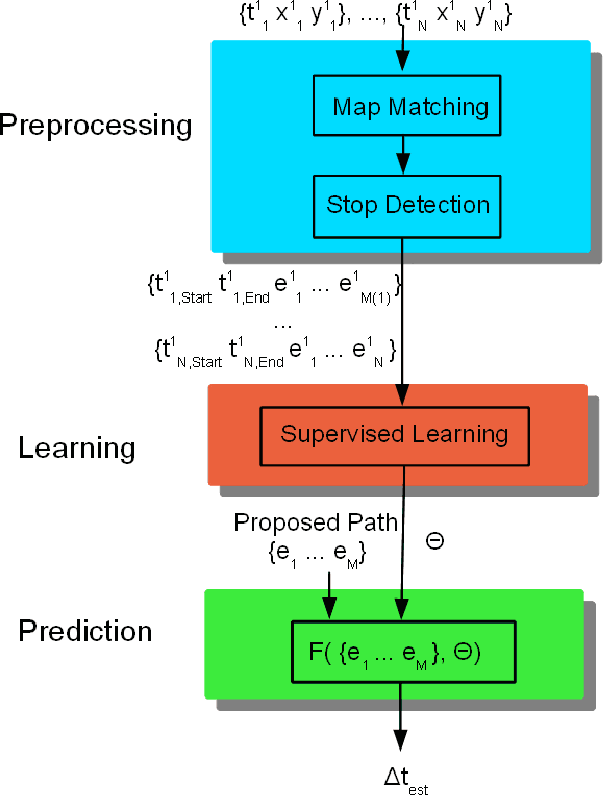
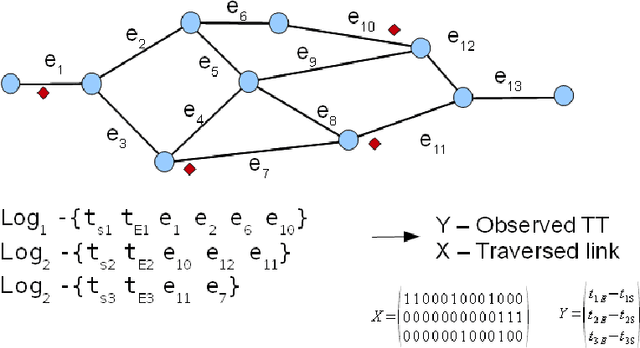

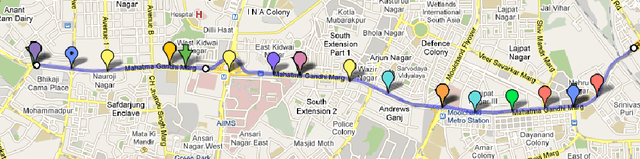
This report explores the use of machine learning techniques to accurately predict travel times in city streets and highways using floating car data (location information of user vehicles on a road network). The aim of this report is twofold, first we present a general architecture of solving this problem, then present and evaluate few techniques on real floating car data gathered over a month on a 5 Km highway in New Delhi.