 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Analytics for Real-world News using Measures of Cross-modal Entity Consistency
Mar 23, 2020
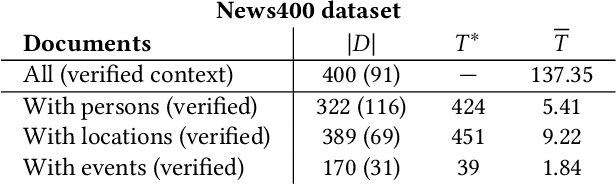
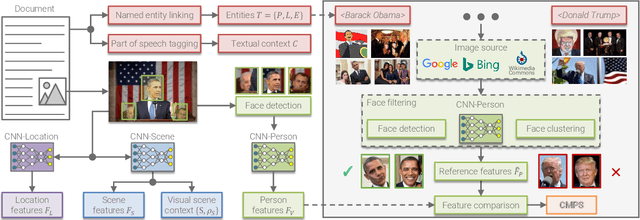

The World Wide Web has become a popular source for gathering information and news. Multimodal information, e.g., enriching text with photos, is typically used to convey the news more effectively or to attract attention. Photo content can range from decorative, depict additional important information, or can even contain misleading information. Therefore, automatic approaches to quantify cross-modal consistency of entity representation can support human assessors to evaluate the overall multimodal message, for instance, with regard to bias or sentiment. In some cases such measures could give hints to detect fake news, which is an increasingly important topic in today's society. In this paper, we introduce a novel task of cross-modal consistency verification in real-world news and present a multimodal approach to quantify the entity coherence between image and text. Named entity linking is applied to extract persons, locations, and events from news texts. Several measures are suggested to calculate cross-modal similarity for these entities using state of the art approaches. In contrast to previous work, our system automatically gathers example data from the Web and is applicable to real-world news. Results on two novel datasets that cover different languages, topics, and domains demonstrate the feasibility of our approach. Datasets and code are publicly available to foster research towards this new direction.
The STEM-ECR Dataset: Grounding Scientific Entity References in STEM Scholarly Content to Authoritative Encyclopedic and Lexicographic Sources
Mar 06, 2020



We introduce the STEM (Science, Technology, Engineering, and Medicine) Dataset for Scientific Entity Extraction, Classification, and Resolution, version 1.0 (STEM-ECR v1.0). The STEM-ECR v1.0 dataset has been developed to provide a benchmark for the evaluation of scientific entity extraction, classification, and resolution tasks in a domain-independent fashion. It comprises abstracts in 10 STEM disciplines that were found to be the most prolific ones on a major publishing platform. We describe the creation of such a multidisciplinary corpus and highlight the obtained findings in terms of the following features: 1) a generic conceptual formalism for scientific entities in a multidisciplinary scientific context; 2) the feasibility of the domain-independent human annotation of scientific entities under such a generic formalism; 3) a performance benchmark obtainable for automatic extraction of multidisciplinary scientific entities using BERT-based neural models; 4) a delineated 3-step entity resolution procedure for human annotation of the scientific entities via encyclopedic entity linking and lexicographic word sense disambiguation; and 5) human evaluations of Babelfy returned encyclopedic links and lexicographic senses for our entities. Our findings cumulatively indicate that human annotation and automatic learning of multidisciplinary scientific concepts as well as their semantic disambiguation in a wide-ranging setting as STEM is reasonable.
SlideImages: A Dataset for Educational Image Classification
Jan 19, 2020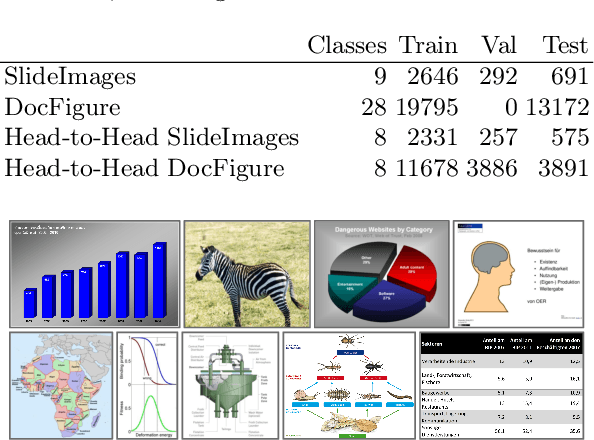
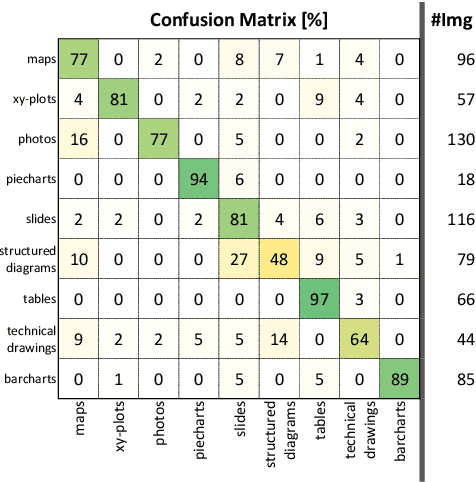
In the past few years, convolutional neural networks (CNNs) have achieved impressive results in computer vision tasks, which however mainly focus on photos with natural scene content. Besides, non-sensor derived images such as illustrations, data visualizations, figures, etc. are typically used to convey complex information or to explore large datasets. However, this kind of images has received little attention in computer vision. CNNs and similar techniques use large volumes of training data. Currently, many document analysis systems are trained in part on scene images due to the lack of large datasets of educational image data. In this paper, we address this issue and present SlideImages, a dataset for the task of classifying educational illustrations. SlideImages contains training data collected from various sources, e.g., Wikimedia Commons and the AI2D dataset, and test data collected from educational slides. We have reserved all the actual educational images as a test dataset in order to ensure that the approaches using this dataset generalize well to new educational images, and potentially other domains. Furthermore, we present a baseline system using a standard deep neural architecture and discuss dealing with the challenge of limited training data.
Visual Summarization of Scholarly Videos using Word Embeddings and Keyphrase Extraction
Nov 25, 2019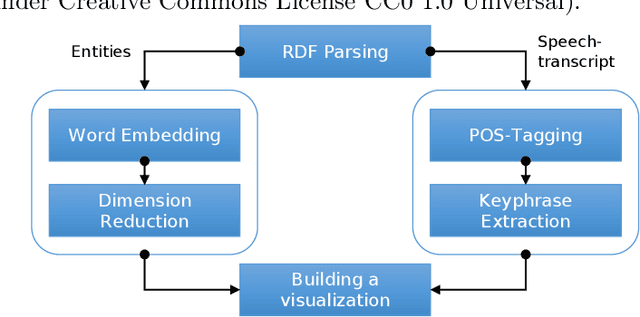

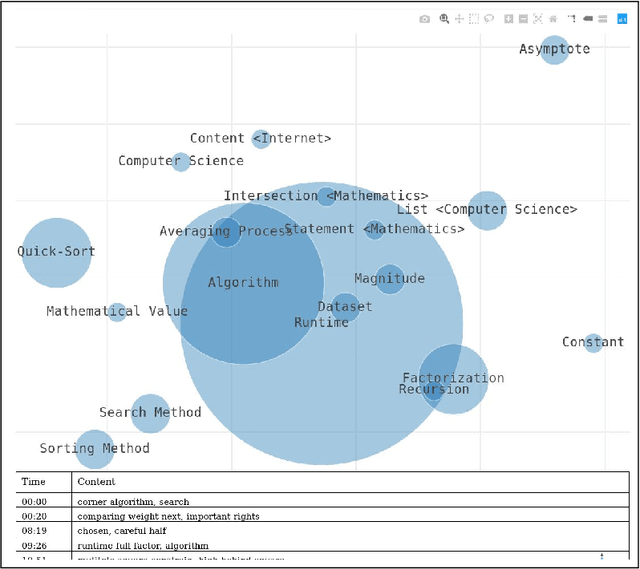
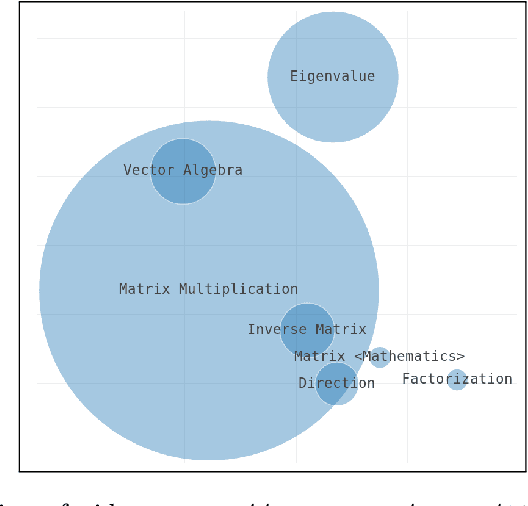
Effective learning with audiovisual content depends on many factors. Besides the quality of the learning resource's content, it is essential to discover the most relevant and suitable video in order to support the learning process most effectively. Video summarization techniques facilitate this goal by providing a quick overview over the content. It is especially useful for longer recordings such as conference presentations or lectures. In this paper, we present an approach that generates a visual summary of video content based on semantic word embeddings and keyphrase extraction. For this purpose, we exploit video annotations that are automatically generated by speech recognition and video OCR (optical character recognition).
"Does 4-4-2 exist?" -- An Analytics Approach to Understand and Classify Football Team Formations in Single Match Situations
Sep 02, 2019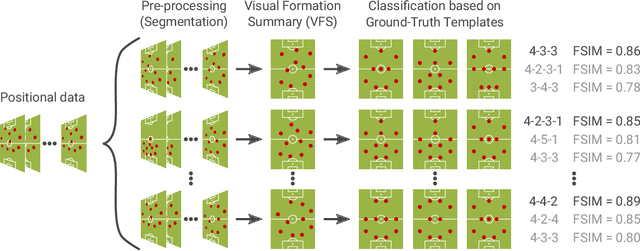
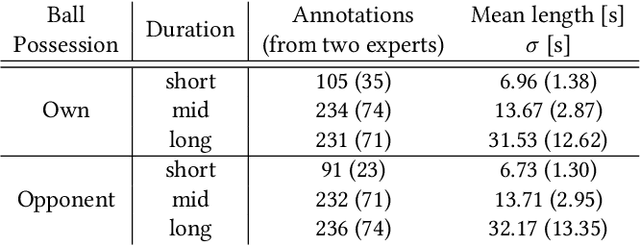
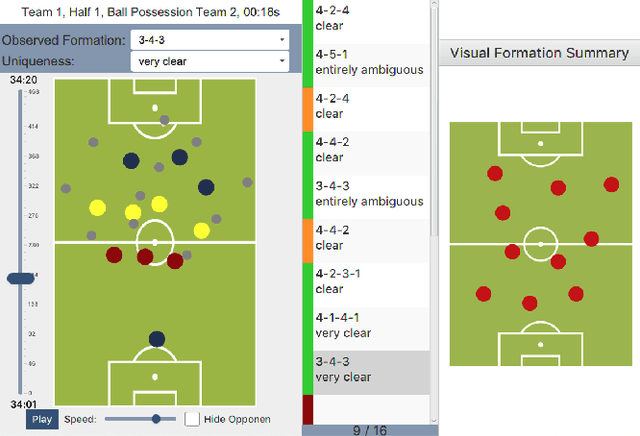

The chances to win a football match can be significantly increased if the right tactic is chosen and the behavior of the opposite team is well anticipated. For this reason, every professional football club employs a team of game analysts. However, at present game performance analysis is done manually and therefore highly time-consuming. Consequently, automated tools to support the analysis process are required. In this context, one of the main tasks is to summarize team formations by patterns such as 4-4-2. In this paper, we introduce an analytics approach that automatically classifies and visualizes the team formation based on the players' position data. We focus on single match situations instead of complete halftimes or matches to provide a more detailed analysis. A detailed analysis of individual match situations depending on ball possession and match segment length is provided. For this purpose, a visual summary is utilized that summarizes the team formation in a match segment. An expert annotation study is conducted that demonstrates 1) the complexity of the task and 2) the usefulness of the visualization of single situations to understand team formations. The suggested classification approach outperforms existing methods for formation classification. In particular, our approach gives insights about the shortcomings of using patterns like 4-4-2 to describe team formations.
Investigating Correlations of Inter-coder Agreement and Machine Annotation Performance for Historical Video Data
Jul 24, 2019
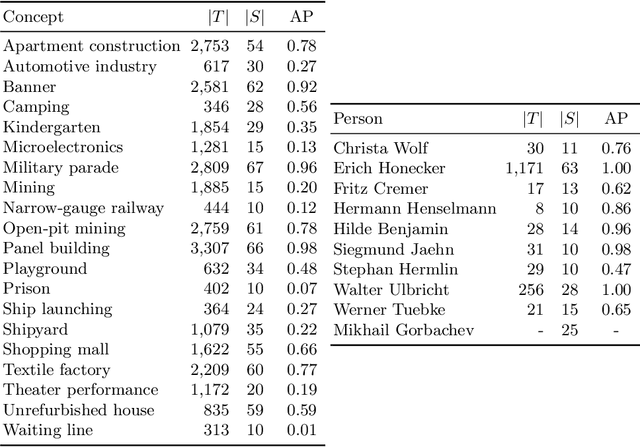
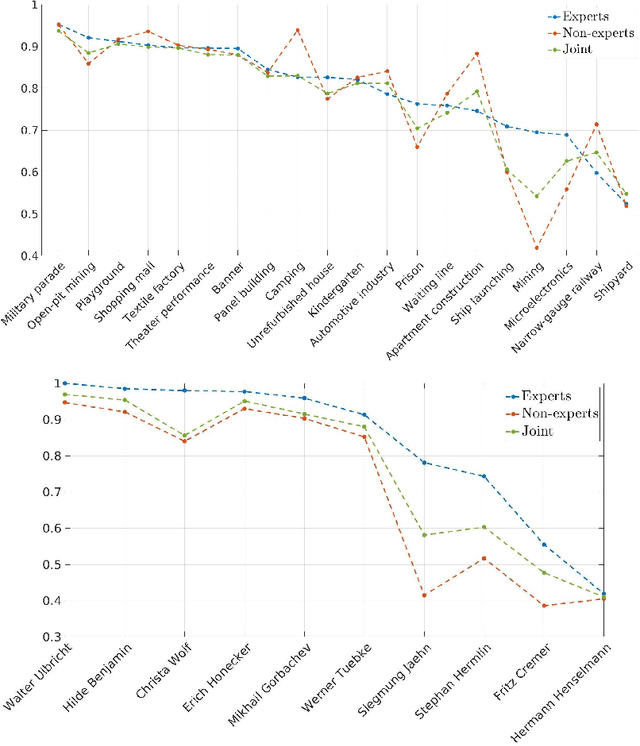
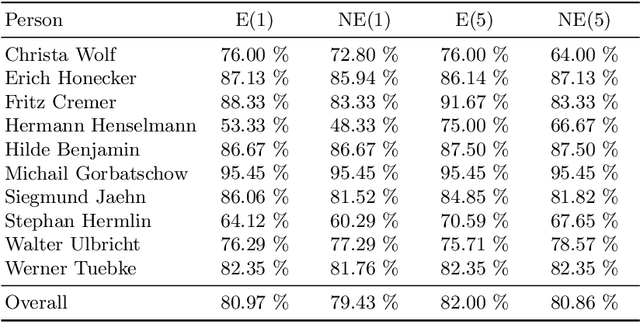
Video indexing approaches such as visual concept classification and person recognition are essential to enable fine-grained semantic search in large-scale video archives such as the historical video collection of former German Democratic Republic (GDR) maintained by the German Broadcasting Archive (DRA). Typically, a lexicon of visual concepts has to be defined for semantic search. However, the definition of visual concepts can be more or less subjective due to individually differing judgments of annotators, which may have an impact on annotation quality and subsequently training of supervised machine learning methods. In this paper, we analyze the inter-coder agreement for historical TV data of the former GDR for visual concept classification and person recognition. The inter-coder agreement is evaluated for a group of expert as well as non-expert annotators in order to determine differences in annotation homogeneity. Furthermore, correlations between visual recognition performance and inter-annotator agreement are measured. In this context, information about image quantity and agreement are used to predict average precision for concept classification. Finally, the influence of expert vs. non-expert annotations acquired in the study are used to evaluate person recognition.
"Is this an example image?" -- Predicting the Relative Abstractness Level of Image and Text
Jan 23, 2019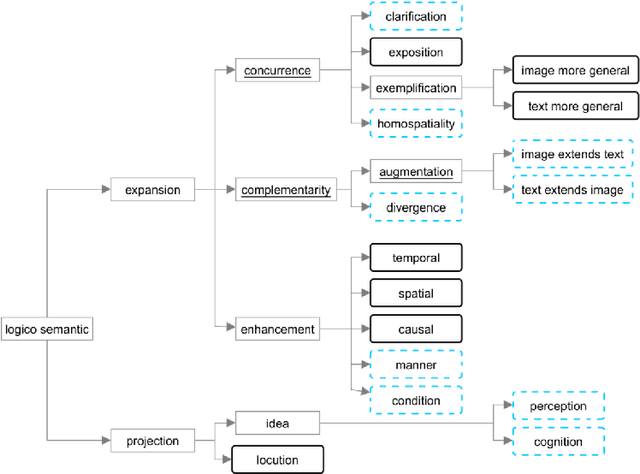
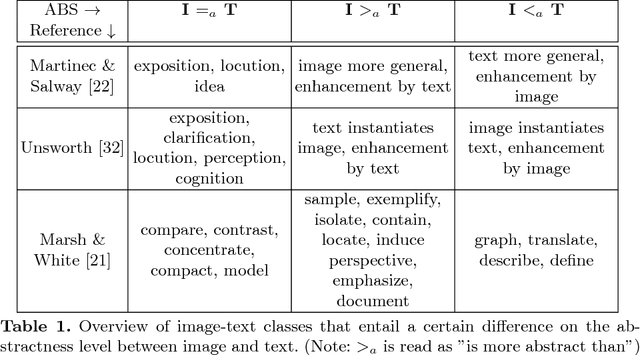

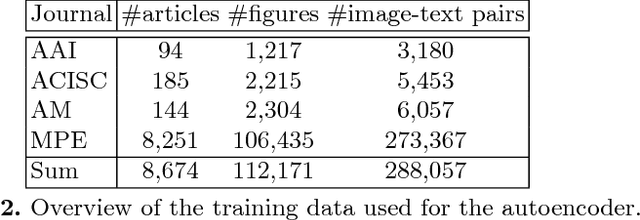
Successful multimodal search and retrieval requires the automatic understanding of semantic cross-modal relations, which, however, is still an open research problem. Previous work has suggested the metrics cross-modal mutual information and semantic correlation to model and predict cross-modal semantic relations of image and text. In this paper, we present an approach to predict the (cross-modal) relative abstractness level of a given image-text pair, that is whether the image is an abstraction of the text or vice versa. For this purpose, we introduce a new metric that captures this specific relationship between image and text at the Abstractness Level (ABS). We present a deep learning approach to predict this metric, which relies on an autoencoder architecture that allows us to significantly reduce the required amount of labeled training data. A comprehensive set of publicly available scientific documents has been gathered. Experimental results on a challenging test set demonstrate the feasibility of the approach.
Finding Person Relations in Image Data of the Internet Archive
Jun 21, 2018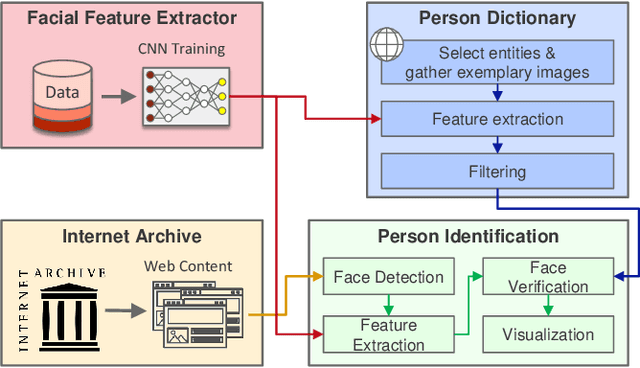

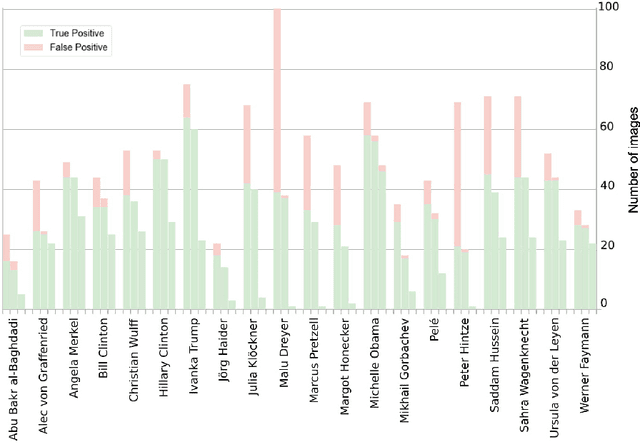
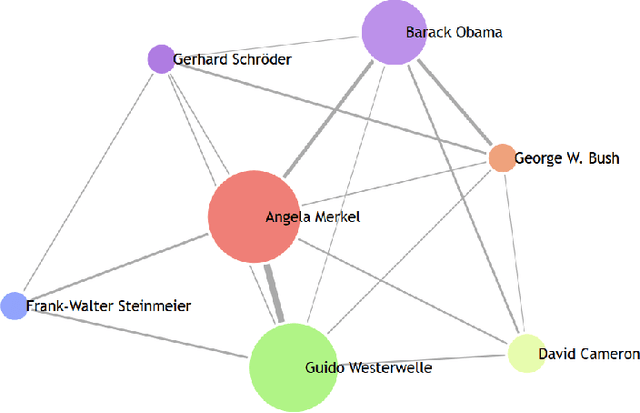
The multimedia content in the World Wide Web is rapidly growing and contains valuable information for many applications in different domains. For this reason, the Internet Archive initiative has been gathering billions of time-versioned web pages since the mid-nineties. However, the huge amount of data is rarely labeled with appropriate metadata and automatic approaches are required to enable semantic search. Normally, the textual content of the Internet Archive is used to extract entities and their possible relations across domains such as politics and entertainment, whereas image and video content is usually neglected. In this paper, we introduce a system for person recognition in image content of web news stored in the Internet Archive. Thus, the system complements entity recognition in text and allows researchers and analysts to track media coverage and relations of persons more precisely. Based on a deep learning face recognition approach, we suggest a system that automatically detects persons of interest and gathers sample material, which is subsequently used to identify them in the image data of the Internet Archive. We evaluate the performance of the face recognition system on an appropriate standard benchmark dataset and demonstrate the feasibility of the approach with two use cases.