 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking Similarities over Differences: Similarity-based Domain Alignment for Adaptive Object Detection
Oct 04, 2021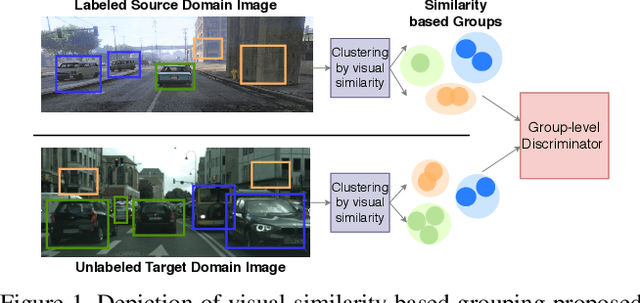
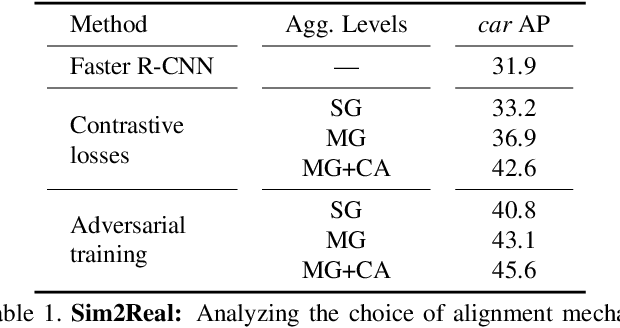
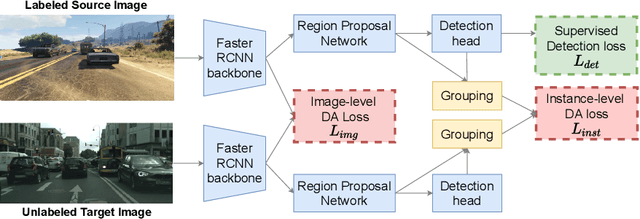

In order to robustly deploy object detectors across a wide range of scenarios, they should be adaptable to shifts in the input distribution without the need to constantly annotate new data. This has motivated research in Unsupervised Domain Adaptation (UDA) algorithms for detection. UDA methods learn to adapt from labeled source domains to unlabeled target domains, by inducing alignment between detector features from source and target domains. Yet, there is no consensus on what features to align and how to do the alignment. In our work, we propose a framework that generalizes the different components commonly used by UDA methods laying the ground for an in-depth analysis of the UDA design space. Specifically, we propose a novel UDA algorithm, ViSGA, a direct implementation of our framework, that leverages the best design choices and introduces a simple but effective method to aggregate features at instance-level based on visual similarity before inducing group alignment via adversarial training. We show that both similarity-based grouping and adversarial training allows our model to focus on coarsely aligning feature groups, without being forced to match all instances across loosely aligned domains. Finally, we examine the applicability of ViSGA to the setting where labeled data are gathered from different sources. Experiments show that not only our method outperforms previous single-source approaches on Sim2Real and Adverse Weather, but also generalizes well to the multi-source setting.
Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
Dec 22, 2019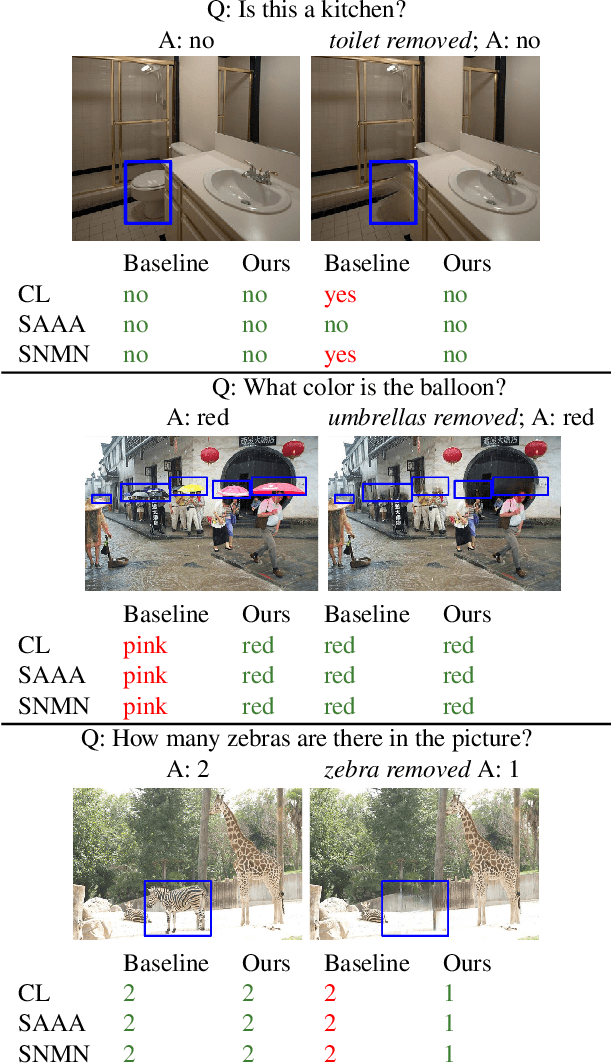

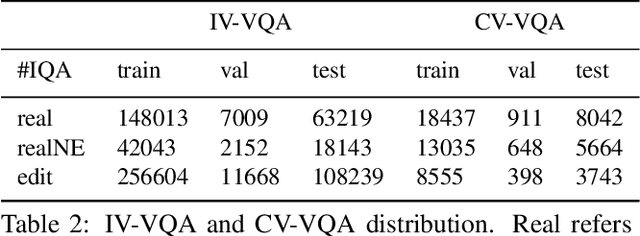

Despite significant success in Visual Question Answering (VQA), VQA models have been shown to be notoriously brittle to linguistic variations in the questions. Due to deficiencies in models and datasets, today's models often rely on correlations rather than predictions that are causal w.r.t. data. In this paper, we propose a novel way to analyze and measure the robustness of the state of the art models w.r.t semantic visual variations as well as propose ways to make models more robust against spurious correlations. Our method performs automated semantic image manipulations and tests for consistency in model predictions to quantify the model robustness as well as generate synthetic data to counter these problems. We perform our analysis on three diverse, state of the art VQA models and diverse question types with a particular focus on challenging counting questions. In addition, we show that models can be made significantly more robust against inconsistent predictions using our edited data. Finally, we show that results also translate to real-world error cases of state of the art models, which results in improved overall performance
Not Using the Car to See the Sidewalk: Quantifying and Controlling the Effects of Context in Classification and Segmentation
Dec 17, 2018
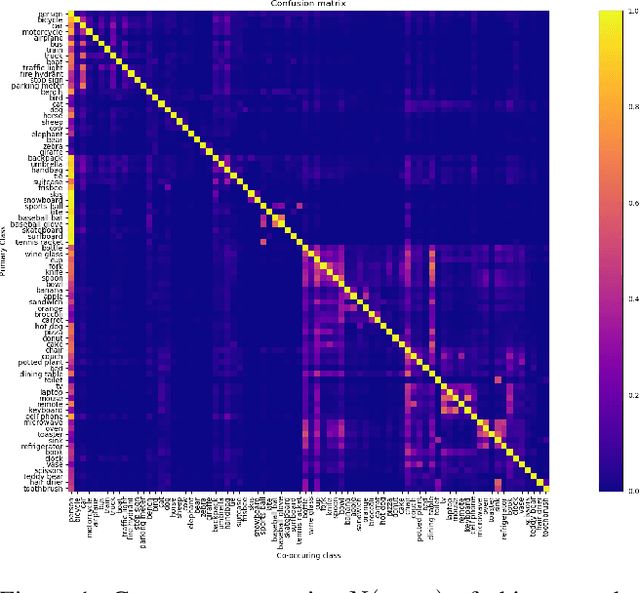

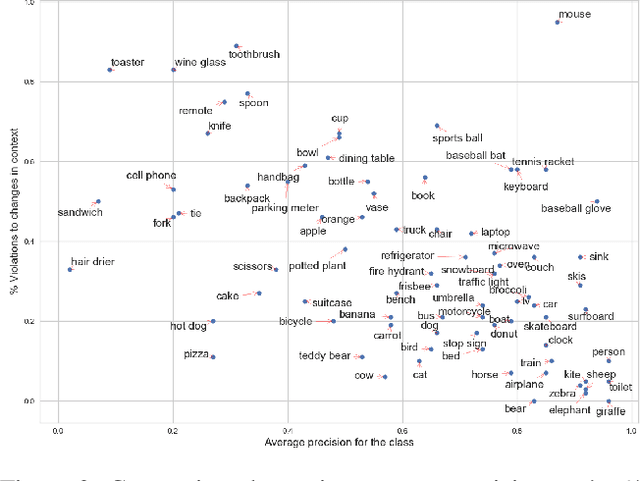
Importance of visual context in scene understanding tasks is well recognized in the computer vision community. However, to what extent the computer vision models for image classification and semantic segmentation are dependent on the context to make their predictions is unclear. A model overly relying on context will fail when encountering objects in context distributions different from training data and hence it is important to identify these dependencies before we can deploy the models in the real-world. We propose a method to quantify the sensitivity of black-box vision models to visual context by editing images to remove selected objects and measuring the response of the target models. We apply this methodology on two tasks, image classification and semantic segmentation, and discover undesirable dependency between objects and context, for example that "sidewalk" segmentation relies heavily on "cars" being present in the image. We propose an object removal based data augmentation solution to mitigate this dependency and increase the robustness of classification and segmentation models to contextual variations. Our experiments show that the proposed data augmentation helps these models improve the performance in out-of-context scenarios, while preserving the performance on regular data.
Adversarial Scene Editing: Automatic Object Removal from Weak Supervision
Jun 05, 2018
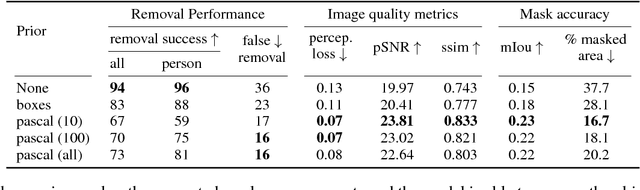
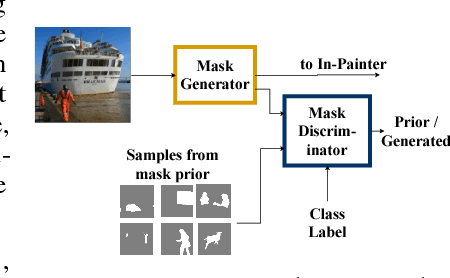
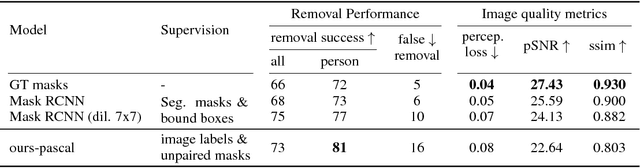
While great progress has been made recently in automatic image manipulation, it has been limited to object centric images like faces or structured scene datasets. In this work, we take a step towards general scene-level image editing by developing an automatic interaction-free object removal model. Our model learns to find and remove objects from general scene images using image-level labels and unpaired data in a generative adversarial network (GAN) framework. We achieve this with two key contributions: a two-stage editor architecture consisting of a mask generator and image in-painter that co-operate to remove objects, and a novel GAN based prior for the mask generator that allows us to flexibly incorporate knowledge about object shapes. We experimentally show on two datasets that our method effectively removes a wide variety of objects using weak supervision only
$A^{4}NT$: Author Attribute Anonymity by Adversarial Training of Neural Machine Translation
Feb 19, 2018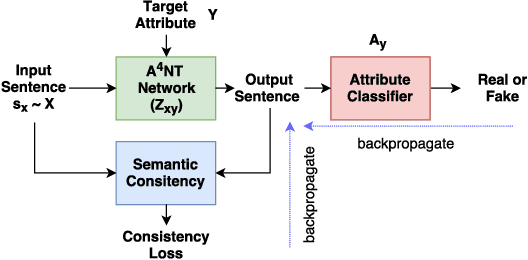
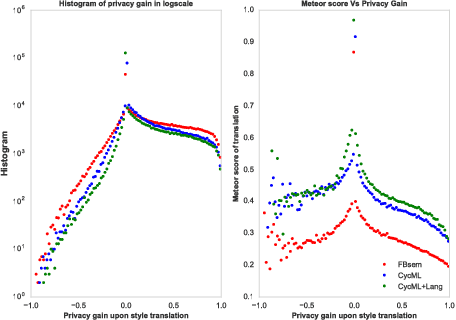
Text-based analysis methods allow to reveal privacy relevant author attributes such as gender, age and identify of the text's author. Such methods can compromise the privacy of an anonymous author even when the author tries to remove privacy sensitive content. In this paper, we propose an automatic method, called Adversarial Author Attribute Anonymity Neural Translation ($A^4NT$), to combat such text-based adversaries. We combine sequence-to-sequence language models used in machine translation and generative adversarial networks to obfuscate author attributes. Unlike machine translation techniques which need paired data, our method can be trained on unpaired corpora of text containing different authors. Importantly, we propose and evaluate techniques to impose constraints on our $A^4NT$ to preserve the semantics of the input text. $A^4NT$ learns to make minimal changes to the input text to successfully fool author attribute classifiers, while aiming to maintain the meaning of the input. We show through experiments on two different datasets and three settings that our proposed method is effective in fooling the author attribute classifiers and thereby improving the anonymity of authors.
Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Nov 06, 2017
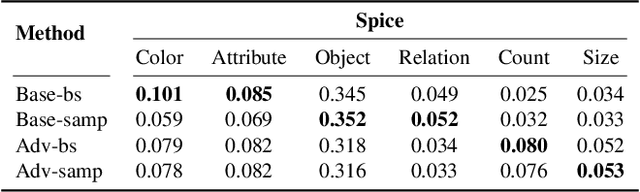
While strong progress has been made in image captioning over the last years, machine and human captions are still quite distinct. A closer look reveals that this is due to the deficiencies in the generated word distribution, vocabulary size, and strong bias in the generators towards frequent captions. Furthermore, humans -- rightfully so -- generate multiple, diverse captions, due to the inherent ambiguity in the captioning task which is not considered in today's systems. To address these challenges, we change the training objective of the caption generator from reproducing groundtruth captions to generating a set of captions that is indistinguishable from human generated captions. Instead of handcrafting such a learning target, we employ adversarial training in combination with an approximate Gumbel sampler to implicitly match the generated distribution to the human one. While our method achieves comparable performance to the state-of-the-art in terms of the correctness of the captions, we generate a set of diverse captions, that are significantly less biased and match the word statistics better in several aspects.
Paying Attention to Descriptions Generated by Image Captioning Models
Aug 04, 2017
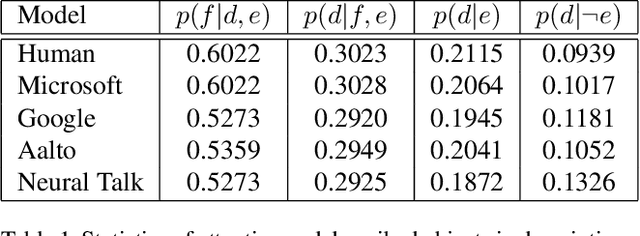
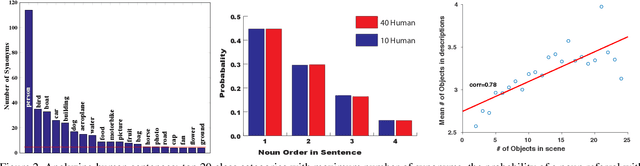
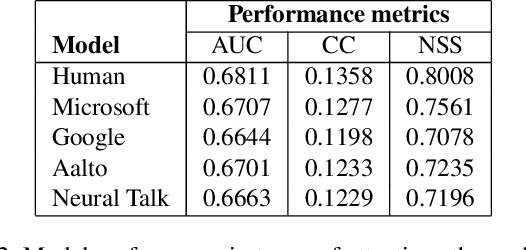
To bridge the gap between humans and machines in image understanding and describing, we need further insight into how people describe a perceived scene. In this paper, we study the agreement between bottom-up saliency-based visual attention and object referrals in scene description constructs. We investigate the properties of human-written descriptions and machine-generated ones. We then propose a saliency-boosted image captioning model in order to investigate benefits from low-level cues in language models. We learn that (1) humans mention more salient objects earlier than less salient ones in their descriptions, (2) the better a captioning model performs, the better attention agreement it has with human descriptions, (3) the proposed saliency-boosted model, compared to its baseline form, does not improve significantly on the MS COCO database, indicating explicit bottom-up boosting does not help when the task is well learnt and tuned on a data, (4) a better generalization is, however, observed for the saliency-boosted model on unseen data.
Frame- and Segment-Level Features and Candidate Pool Evaluation for Video Caption Generation
Aug 17, 2016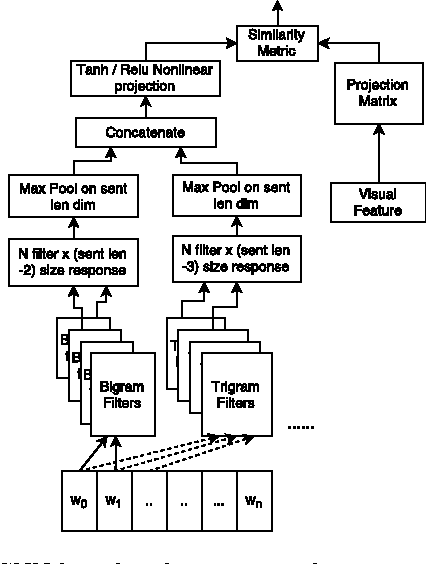
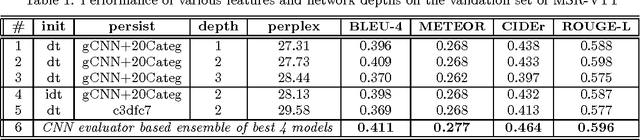

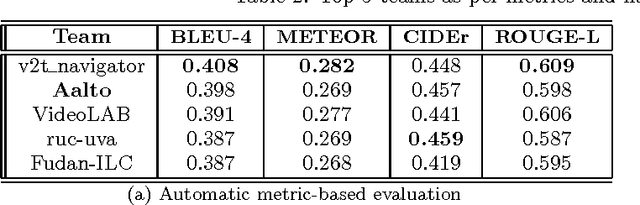
We present our submission to the Microsoft Video to Language Challenge of generating short captions describing videos in the challenge dataset. Our model is based on the encoder--decoder pipeline, popular in image and video captioning systems. We propose to utilize two different kinds of video features, one to capture the video content in terms of objects and attributes, and the other to capture the motion and action information. Using these diverse features we train models specializing in two separate input sub-domains. We then train an evaluator model which is used to pick the best caption from the pool of candidates generated by these domain expert models. We argue that this approach is better suited for the current video captioning task, compared to using a single model, due to the diversity in the dataset. Efficacy of our method is proven by the fact that it was rated best in MSR Video to Language Challenge, as per human evaluation. Additionally, we were ranked second in the automatic evaluation metrics based table.
Video captioning with recurrent networks based on frame- and video-level features and visual content classification
Dec 09, 2015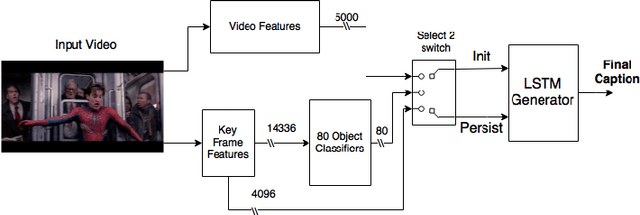
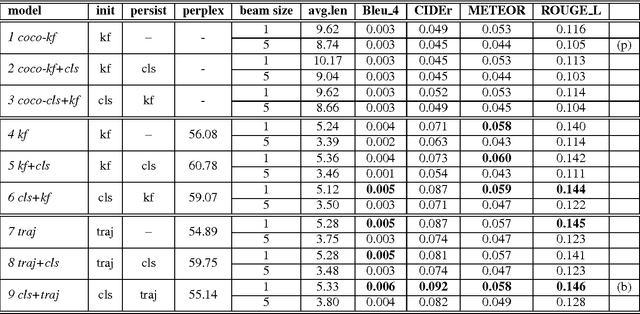
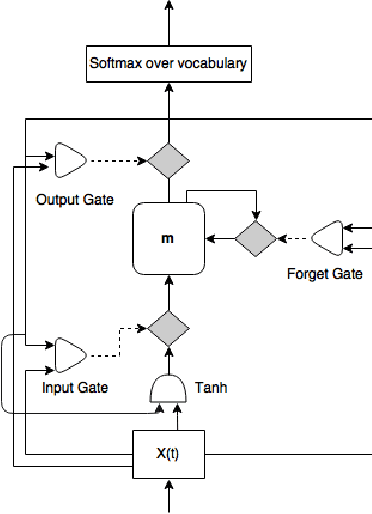
In this paper, we describe the system for generating textual descriptions of short video clips using recurrent neural networks (RNN), which we used while participating in the Large Scale Movie Description Challenge 2015 in ICCV 2015. Our work builds on static image captioning systems with RNN based language models and extends this framework to videos utilizing both static image features and video-specific features. In addition, we study the usefulness of visual content classifiers as a source of additional information for caption generation. With experimental results we show that utilizing keyframe based features, dense trajectory video features and content classifier outputs together gives better performance than any one of them individually.