 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Drivers' Drowsiness Detection and Analysis through Deep Learning
Nov 16, 2025



A long road trip is fun for drivers. However, a long drive for days can be tedious for a driver to accommodate stringent deadlines to reach distant destinations. Such a scenario forces drivers to drive extra miles, utilizing extra hours daily without sufficient rest and breaks. Once a driver undergoes such a scenario, it occasionally triggers drowsiness during driving. Drowsiness in driving can be life-threatening to any individual and can affect other drivers' safety; therefore, a real-time detection system is needed. To identify fatigued facial characteristics in drivers and trigger the alarm immediately, this research develops a real-time driver drowsiness detection system utilizing deep convolutional neural networks (DCNNs) and OpenCV.Our proposed and implemented model takes real- time facial images of a driver using a live camera and utilizes a Python-based library named OpenCV to examine the facial images for facial landmarks like sufficient eye openings and yawn-like mouth movements. The DCNNs framework then gathers the data and utilizes a per-trained model to detect the drowsiness of a driver using facial landmarks. If the driver is identified as drowsy, the system issues a continuous alert in real time, embedded in the Smart Car technology.By potentially saving innocent lives on the roadways, the proposed technique offers a non-invasive, inexpensive, and cost-effective way to identify drowsiness. Our proposed and implemented DCNNs embedded drowsiness detection model successfully react with NTHU-DDD dataset and Yawn-Eye-Dataset with drowsiness detection classification accuracy of 99.6% and 97% respectively.
Point Cloud Upsampling and Normal Estimation using Deep Learning for Robust Surface Reconstruction
Feb 26, 2021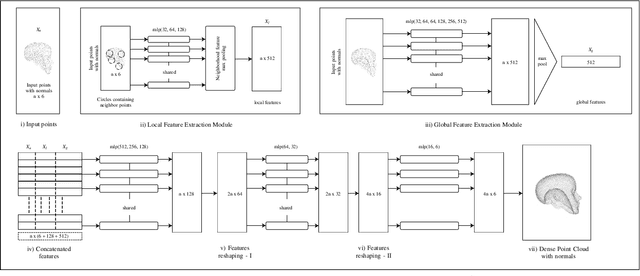
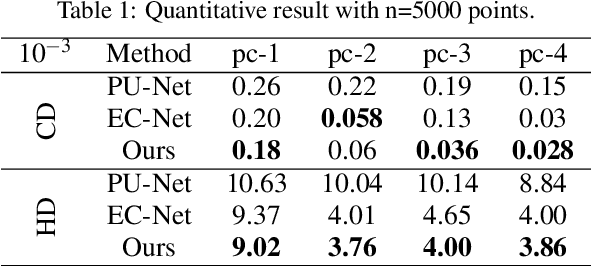
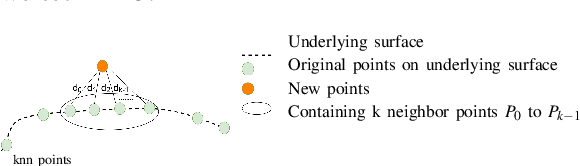

The reconstruction of real-world surfaces is on high demand in various applications. Most existing reconstruction approaches apply 3D scanners for creating point clouds which are generally sparse and of low density. These points clouds will be triangulated and used for visualization in combination with surface normals estimated by geometrical approaches. However, the quality of the reconstruction depends on the density of the point cloud and the estimation of the surface normals. In this paper, we present a novel deep learning architecture for point cloud upsampling that enables subsequent stable and smooth surface reconstruction. A noisy point cloud of low density with corresponding point normals is used to estimate a point cloud with higher density and appendant point normals. To this end, we propose a compound loss function that encourages the network to estimate points that lie on a surface including normals accurately predicting the orientation of the surface. Our results show the benefit of estimating normals together with point positions. The resulting point cloud is smoother, more complete, and the final surface reconstruction is much closer to ground truth.
MAIRE -- A Model-Agnostic Interpretable Rule Extraction Procedure for Explaining Classifiers
Nov 03, 2020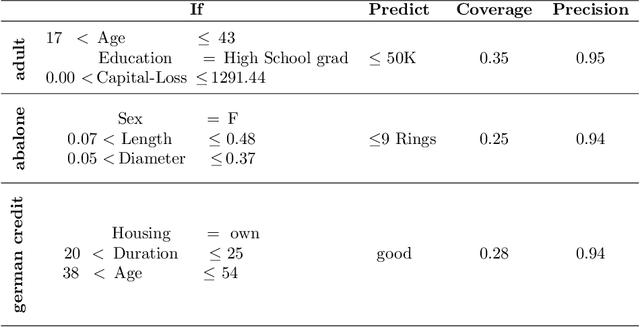
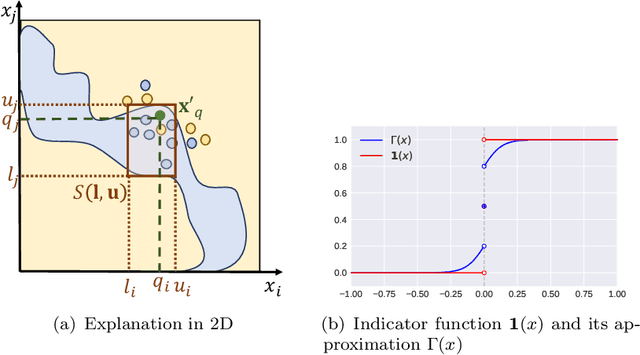

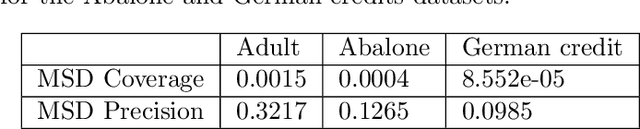
The paper introduces a novel framework for extracting model-agnostic human interpretable rules to explain a classifier's output. The human interpretable rule is defined as an axis-aligned hyper-cuboid containing the instance for which the classification decision has to be explained. The proposed procedure finds the largest (high \textit{coverage}) axis-aligned hyper-cuboid such that a high percentage of the instances in the hyper-cuboid have the same class label as the instance being explained (high \textit{precision}). Novel approximations to the coverage and precision measures in terms of the parameters of the hyper-cuboid are defined. They are maximized using gradient-based optimizers. The quality of the approximations is rigorously analyzed theoretically and experimentally. Heuristics for simplifying the generated explanations for achieving better interpretability and a greedy selection algorithm that combines the local explanations for creating global explanations for the model covering a large part of the instance space are also proposed. The framework is model agnostic, can be applied to any arbitrary classifier, and all types of attributes (including continuous, ordered, and unordered discrete). The wide-scale applicability of the framework is validated on a variety of synthetic and real-world datasets from different domains (tabular, text, and image).