 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKATANA: Simple Post-Training Robustness Using Test Time Augmentations
Sep 16, 2021
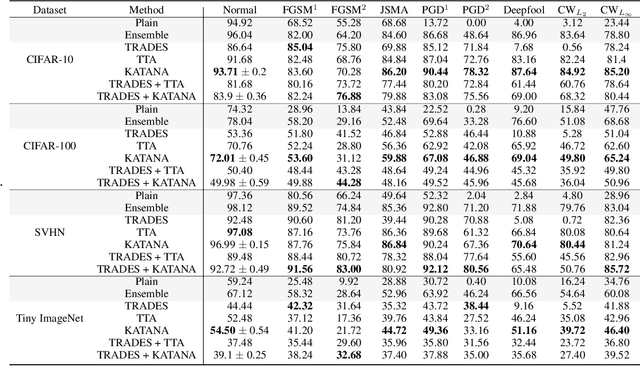

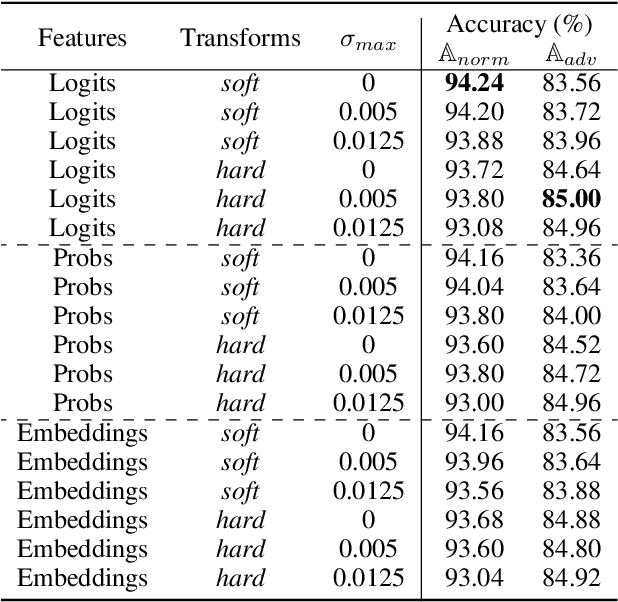
Although Deep Neural Networks (DNNs) achieve excellent performance on many real-world tasks, they are highly vulnerable to adversarial attacks. A leading defense against such attacks is adversarial training, a technique in which a DNN is trained to be robust to adversarial attacks by introducing adversarial noise to its input. This procedure is effective but must be done during the training phase. In this work, we propose a new simple and easy-to-use technique, KATANA, for robustifying an existing pretrained DNN without modifying its weights. For every image, we generate N randomized Test Time Augmentations (TTAs) by applying diverse color, blur, noise, and geometric transforms. Next, we utilize the DNN's logits output to train a simple random forest classifier to predict the real class label. Our strategy achieves state-of-the-art adversarial robustness on diverse attacks with minimal compromise on the natural images' classification. We test KATANA also against two adaptive white-box attacks and it shows excellent results when combined with adversarial training. Code is available in https://github.com/giladcohen/KATANA.
MISS GAN: A Multi-IlluStrator Style Generative Adversarial Network for image to illustration translation
Aug 12, 2021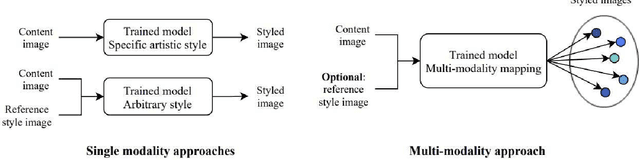
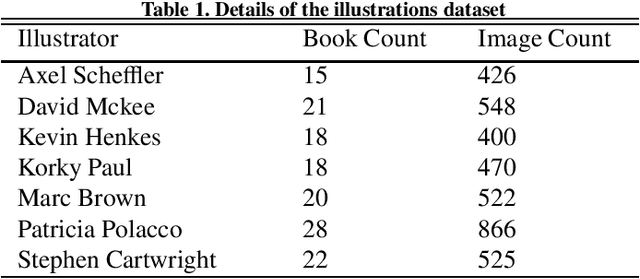
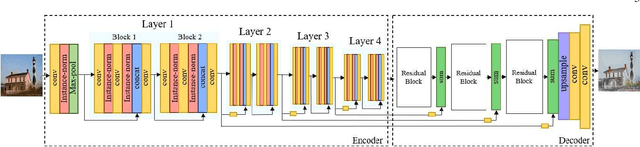

Unsupervised style transfer that supports diverse input styles using only one trained generator is a challenging and interesting task in computer vision. This paper proposes a Multi-IlluStrator Style Generative Adversarial Network (MISS GAN) that is a multi-style framework for unsupervised image-to-illustration translation, which can generate styled yet content preserving images. The illustrations dataset is a challenging one since it is comprised of illustrations of seven different illustrators, hence contains diverse styles. Existing methods require to train several generators (as the number of illustrators) to handle the different illustrators' styles, which limits their practical usage, or require to train an image specific network, which ignores the style information provided in other images of the illustrator. MISS GAN is both input image specific and uses the information of other images using only one trained model.
Z2P: Instant Rendering of Point Clouds
May 30, 2021

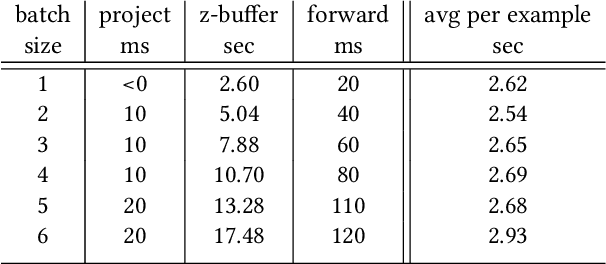
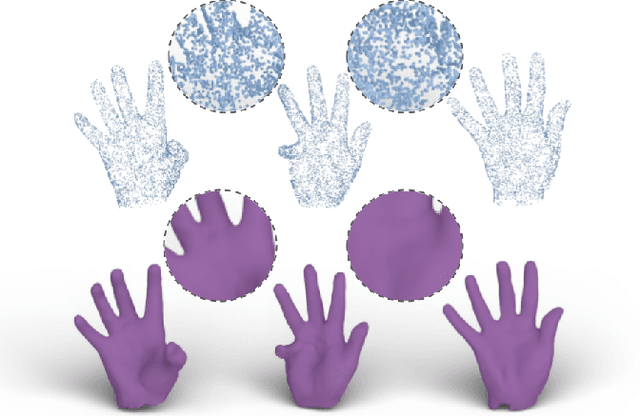
We present a technique for rendering point clouds using a neural network. Existing point rendering techniques either use splatting, or first reconstruct a surface mesh that can then be rendered. Both of these techniques require solving for global point normal orientation, which is a challenging problem on its own. Furthermore, splatting techniques result in holes and overlaps, whereas mesh reconstruction is particularly challenging, especially in the cases of thin surfaces and sheets. We cast the rendering problem as a conditional image-to-image translation problem. In our formulation, Z2P, i.e., depth-augmented point features as viewed from target camera view, are directly translated by a neural network to rendered images, conditioned on control variables (e.g., color, light). We avoid inevitable issues with splatting (i.e., holes and overlaps), and bypass solving the notoriously challenging surface reconstruction problem or estimating oriented normals. Yet, our approach results in a rendered image as if a surface mesh was reconstructed. We demonstrate that our framework produces a plausible image, and can effectively handle noise, non-uniform sampling, thin surfaces / sheets, and is fast.
FLEX: Parameter-free Multi-view 3D Human Motion Reconstruction
May 05, 2021
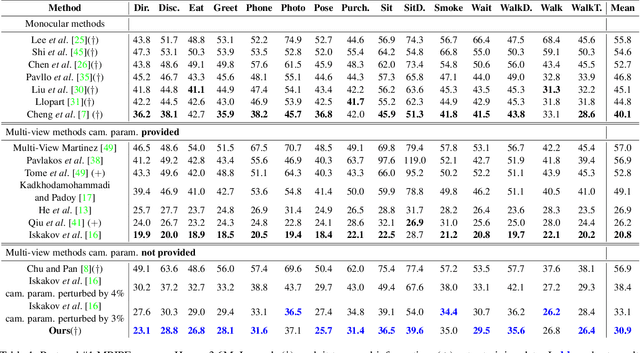
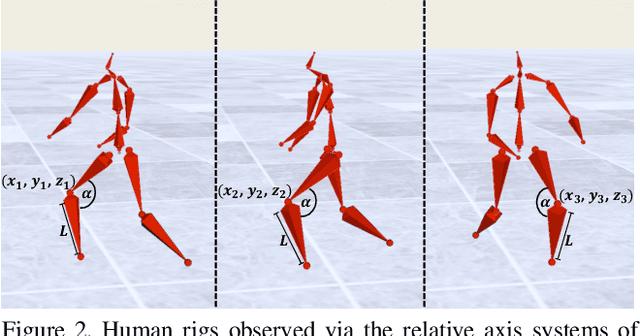
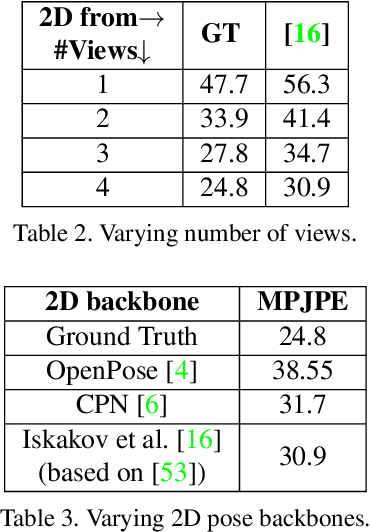
The increasing availability of video recordings made by multiple cameras has offered new means for mitigating occlusion and depth ambiguities in pose and motion reconstruction methods. Yet, multi-view algorithms strongly depend on camera parameters, in particular, the relative positions among the cameras. Such dependency becomes a hurdle once shifting to dynamic capture in uncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), an end-to-end parameter-free multi-view model. FLEX is parameter-free in the sense that it does not require any camera parameters, neither intrinsic nor extrinsic. Our key idea is that the 3D angles between skeletal parts, as well as bone lengths, are invariant to the camera position. Hence, learning 3D rotations and bone lengths rather than locations allows predicting common values for all camera views. Our network takes multiple video streams, learns fused deep features through a novel multi-view fusion layer, and reconstructs a single consistent skeleton with temporally coherent joint rotations. We demonstrate quantitative and qualitative results on the Human3.6M and KTH Multi-view Football II datasets. We compare our model to state-of-the-art methods that are not parameter-free and show that in the absence of camera parameters, we outperform them by a large margin while obtaining comparable results when camera parameters are available. Code, trained models, video demonstration, and additional materials will be available on our project page.
Orienting Point Clouds with Dipole Propagation
May 04, 2021
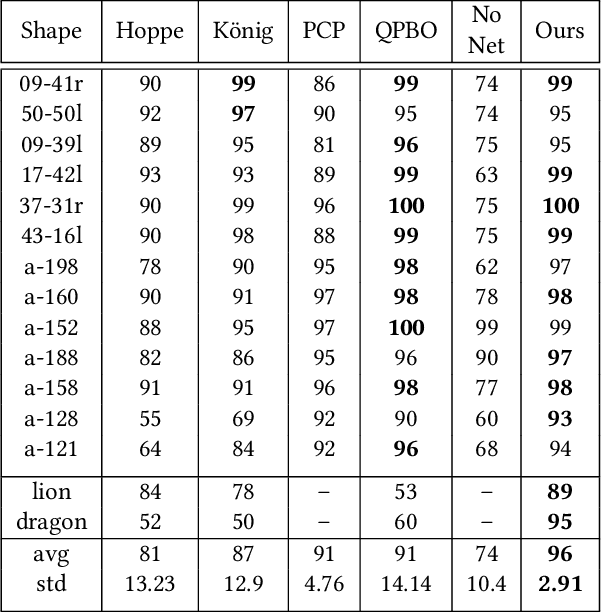
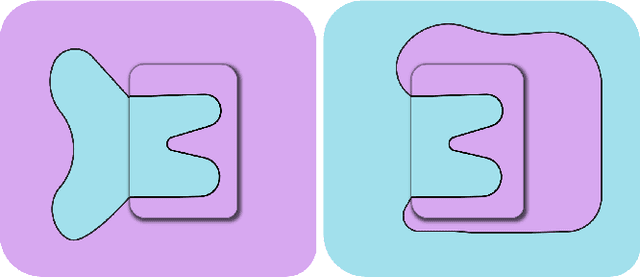
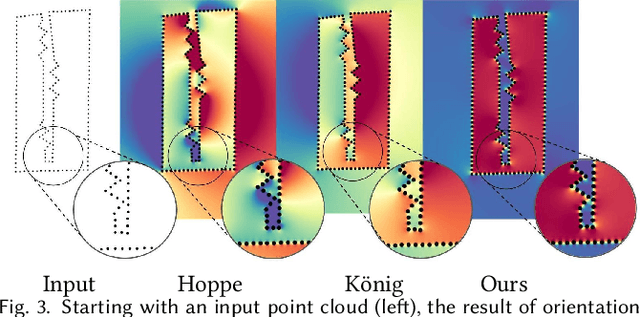
Establishing a consistent normal orientation for point clouds is a notoriously difficult problem in geometry processing, requiring attention to both local and global shape characteristics. The normal direction of a point is a function of the local surface neighborhood; yet, point clouds do not disclose the full underlying surface structure. Even assuming known geodesic proximity, calculating a consistent normal orientation requires the global context. In this work, we introduce a novel approach for establishing a globally consistent normal orientation for point clouds. Our solution separates the local and global components into two different sub-problems. In the local phase, we train a neural network to learn a coherent normal direction per patch (i.e., consistently oriented normals within a single patch). In the global phase, we propagate the orientation across all coherent patches using a dipole propagation. Our dipole propagation decides to orient each patch using the electric field defined by all previously orientated patches. This gives rise to a global propagation that is stable, as well as being robust to nearby surfaces, holes, sharp features and noise.
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021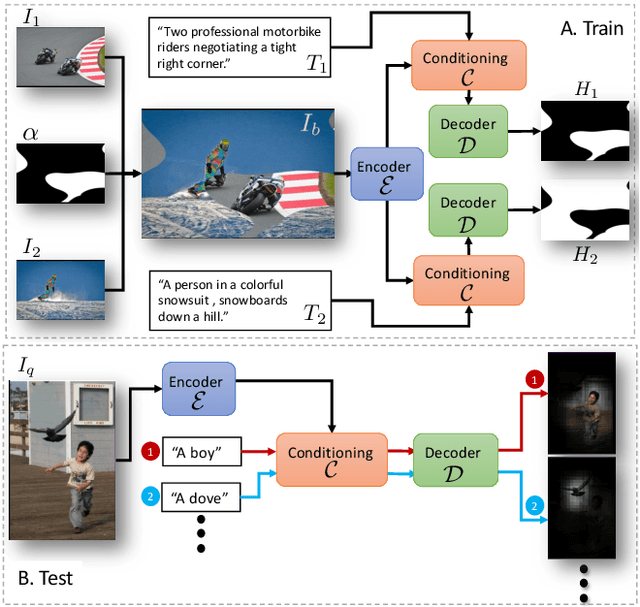
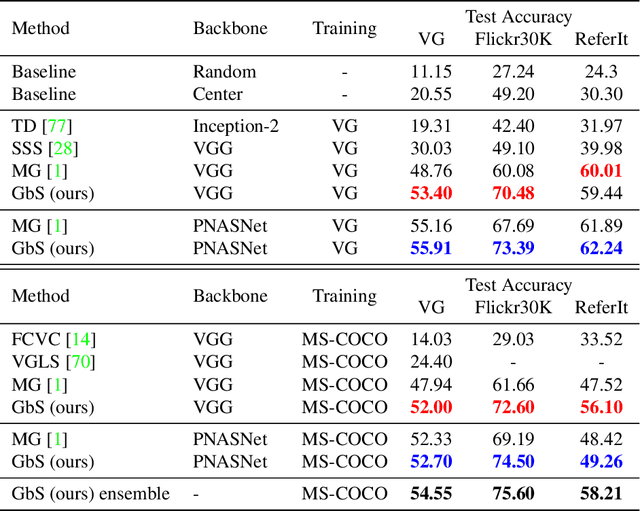
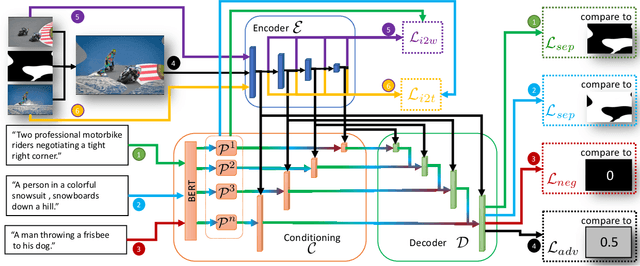
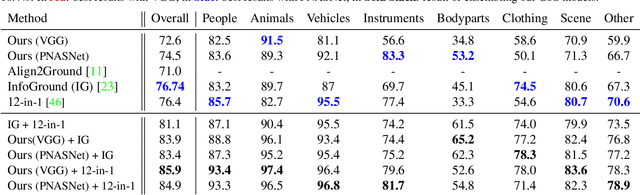
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
Progressive Encoding for Neural Optimization
Apr 19, 2021
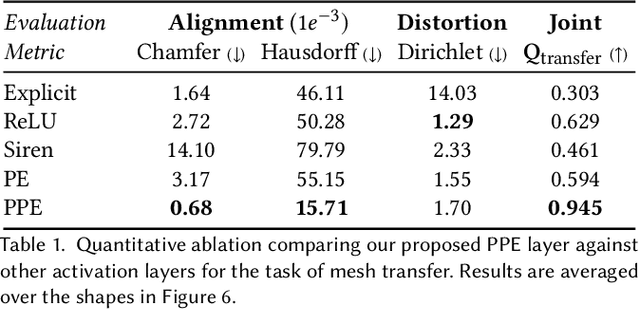
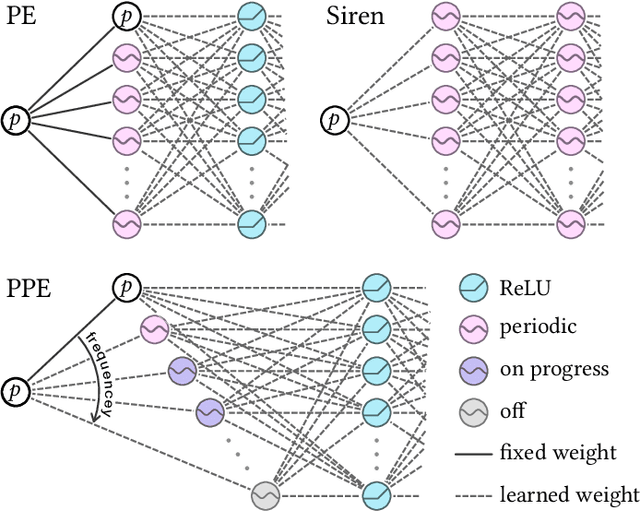
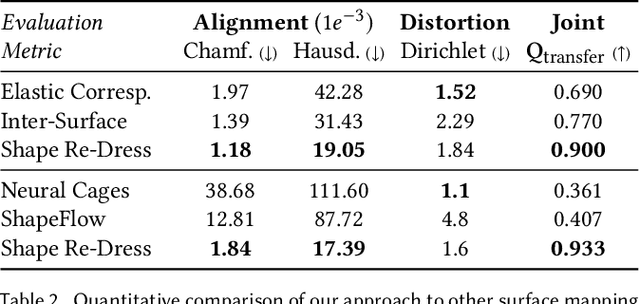
We introduce a Progressive Positional Encoding (PPE) layer, which gradually exposes signals with increasing frequencies throughout the neural optimization. In this paper, we show the competence of the PPE layer for mesh transfer and its advantages compared to contemporary surface mapping techniques. Our approach is simple and requires little user guidance. Most importantly, our technique is a parameterization-free method, and thus applicable to a variety of target shape representations, including point clouds, polygon soups, and non-manifold meshes. We demonstrate that the transferred meshing remains faithful to the source mesh design characteristics, and at the same time fits the target geometry well.
Multiplicative Reweighting for Robust Neural Network Optimization
Feb 24, 2021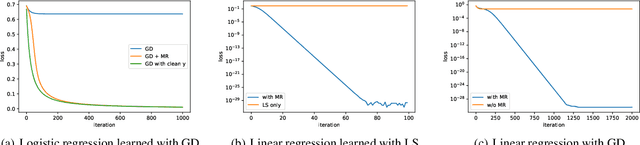
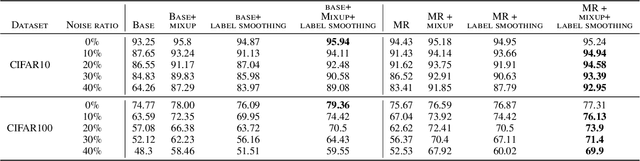
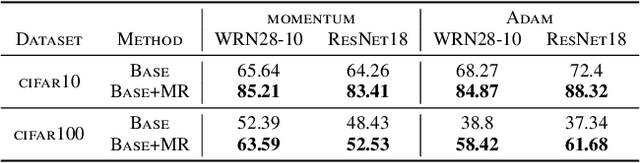
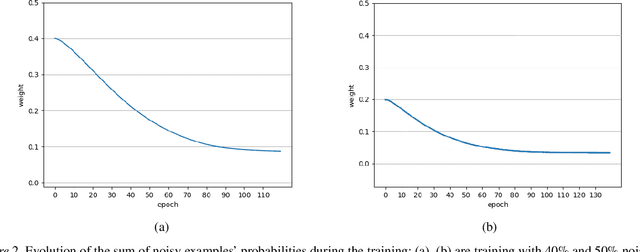
Deep neural networks are widespread due to their powerful performance. Yet, they suffer from degraded performance in the presence of noisy labels at train time or adversarial examples during inference. Inspired by the setting of learning with expert advice, where multiplicative weights (MW) updates were recently shown to be robust to moderate adversarial corruptions, we propose to use MW for reweighting examples during neural networks optimization. We establish the convergence of our method when used with gradient descent and demonstrate its advantage in two simple examples. We then validate empirically our findings by showing that MW improves network's accuracy in the presence of label noise on CIFAR-10, CIFAR-100 and Clothing1M, and that it leads to better robustness to adversarial attacks.
Separable Joint Blind Deconvolution and Demixing
Feb 04, 2021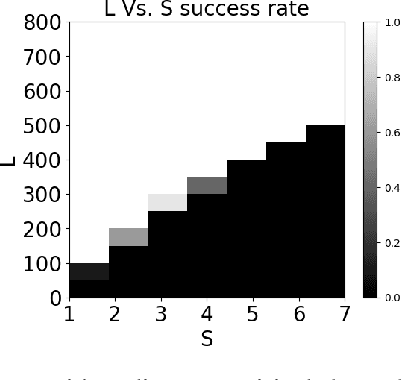
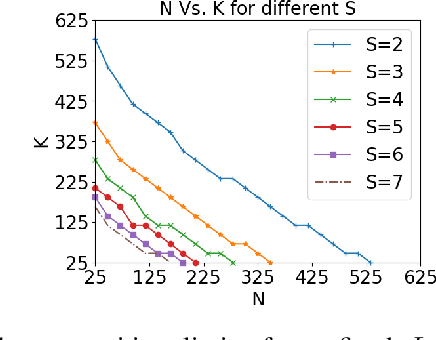
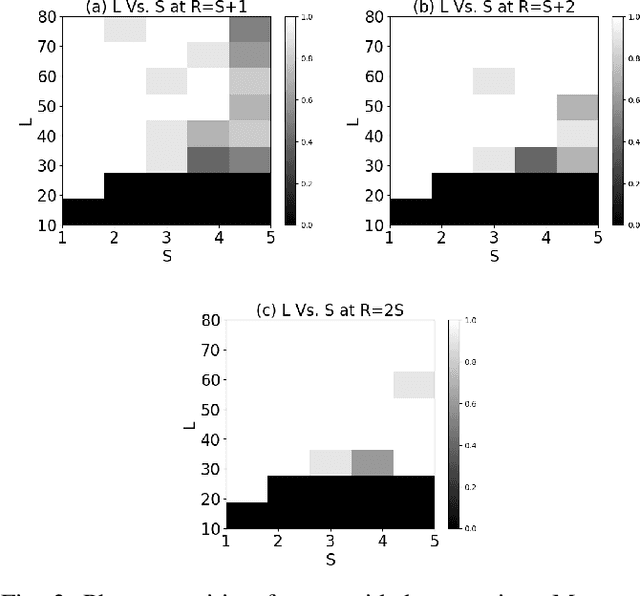
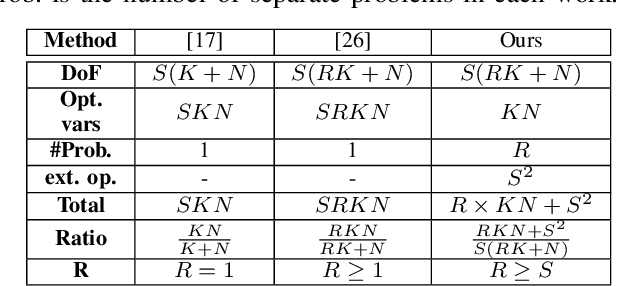
Blind deconvolution and demixing is the problem of reconstructing convolved signals and kernels from the sum of their convolutions. This problem arises in many applications, such as blind MIMO. This work presents a separable approach to blind deconvolution and demixing via convex optimization. Unlike previous works, our formulation allows separation into smaller optimization problems, which significantly improves complexity. We develop recovery guarantees, which comply with those of the original non-separable problem, and demonstrate the method performance under several normalization constraints.
Image Restoration by Deep Projected GSURE
Feb 04, 2021



Ill-posed inverse problems appear in many image processing applications, such as deblurring and super-resolution. In recent years, solutions that are based on deep Convolutional Neural Networks (CNNs) have shown great promise. Yet, most of these techniques, which train CNNs using external data, are restricted to the observation models that have been used in the training phase. A recent alternative that does not have this drawback relies on learning the target image using internal learning. One such prominent example is the Deep Image Prior (DIP) technique that trains a network directly on the input image with a least-squares loss. In this paper, we propose a new image restoration framework that is based on minimizing a loss function that includes a "projected-version" of the Generalized SteinUnbiased Risk Estimator (GSURE) and parameterization of the latent image by a CNN. We demonstrate two ways to use our framework. In the first one, where no explicit prior is used, we show that the proposed approach outperforms other internal learning methods, such as DIP. In the second one, we show that our GSURE-based loss leads to improved performance when used within a plug-and-play priors scheme.