 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXSRD-Net: EXplainable Stroke Relapse Detection
Sep 09, 2025



Stroke is the second most frequent cause of death world wide with an annual mortality of around 5.5 million. Recurrence rates of stroke are between 5 and 25% in the first year. As mortality rates for relapses are extraordinarily high (40%) it is of utmost importance to reduce the recurrence rates. We address this issue by detecting patients at risk of stroke recurrence at an early stage in order to enable appropriate therapy planning. To this end we collected 3D intracranial CTA image data and recorded concomitant heart diseases, the age and the gender of stroke patients between 2010 and 2024. We trained single- and multimodal deep learning based neural networks for binary relapse detection (Task 1) and for relapse free survival (RFS) time prediction together with a subsequent classification (Task 2). The separation of relapse from non-relapse patients (Task 1) could be solved with tabular data (AUC on test dataset: 0.84). However, for the main task, the regression (Task 2), our multimodal XSRD-net processed the modalities vision:tabular with 0.68:0.32 according to modality contribution measures. The c-index with respect to relapses for the multimodal model reached 0.68, and the AUC is 0.71 for the test dataset. Final, deeper interpretability analysis results could highlight a link between both heart diseases (tabular) and carotid arteries (vision) for the detection of relapses and the prediction of the RFS time. This is a central outcome that we strive to strengthen with ongoing data collection and model retraining.
Multimodal Medical Disease Classification with LLaMA II
Dec 02, 2024



Medical patient data is always multimodal. Images, text, age, gender, histopathological data are only few examples for different modalities in this context. Processing and integrating this multimodal data with deep learning based methods is of utmost interest due to its huge potential for medical procedure such as diagnosis and patient treatment planning. In this work we retrain a multimodal transformer-based model for disease classification. To this end we use the text-image pair dataset from OpenI consisting of 2D chest X-rays associated with clinical reports. Our focus is on fusion methods for merging text and vision information extracted from medical datasets. Different architecture structures with a LLaMA II backbone model are tested. Early fusion of modality specific features creates better results with the best model reaching 97.10% mean AUC than late fusion from a deeper level of the architecture (best model: 96.67% mean AUC). Both outperform former classification models tested on the same multimodal dataset. The newly introduced multimodal architecture can be applied to other multimodal datasets with little effort and can be easily adapted for further research, especially, but not limited to, the field of medical AI.
Tackling the Class Imbalance Problem of Deep Learning Based Head and Neck Organ Segmentation
Jan 05, 2022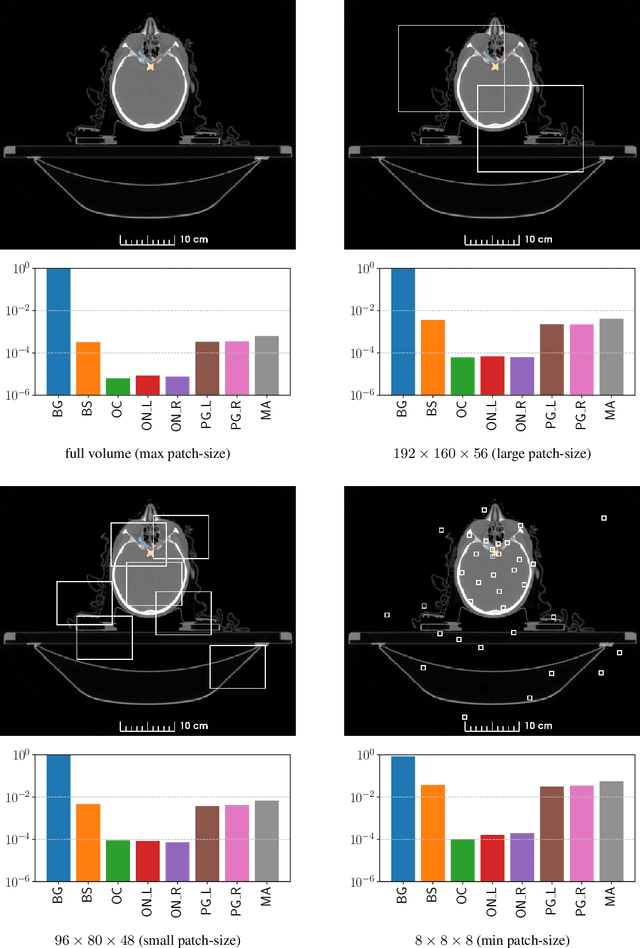
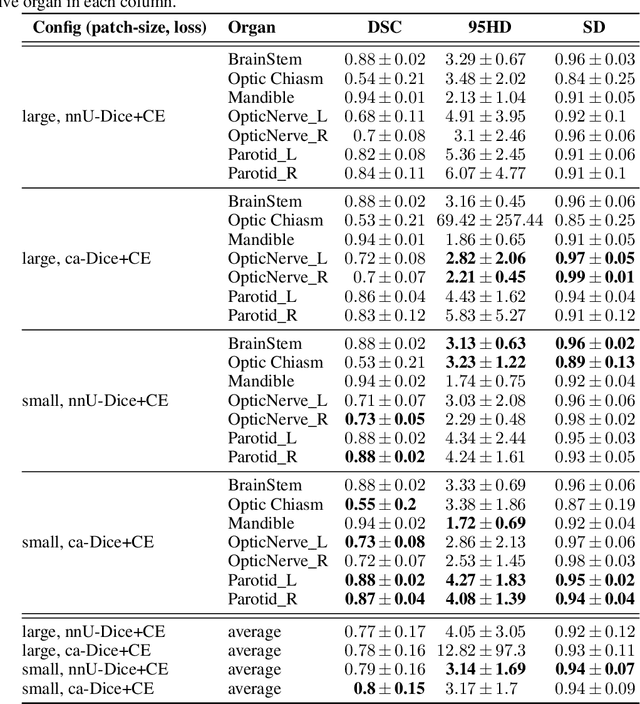
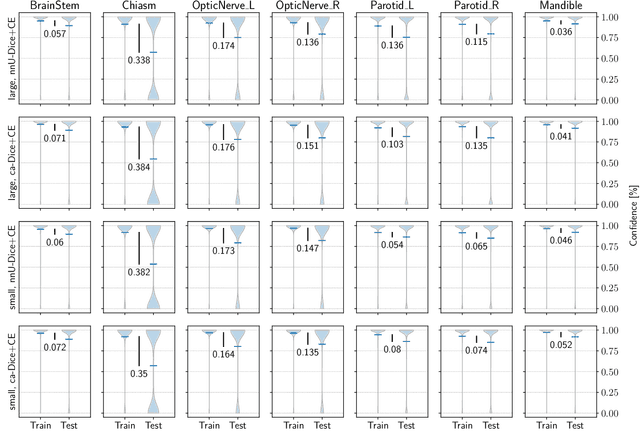
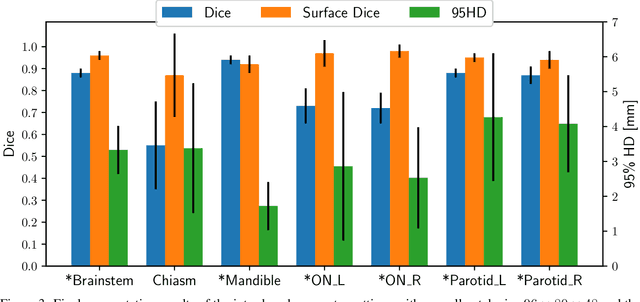
The segmentation of organs at risk (OAR) is a required precondition for the cancer treatment with image guided radiation therapy. The automation of the segmentation task is therefore of high clinical relevance. Deep Learning (DL) based medical image segmentation is currently the most successful approach, but suffers from the over-presence of the background class and the anatomically given organ size difference, which is most severe in the head and neck (HAN) area. To tackle the HAN area specific class imbalance problem we first optimize the patch-size of the currently best performing general purpose segmentation framework, the nnU-Net, based on the introduced class imbalance measurement, and second, introduce the class adaptive Dice loss to further compensate for the highly imbalanced setting. Both the patch-size and the loss function are parameters with direct influence on the class imbalance and their optimization leads to a 3\% increase of the Dice score and 22% reduction of the 95% Hausdorff distance compared to the baseline, finally reaching $0.8\pm0.15$ and $3.17\pm1.7$ mm for the segmentation of seven HAN organs using a single and simple neural network. The patch-size optimization and the class adaptive Dice loss are both simply integrable in current DL based segmentation approaches and allow to increase the performance for class imbalanced segmentation tasks.