 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Signatures of Early-stage Dementia with Behavioural Models Derived from Sensor Data
Jul 03, 2020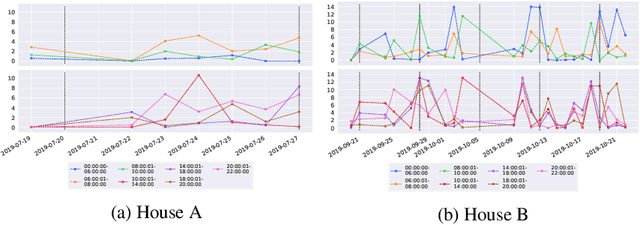
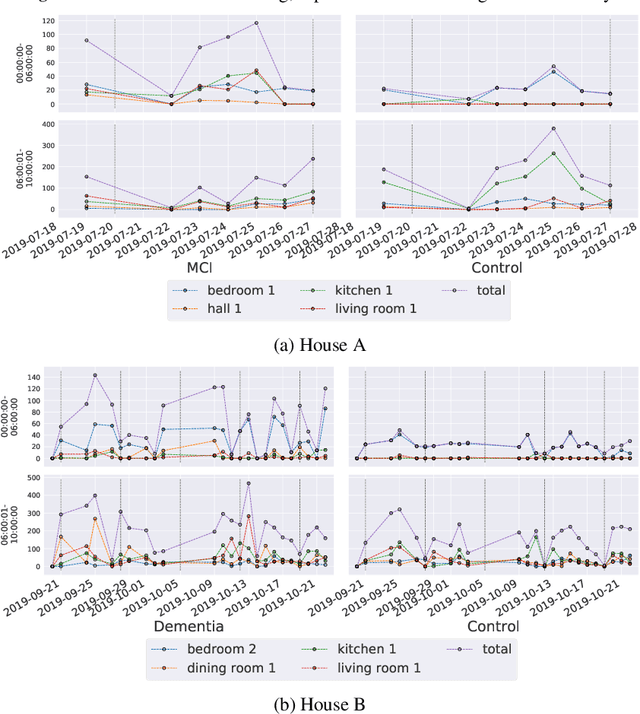
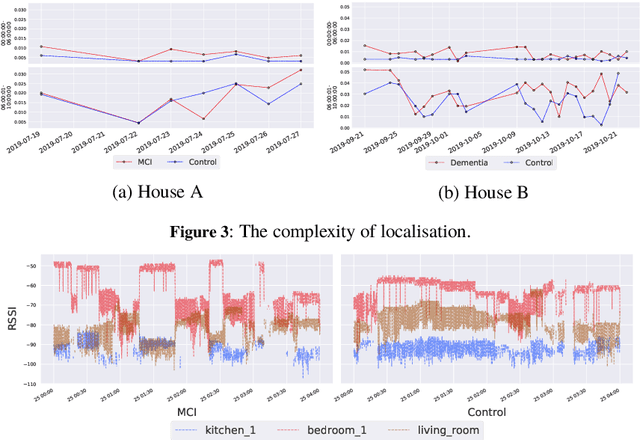
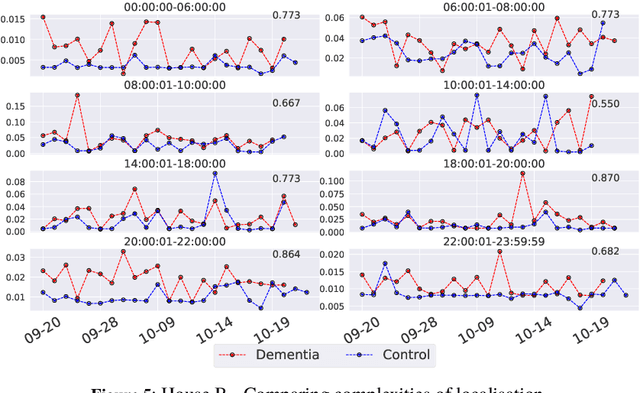
There is a pressing need to automatically understand the state and progression of chronic neurological diseases such as dementia. The emergence of state-of-the-art sensing platforms offers unprecedented opportunities for indirect and automatic evaluation of disease state through the lens of behavioural monitoring. This paper specifically seeks to characterise behavioural signatures of mild cognitive impairment (MCI) and Alzheimer's disease (AD) in the \textit{early} stages of the disease. We introduce bespoke behavioural models and analyses of key symptoms and deploy these on a novel dataset of longitudinal sensor data from persons with MCI and AD. We present preliminary findings that show the relationship between levels of sleep quality and wandering can be subtly different between patients in the early stages of dementia and healthy cohabiting controls.
FACE: Feasible and Actionable Counterfactual Explanations
Sep 20, 2019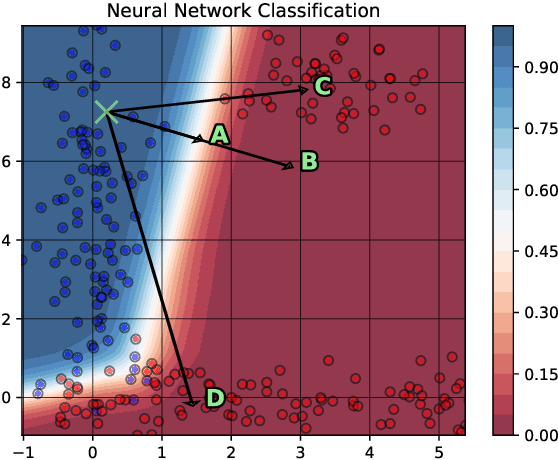
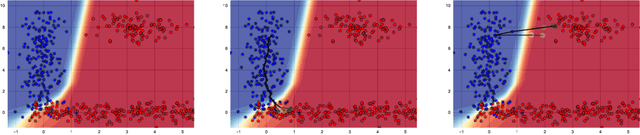
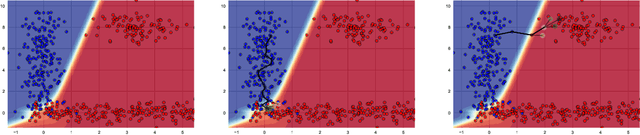
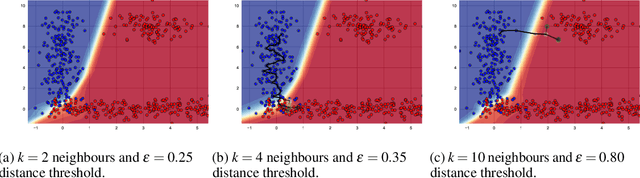
Work in Counterfactual Explanations tends to focus on the principle of ``the closest possible world'' that identifies small changes leading to the desired outcome. In this paper we argue that while this approach might initially seem intuitively appealing it exhibits shortcomings not addressed in the current literature. First, a counterfactual example generated by the state-of-the-art systems is not necessarily representative of the underlying data distribution, and may therefore prescribe unachievable goals(e.g., an unsuccessful life insurance applicant with severe disability may be advised to do more sports). Secondly, the counterfactuals may not be based on a ``feasible path'' between the current state of the subject and the suggested one, making actionable recourse infeasible (e.g., low-skilled unsuccessful mortgage applicants may be told to double their salary, which may be hard without first increasing their skill level). These two shortcomings may render counterfactual explanations impractical and sometimes outright offensive. To address these two major flaws, first of all, we propose a new line of Counterfactual Explanations research aimed at providing actionable and feasible paths to transform a selected instance into one that meets a certain goal. Secondly, we propose FACE: an algorithmically sound way of uncovering these ``feasible paths'' based on the shortest path distances defined via density-weighted metrics. Our approach generates counterfactuals that are coherent with the underlying data distribution and supported by the ``feasible paths'' of change, which are achievable and can be tailored to the problem at hand.
Ordinal Regression as Structured Classification
May 31, 2019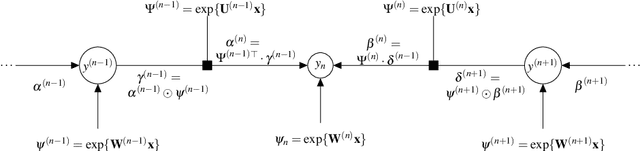
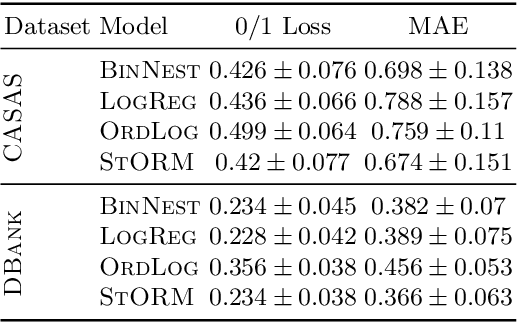
This paper extends the class of ordinal regression models with a structured interpretation of the problem by applying a novel treatment of encoded labels. The net effect of this is to transform the underlying problem from an ordinal regression task to a (structured) classification task which we solve with conditional random fields, thereby achieving a coherent and probabilistic model in which all model parameters are jointly learnt. Importantly, we show that although we have cast ordinal regression to classification, our method still fall within the class of decomposition methods in the ordinal regression ontology. This is an important link since our experience is that many applications of machine learning to healthcare ignores completely the important nature of the label ordering, and hence these approaches should considered naive in this ontology. We also show that our model is flexible both in how it adapts to data manifolds and in terms of the operations that are available for practitioner to execute. Our empirical evaluation demonstrates that the proposed approach overwhelmingly produces superior and often statistically significant results over baseline approaches on forty popular ordinal regression models, and demonstrate that the proposed model significantly out-performs baselines on synthetic and real datasets. Our implementation, together with scripts to reproduce the results of this work, will be available on a public GitHub repository.
Label Propagation for Learning with Label Proportions
Oct 24, 2018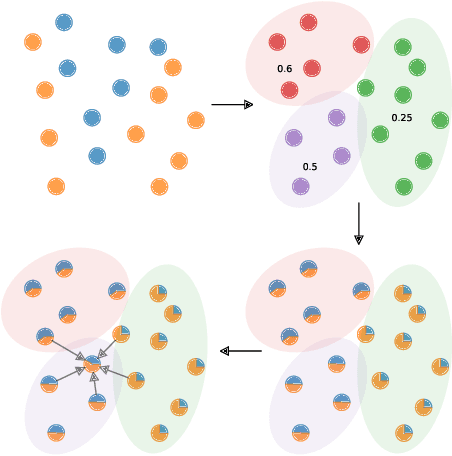
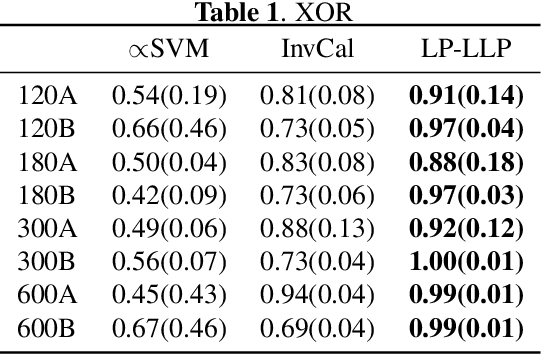
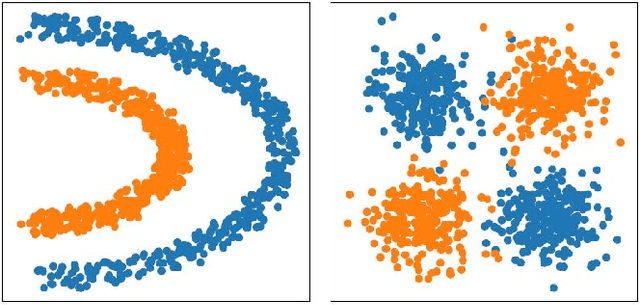
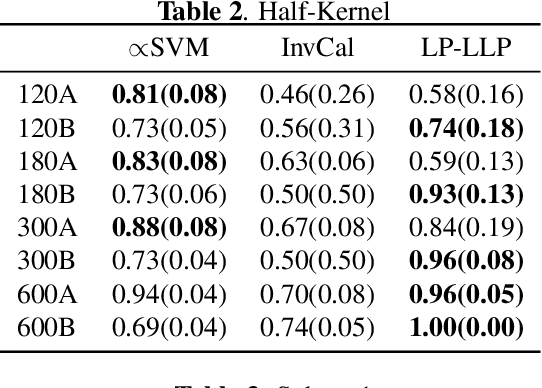
Learning with Label Proportions (LLP) is the problem of recovering the underlying true labels given a dataset when the data is presented in the form of bags. This paradigm is particularly suitable in contexts where providing individual labels is expensive and label aggregates are more easily obtained. In the healthcare domain, it is a burden for a patient to keep a detailed diary of their daily routines, but often they will be amenable to provide higher level summaries of daily behavior. We present a novel and efficient graph-based algorithm that encourages local smoothness and exploits the global structure of the data, while preserving the `mass' of each bag.