 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQ-Ladder: A Deep Reinforcement Learning-based Bitrate Ladder for Adaptive Video Streaming
Mar 13, 2026Adaptive streaming of segmented video over HTTP typically relies on a predefined set of bitrate-resolution pairs, known as a bitrate ladder. However, fixed ladders often overlook variations in content and decoding complexities, leading to suboptimal trade-offs between encoding time, decoding efficiency, and video quality. This article introduces DQ-Ladder, a deep reinforcement learning (DRL)-based scheme for constructing time- and quality-aware bitrate ladders for adaptive video streaming applications. DQ-Ladder employs predicted decoding time, quality scores, and bitrate levels per segment as inputs to a Deep Q-Network (DQN) agent, guided by a weighted reward function of decoding time, video quality, and resolution smoothness. We leverage machine learning models to predict decoding time, bitrate level, and objective quality metrics (VMAF, XPSNR), eliminating the need for exhaustive encoding or quality metric computation. We evaluate DQ-Ladder using the Versatile Video Coding (VVC) toolchain (VVenC/VVdeC) on 750 video sequences across six Apple HLS-compliant resolutions and 41 quantization parameters. Experimental results against four baselines show that DQ-Ladder achieves BD-rate reductions of at least 10.3% for XPSNR compared to the HLS ladder, while reducing decoding time by 22%. DQ-Ladder shows significantly lower sensitivity to prediction errors than competing methods, remaining robust even with up to 20% noise.
Osmotic Learning: A Self-Supervised Paradigm for Decentralized Contextual Data Representation
Dec 28, 2025Data within a specific context gains deeper significance beyond its isolated interpretation. In distributed systems, interdependent data sources reveal hidden relationships and latent structures, representing valuable information for many applications. This paper introduces Osmotic Learning (OSM-L), a self-supervised distributed learning paradigm designed to uncover higher-level latent knowledge from distributed data. The core of OSM-L is osmosis, a process that synthesizes dense and compact representation by extracting contextual information, eliminating the need for raw data exchange between distributed entities. OSM-L iteratively aligns local data representations, enabling information diffusion and convergence into a dynamic equilibrium that captures contextual patterns. During training, it also identifies correlated data groups, functioning as a decentralized clustering mechanism. Experimental results confirm OSM-L's convergence and representation capabilities on structured datasets, achieving over 0.99 accuracy in local information alignment while preserving contextual integrity.
YawDD+: Frame-level Annotations for Accurate Yawn Prediction
Dec 15, 2025Driver fatigue remains a leading cause of road accidents, with 24% of crashes involving drowsy drivers. While yawning serves as an early behavioral indicator of fatigue, existing machine learning approaches face significant challenges due to video-annotated datasets that introduce systematic noise from coarse temporal annotations. We develop a semi-automated labeling pipeline with human-in-the-loop verification, which we apply to YawDD, enabling more accurate model training. Training the established MNasNet classifier and YOLOv11 detector architectures on YawDD+ improves frame accuracy by up to 6% and mAP by 5% over video-level supervision, achieving 99.34% classification accuracy and 95.69% detection mAP. The resulting approach deliver up to 59.8 FPS on edge AI hardware (NVIDIA Jetson Nano), confirming that enhanced data quality alone supports on-device yawning monitoring without server-side computation.
Federated Distillation on Edge Devices: Efficient Client-Side Filtering for Non-IID Data
Aug 20, 2025Federated distillation has emerged as a promising collaborative machine learning approach, offering enhanced privacy protection and reduced communication compared to traditional federated learning by exchanging model outputs (soft logits) rather than full model parameters. However, existing methods employ complex selective knowledge-sharing strategies that require clients to identify in-distribution proxy data through computationally expensive statistical density ratio estimators. Additionally, server-side filtering of ambiguous knowledge introduces latency to the process. To address these challenges, we propose a robust, resource-efficient EdgeFD method that reduces the complexity of the client-side density ratio estimation and removes the need for server-side filtering. EdgeFD introduces an efficient KMeans-based density ratio estimator for effectively filtering both in-distribution and out-of-distribution proxy data on clients, significantly improving the quality of knowledge sharing. We evaluate EdgeFD across diverse practical scenarios, including strong non-IID, weak non-IID, and IID data distributions on clients, without requiring a pre-trained teacher model on the server for knowledge distillation. Experimental results demonstrate that EdgeFD outperforms state-of-the-art methods, consistently achieving accuracy levels close to IID scenarios even under heterogeneous and challenging conditions. The significantly reduced computational overhead of the KMeans-based estimator is suitable for deployment on resource-constrained edge devices, thereby enhancing the scalability and real-world applicability of federated distillation. The code is available online for reproducibility.
Decentralized Machine Learning for Intelligent Health Care Systems on the Computing Continuum
Jul 29, 2022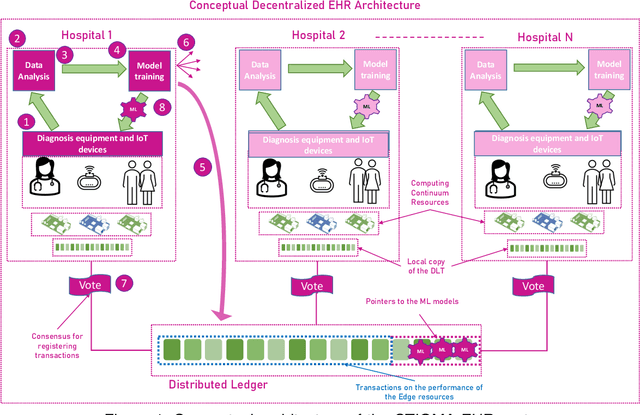
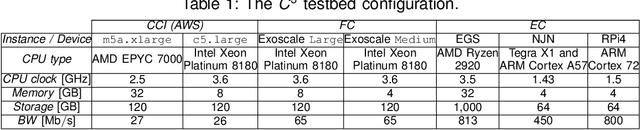
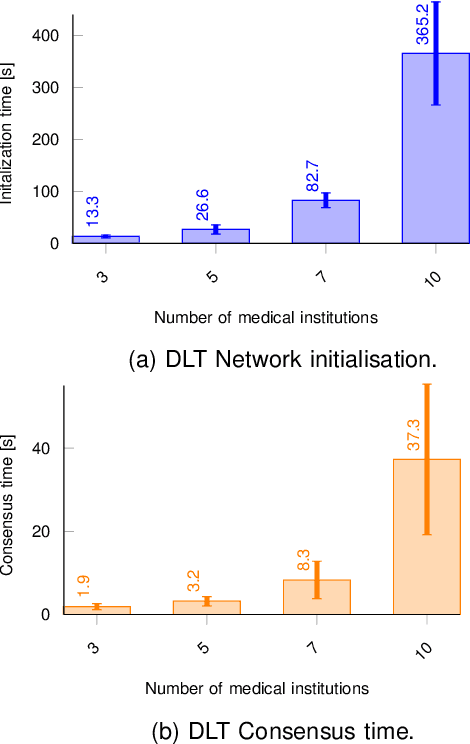
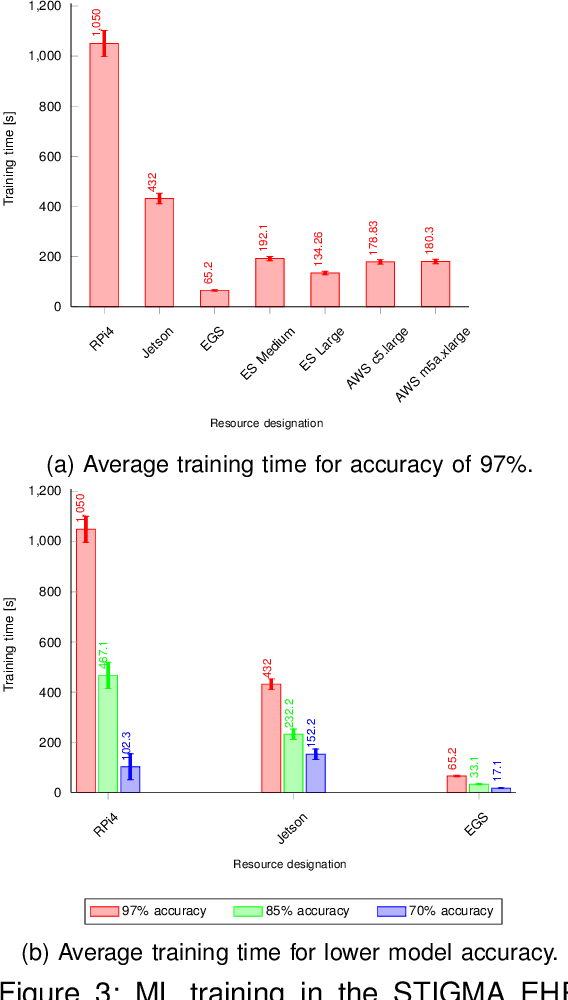
The introduction of electronic personal health records (EHR) enables nationwide information exchange and curation among different health care systems. However, the current EHR systems do not provide transparent means for diagnosis support, medical research or can utilize the omnipresent data produced by the personal medical devices. Besides, the EHR systems are centrally orchestrated, which could potentially lead to a single point of failure. Therefore, in this article, we explore novel approaches for decentralizing machine learning over distributed ledgers to create intelligent EHR systems that can utilize information from personal medical devices for improved knowledge extraction. Consequently, we proposed and evaluated a conceptual EHR to enable anonymous predictive analysis across multiple medical institutions. The evaluation results indicate that the decentralized EHR can be deployed over the computing continuum with reduced machine learning time of up to 60% and consensus latency of below 8 seconds.