 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Axis Weight Deltas for Frequent Model Updates
Dec 16, 2025Serving many task-specialized LLM variants is often limited by the large size of fine-tuned checkpoints and the resulting cold-start latency. Since fine-tuned weights differ from their base model by relatively small structured residuals, a natural approach is to represent them as compressed deltas. We propose a simple 1-bit delta scheme that stores only the sign of the weight difference together with lightweight per-axis (row/column) FP16 scaling factors, learned from a small calibration set. This design preserves the compactness of 1-bit deltas while more accurately capturing variation across weight dimensions, leading to improved reconstruction quality over scalar alternatives. From a systems perspective, a streamlined loader that transfers packed deltas in a single operation per module reduces cold-start latency and storage overhead, with artifacts several times smaller than a full FP16 checkpoint. The method is drop-in, requires minimal calibration data, and maintains inference efficiency by avoiding dense reconstruction. Our experimental setup and source code are available at https://github.com/kuiumdjiev/Per-Axis-Weight-Deltas-for-Frequent-Model-Updates.
ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning
Jul 29, 2024



Generative models, such as diffusion models (DMs), variational autoencoders (VAEs), and generative adversarial networks (GANs), produce images with a level of authenticity that makes them nearly indistinguishable from real photos and artwork. While this capability is beneficial for many industries, the difficulty of identifying synthetic images leaves online media platforms vulnerable to impersonation and misinformation attempts. To support the development of defensive methods, we introduce ImagiNet, a high-resolution and balanced dataset for synthetic image detection, designed to mitigate potential biases in existing resources. It contains 200K examples, spanning four content categories: photos, paintings, faces, and uncategorized. Synthetic images are produced with open-source and proprietary generators, whereas real counterparts of the same content type are collected from public datasets. The structure of ImagiNet allows for a two-track evaluation system: i) classification as real or synthetic and ii) identification of the generative model. To establish a baseline, we train a ResNet-50 model using a self-supervised contrastive objective (SelfCon) for each track. The model demonstrates state-of-the-art performance and high inference speed across established benchmarks, achieving an AUC of up to 0.99 and balanced accuracy ranging from 86% to 95%, even under social network conditions that involve compression and resizing. Our data and code are available at https://github.com/delyan-boychev/imaginet.
Fast Matrix Multiplications for Lookup Table-Quantized LLMs
Jul 15, 2024



The deployment of large language models (LLMs) is often constrained by memory bandwidth, where the primary bottleneck is the cost of transferring model parameters from the GPU's global memory to its registers. When coupled with custom kernels that fuse the dequantization and matmul operations, weight-only quantization can thus enable faster inference by reducing the amount of memory movement. However, developing high-performance kernels for weight-quantized LLMs presents substantial challenges, especially when the weights are compressed to non-evenly-divisible bit widths (e.g., 3 bits) with non-uniform, lookup table (LUT) quantization. This paper describes FLUTE, a flexible lookup table engine for LUT-quantized LLMs, which uses offline restructuring of the quantized weight matrix to minimize bit manipulations associated with unpacking, and vectorization and duplication of the lookup table to mitigate shared memory bandwidth constraints. At batch sizes < 32 and quantization group size of 128 (typical in LLM inference), the FLUTE kernel can be 2-4x faster than existing GEMM kernels. As an application of FLUTE, we explore a simple extension to lookup table-based NormalFloat quantization and apply it to quantize LLaMA3 to various configurations, obtaining competitive quantization performance against strong baselines while obtaining an end-to-end throughput increase of 1.5 to 2 times.
Efficient Task-Oriented Dialogue Systems with Response Selection as an Auxiliary Task
Aug 15, 2022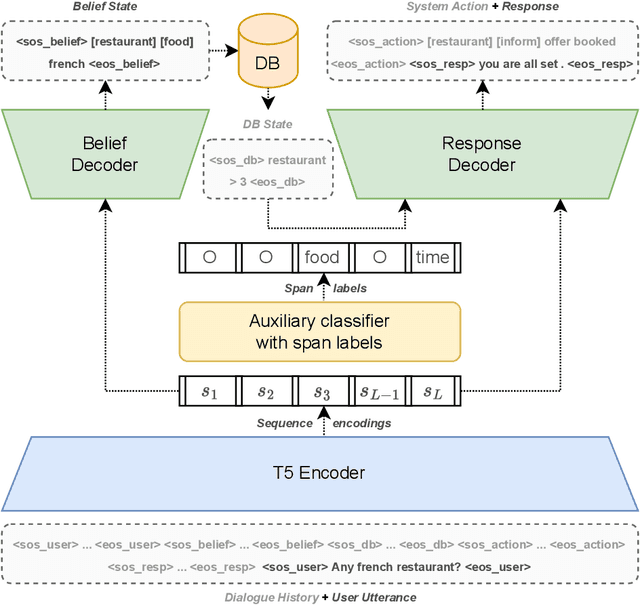
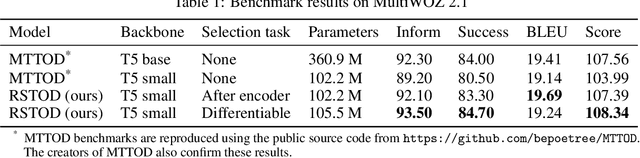
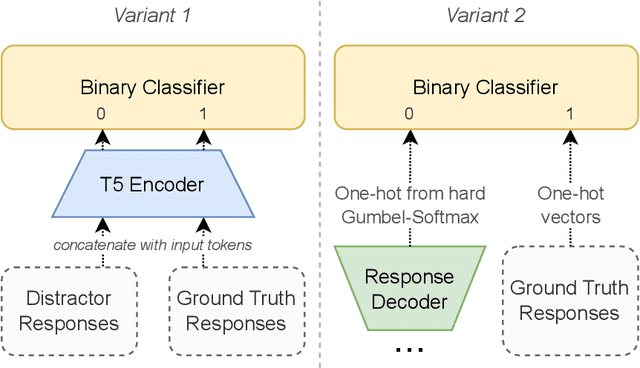
The adoption of pre-trained language models in task-oriented dialogue systems has resulted in significant enhancements of their text generation abilities. However, these architectures are slow to use because of the large number of trainable parameters and can sometimes fail to generate diverse responses. To address these limitations, we propose two models with auxiliary tasks for response selection - (1) distinguishing distractors from ground truth responses and (2) distinguishing synthetic responses from ground truth labels. They achieve state-of-the-art results on the MultiWOZ 2.1 dataset with combined scores of 107.5 and 108.3 and outperform a baseline with three times more parameters. We publish reproducible code and checkpoints and discuss the effects of applying auxiliary tasks to T5-based architectures.
The GatedTabTransformer. An enhanced deep learning architecture for tabular modeling
Jan 01, 2022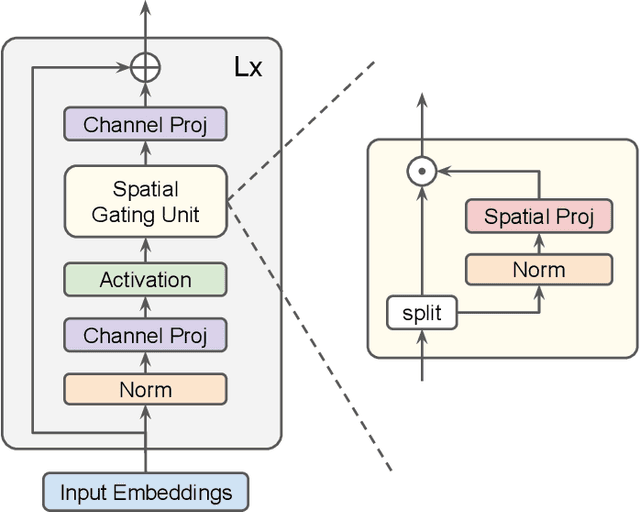
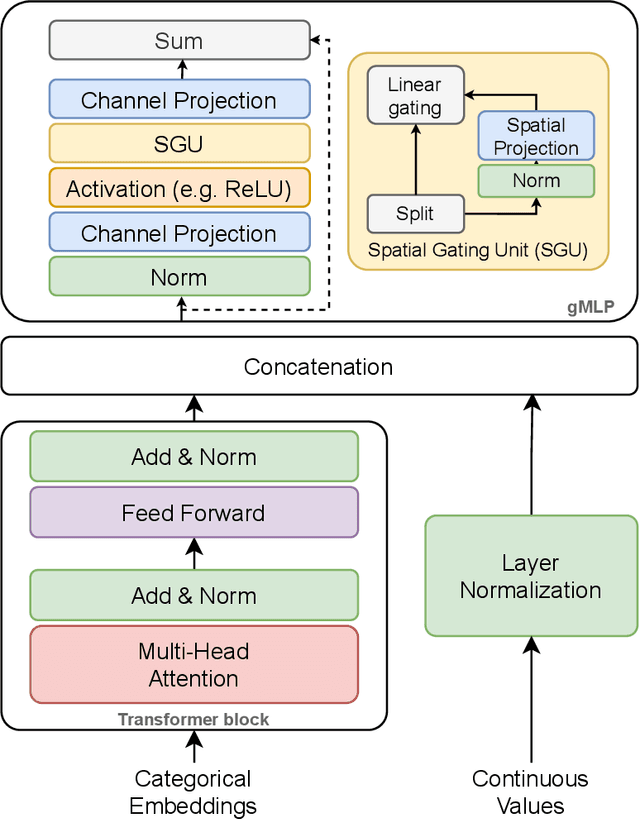
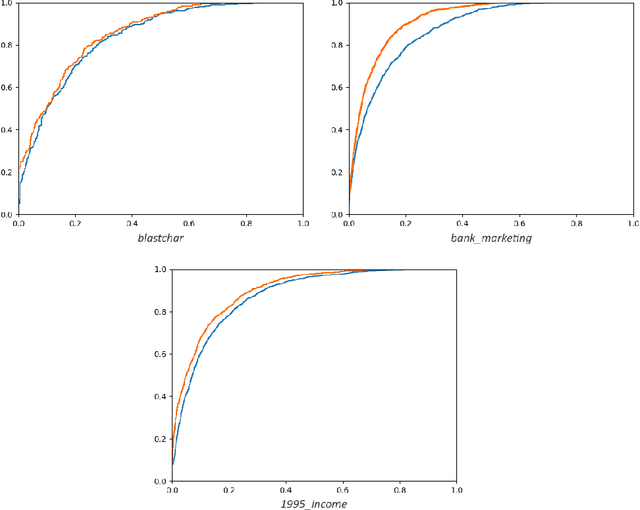
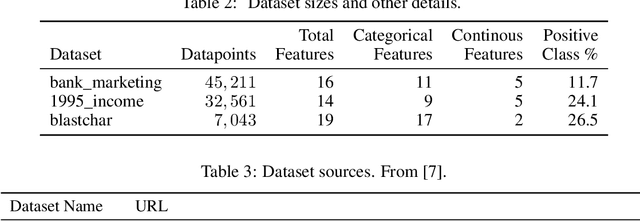
There is an increasing interest in the application of deep learning architectures to tabular data. One of the state-of-the-art solutions is TabTransformer which incorporates an attention mechanism to better track relationships between categorical features and then makes use of a standard MLP to output its final logits. In this paper we propose multiple modifications to the original TabTransformer performing better on binary classification tasks for three separate datasets with more than 1% AUROC gains. Inspired by gated MLP, linear projections are implemented in the MLP block and multiple activation functions are tested. We also evaluate the importance of specific hyper parameters during training.
Transformers predicting the future. Applying attention in next-frame and time series forecasting
Aug 18, 2021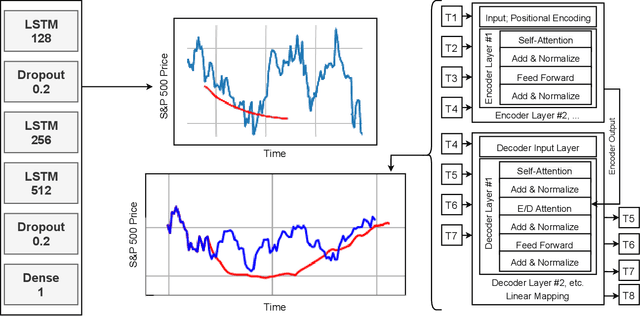

Recurrent Neural Networks were, until recently, one of the best ways to capture the timely dependencies in sequences. However, with the introduction of the Transformer, it has been proven that an architecture with only attention-mechanisms without any RNN can improve on the results in various sequence processing tasks (e.g. NLP). Multiple studies since then have shown that similar approaches can be applied for images, point clouds, video, audio or time series forecasting. Furthermore, solutions such as the Perceiver or the Informer have been introduced to expand on the applicability of the Transformer. Our main objective is testing and evaluating the effectiveness of applying Transformer-like models on time series data, tackling susceptibility to anomalies, context awareness and space complexity by fine-tuning the hyperparameters, preprocessing the data, applying dimensionality reduction or convolutional encodings, etc. We are also looking at the problem of next-frame prediction and exploring ways to modify existing solutions in order to achieve higher performance and learn generalized knowledge.