 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Effect of State Representation on LLM Agent Behavior in Dynamic Routing Games
Jun 18, 2025Large Language Models (LLMs) have shown promise as decision-makers in dynamic settings, but their stateless nature necessitates creating a natural language representation of history. We present a unifying framework for systematically constructing natural language "state" representations for prompting LLM agents in repeated multi-agent games. Previous work on games with LLM agents has taken an ad hoc approach to encoding game history, which not only obscures the impact of state representation on agents' behavior, but also limits comparability between studies. Our framework addresses these gaps by characterizing methods of state representation along three axes: action informativeness (i.e., the extent to which the state representation captures actions played); reward informativeness (i.e., the extent to which the state representation describes rewards obtained); and prompting style (or natural language compression, i.e., the extent to which the full text history is summarized). We apply this framework to a dynamic selfish routing game, chosen because it admits a simple equilibrium both in theory and in human subject experiments \cite{rapoport_choice_2009}. Despite the game's relative simplicity, we find that there are key dependencies of LLM agent behavior on the natural language state representation. In particular, we observe that representations which provide agents with (1) summarized, rather than complete, natural language representations of past history; (2) information about regrets, rather than raw payoffs; and (3) limited information about others' actions lead to behavior that more closely matches game theoretic equilibrium predictions, and with more stable game play by the agents. By contrast, other representations can exhibit either large deviations from equilibrium, higher variation in dynamic game play over time, or both.
Enhancing Poaching Predictions for Under-Resourced Wildlife Conservation Parks Using Remote Sensing Imagery
Nov 20, 2020
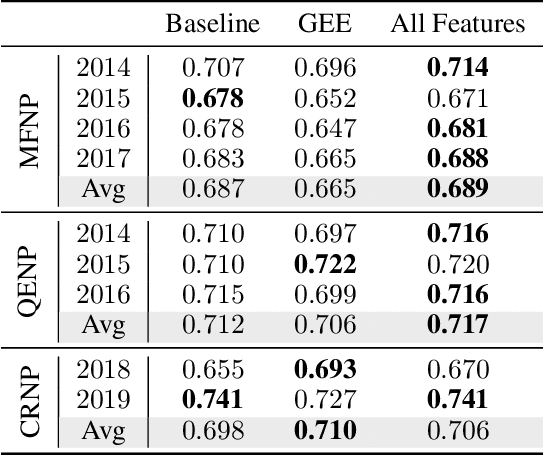
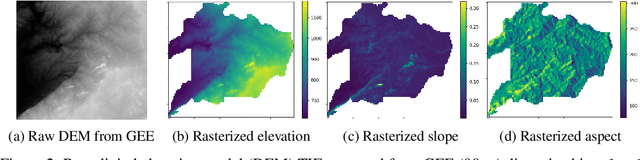
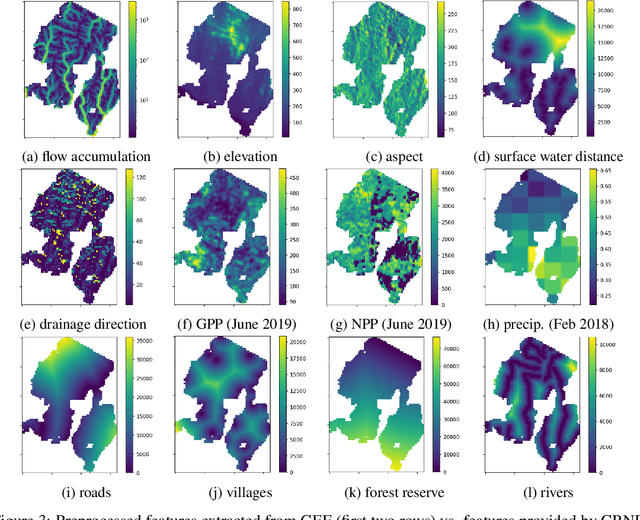
Illegal wildlife poaching is driving the loss of biodiversity. To combat poaching, rangers patrol expansive protected areas for illegal poaching activity. However, rangers often cannot comprehensively search such large parks. Thus, the Protection Assistant for Wildlife Security (PAWS) was introduced as a machine learning approach to help identify the areas with highest poaching risk. As PAWS is deployed to parks around the world, we recognized that many parks have limited resources for data collection and therefore have scarce feature sets. To ensure under-resourced parks have access to meaningful poaching predictions, we introduce the use of publicly available remote sensing data to extract features for parks. By employing this data from Google Earth Engine, we also incorporate previously unavailable dynamic data to enrich predictions with seasonal trends. We automate the entire data-to-deployment pipeline and find that, with only using publicly available data, we recuperate prediction performance comparable to predictions made using features manually computed by park specialists. We conclude that the inclusion of satellite imagery creates a robust system through which parks of any resource level can benefit from poaching risks for years to come.