 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuneVLSeg: Prompt Tuning Benchmark for Vision-Language Segmentation Models
Oct 07, 2024



Vision-Language Models (VLMs) have shown impressive performance in vision tasks, but adapting them to new domains often requires expensive fine-tuning. Prompt tuning techniques, including textual, visual, and multimodal prompting, offer efficient alternatives by leveraging learnable prompts. However, their application to Vision-Language Segmentation Models (VLSMs) and evaluation under significant domain shifts remain unexplored. This work presents an open-source benchmarking framework, TuneVLSeg, to integrate various unimodal and multimodal prompt tuning techniques into VLSMs, making prompt tuning usable for downstream segmentation datasets with any number of classes. TuneVLSeg includes $6$ prompt tuning strategies on various prompt depths used in $2$ VLSMs totaling of $8$ different combinations. We test various prompt tuning on $8$ diverse medical datasets, including $3$ radiology datasets (breast tumor, echocardiograph, chest X-ray pathologies) and $5$ non-radiology datasets (polyp, ulcer, skin cancer), and two natural domain segmentation datasets. Our study found that textual prompt tuning struggles under significant domain shifts, from natural-domain images to medical data. Furthermore, visual prompt tuning, with fewer hyperparameters than multimodal prompt tuning, often achieves performance competitive to multimodal approaches, making it a valuable first attempt. Our work advances the understanding and applicability of different prompt-tuning techniques for robust domain-specific segmentation. The source code is available at https://github.com/naamiinepal/tunevlseg.
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
May 10, 2024Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning. The source code is available at: https://github.com/naamiinepal/vlsm-adapter.
Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
Sep 22, 2023Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at https://github.com/naamiinepal/synthetic-boost.
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Aug 15, 2023

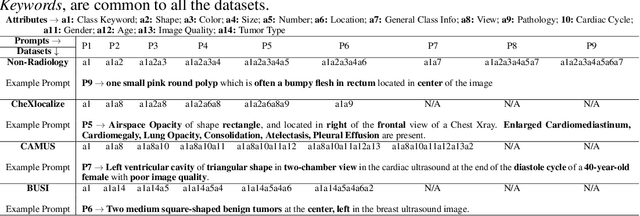

Medical Image Segmentation is crucial in various clinical applications within the medical domain. While state-of-the-art segmentation models have proven effective, integrating textual guidance to enhance visual features for this task remains an area with limited progress. Existing segmentation models that utilize textual guidance are primarily trained on open-domain images, raising concerns about their direct applicability in the medical domain without manual intervention or fine-tuning. To address these challenges, we propose using multimodal vision-language models for capturing semantic information from image descriptions and images, enabling the segmentation of diverse medical images. This study comprehensively evaluates existing vision language models across multiple datasets to assess their transferability from the open domain to the medical field. Furthermore, we introduce variations of image descriptions for previously unseen images in the dataset, revealing notable variations in model performance based on the generated prompts. Our findings highlight the distribution shift between the open-domain images and the medical domain and show that the segmentation models trained on open-domain images are not directly transferrable to the medical field. But their performance can be increased by finetuning them in the medical datasets. We report the zero-shot and finetuned segmentation performance of 4 Vision Language Models (VLMs) on 11 medical datasets using 9 types of prompts derived from 14 attributes.
COVID-19-related Nepali Tweets Classification in a Low Resource Setting
Oct 11, 2022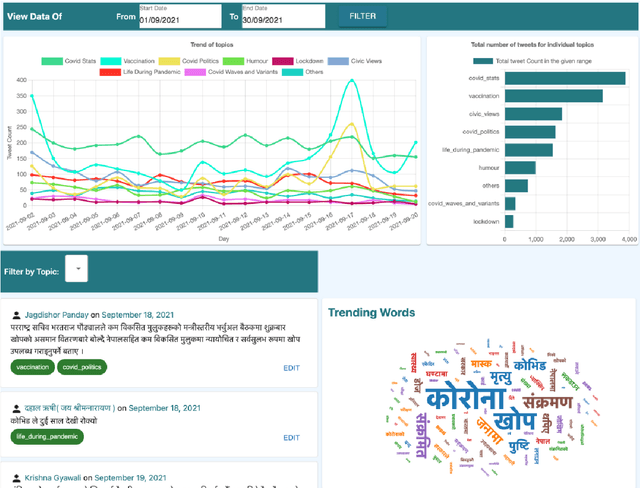
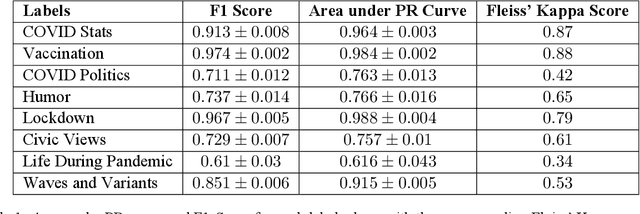
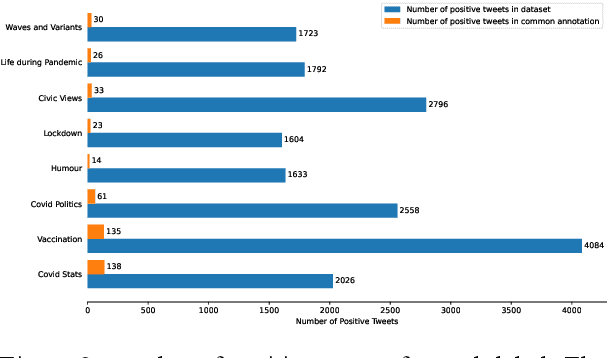
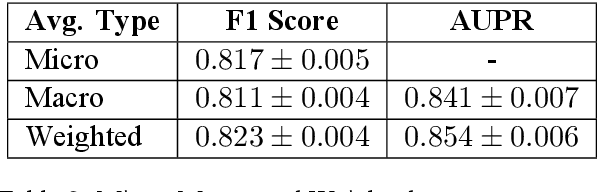
Billions of people across the globe have been using social media platforms in their local languages to voice their opinions about the various topics related to the COVID-19 pandemic. Several organizations, including the World Health Organization, have developed automated social media analysis tools that classify COVID-19-related tweets into various topics. However, these tools that help combat the pandemic are limited to very few languages, making several countries unable to take their benefit. While multi-lingual or low-resource language-specific tools are being developed, they still need to expand their coverage, such as for the Nepali language. In this paper, we identify the eight most common COVID-19 discussion topics among the Twitter community using the Nepali language, set up an online platform to automatically gather Nepali tweets containing the COVID-19-related keywords, classify the tweets into the eight topics, and visualize the results across the period in a web-based dashboard. We compare the performance of two state-of-the-art multi-lingual language models for Nepali tweet classification, one generic (mBERT) and the other Nepali language family-specific model (MuRIL). Our results show that the models' relative performance depends on the data size, with MuRIL doing better for a larger dataset. The annotated data, models, and the web-based dashboard are open-sourced at https://github.com/naamiinepal/covid-tweet-classification.