 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Unbiased Policy Evaluation and Linear Function Approximation
Oct 13, 2022We provide performance guarantees for a variant of simulation-based policy iteration for controlling Markov decision processes that involves the use of stochastic approximation algorithms along with state-of-the-art techniques that are useful for very large MDPs, including lookahead, function approximation, and gradient descent. Specifically, we analyze two algorithms; the first algorithm involves a least squares approach where a new set of weights associated with feature vectors is obtained via least squares minimization at each iteration and the second algorithm involves a two-time-scale stochastic approximation algorithm taking several steps of gradient descent towards the least squares solution before obtaining the next iterate using a stochastic approximation algorithm.
MaxWeight With Discounted UCB: A Provably Stable Scheduling Policy for Nonstationary Multi-Server Systems With Unknown Statistics
Sep 02, 2022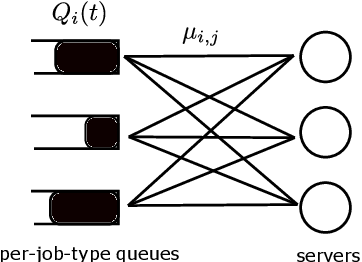
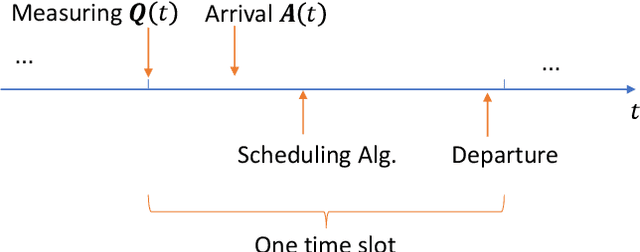
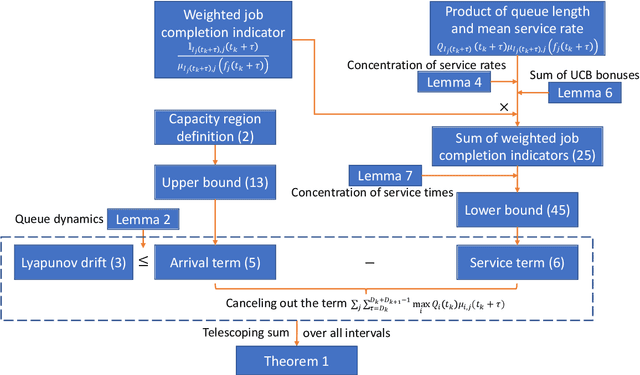
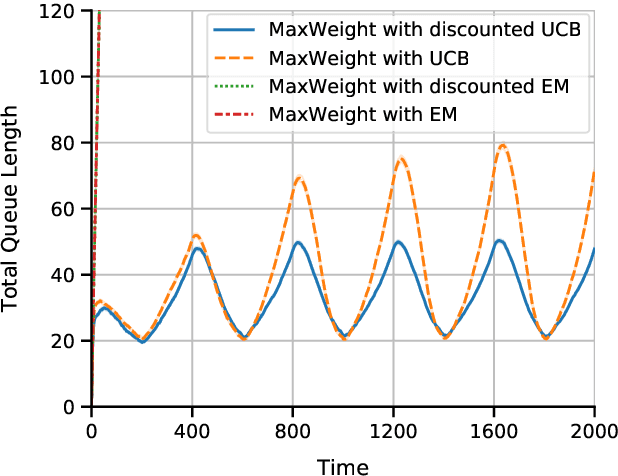
Multi-server queueing systems are widely used models for job scheduling in machine learning, wireless networks, and crowdsourcing. This paper considers a multi-server system with multiple servers and multiple types of jobs. The system maintains a separate queue for each type of jobs. For each time slot, each available server picks a job from a queue and then serves the job until it is complete. The arrival rates of the queues and the mean service times are unknown and even nonstationary. We propose the MaxWeight with discounted upper confidence bound (UCB) algorithm, which simultaneously learns the statistics and schedules jobs to servers. We prove that the proposed algorithm can stabilize the queues when the arrival rates are strictly within the service capacity region. Specifically, we prove that the queue lengths are bounded in the mean under the assumption that the mean service times change relatively slowly over time and the arrival rates are bounded away from the capacity region by a constant whose value depends on the discount factor used in the discounted UCB. Simulation results confirm that the proposed algorithm can stabilize the queues and that it outperforms MaxWeight with empirical mean and MaxWeight with discounted empirical mean. The proposed algorithm is also better than MaxWeight with UCB in the nonstationary setting.
Finite-Time Analysis of Entropy-Regularized Neural Natural Actor-Critic Algorithm
Jun 02, 2022
Natural actor-critic (NAC) and its variants, equipped with the representation power of neural networks, have demonstrated impressive empirical success in solving Markov decision problems with large state spaces. In this paper, we present a finite-time analysis of NAC with neural network approximation, and identify the roles of neural networks, regularization and optimization techniques (e.g., gradient clipping and averaging) to achieve provably good performance in terms of sample complexity, iteration complexity and overparametrization bounds for the actor and the critic. In particular, we prove that (i) entropy regularization and averaging ensure stability by providing sufficient exploration to avoid near-deterministic and strictly suboptimal policies and (ii) regularization leads to sharp sample complexity and network width bounds in the regularized MDPs, yielding a favorable bias-variance tradeoff in policy optimization. In the process, we identify the importance of uniform approximation power of the actor neural network to achieve global optimality in policy optimization due to distributional shift.
Minimax Regret for Cascading Bandits
Mar 23, 2022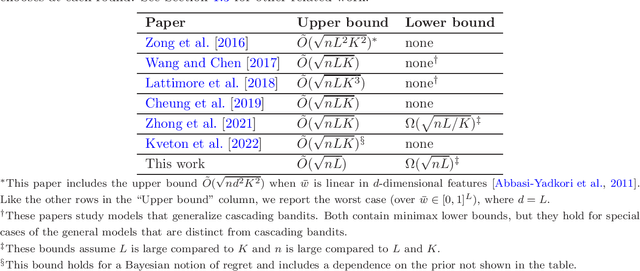
Cascading bandits model the task of learning to rank $K$ out of $L$ items over $n$ rounds of partial feedback. For this model, the minimax (i.e., gap-free) regret is poorly understood; in particular, the best known lower and upper bounds are $\Omega(\sqrt{nL/K})$ and $\tilde{O}(\sqrt{nLK})$, respectively. We improve the lower bound to $\Omega(\sqrt{nL})$ and show CascadeKL-UCB (which ranks items by their KL-UCB indices) attains it up to log terms. Surprisingly, we also show CascadeUCB1 (which ranks via UCB1) can suffer suboptimal $\Omega(\sqrt{nLK})$ regret. This sharply contrasts with standard $L$-armed bandits, where the corresponding algorithms both achieve the minimax regret $\sqrt{nL}$ (up to log terms), and the main advantage of KL-UCB is only to improve constants in the gap-dependent bounds. In essence, this contrast occurs because Pinsker's inequality is tight for hard problems in the $L$-armed case but loose (by a factor of $K$) in the cascading case.
Robust Multi-Agent Bandits Over Undirected Graphs
Feb 28, 2022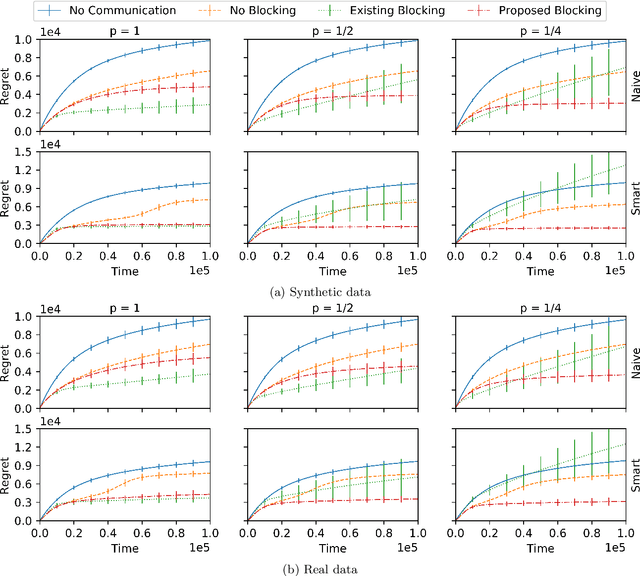
We consider a multi-agent multi-armed bandit setting in which $n$ honest agents collaborate over a network to minimize regret but $m$ malicious agents can disrupt learning arbitrarily. Assuming the network is the complete graph, existing algorithms incur $O( (m + K/n) \log (T) / \Delta )$ regret in this setting, where $K$ is the number of arms and $\Delta$ is the arm gap. For $m \ll K$, this improves over the single-agent baseline regret of $O(K\log(T)/\Delta)$. In this work, we show the situation is murkier beyond the case of a complete graph. In particular, we prove that if the state-of-the-art algorithm is used on the undirected line graph, honest agents can suffer (nearly) linear regret until time is doubly exponential in $K$ and $n$. In light of this negative result, we propose a new algorithm for which the $i$-th agent has regret $O( ( d_{\text{mal}}(i) + K/n) \log(T)/\Delta)$ on any connected and undirected graph, where $d_{\text{mal}}(i)$ is the number of $i$'s neighbors who are malicious. Thus, we generalize existing regret bounds beyond the complete graph (where $d_{\text{mal}}(i) = m$), and show the effect of malicious agents is entirely local (in the sense that only the $d_{\text{mal}}(i)$ malicious agents directly connected to $i$ affect its long-term regret).
Learning to Control Partially Observed Systems with Finite Memory
Feb 22, 2022We consider the reinforcement learning problem for partially observed Markov decision processes (POMDPs) with large or even countably infinite state spaces, where the controller has access to only noisy observations of the underlying controlled Markov chain. We consider a natural actor-critic method that employs a finite internal memory for policy parameterization, and a multi-step temporal difference learning algorithm for policy evaluation. We establish, to the best of our knowledge, the first non-asymptotic global convergence of actor-critic methods for partially observed systems under function approximation. In particular, in addition to the function approximation and statistical errors that also arise in MDPs, we explicitly characterize the error due to the use of finite-state controllers. This additional error is stated in terms of the total variation distance between the traditional belief state in POMDPs and the posterior distribution of the hidden state when using a finite-state controller. Further, we show that this error can be made small in the case of sliding-block controllers by using larger block sizes.
The Role of Lookahead and Approximate Policy Evaluation in Policy Iteration with Linear Value Function Approximation
Sep 28, 2021
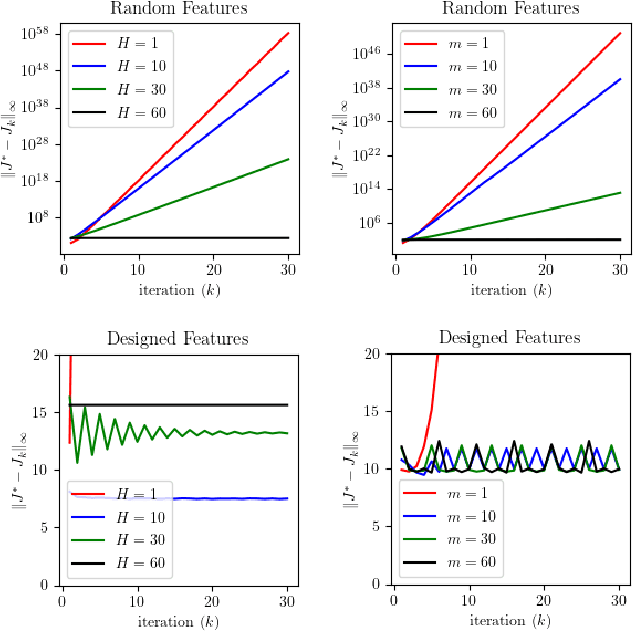
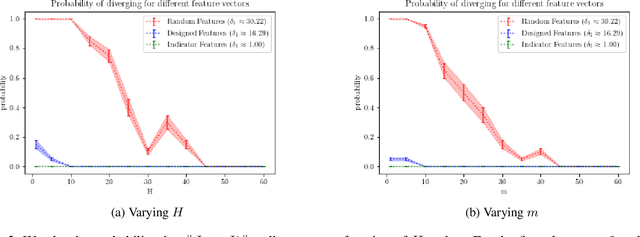
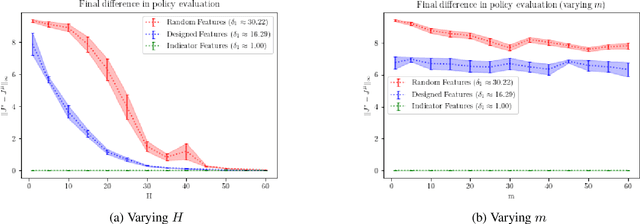
When the sizes of the state and action spaces are large, solving MDPs can be computationally prohibitive even if the probability transition matrix is known. So in practice, a number of techniques are used to approximately solve the dynamic programming problem, including lookahead, approximate policy evaluation using an m-step return, and function approximation. In a recent paper, (Efroni et al. 2019) studied the impact of lookahead on the convergence rate of approximate dynamic programming. In this paper, we show that these convergence results change dramatically when function approximation is used in conjunction with lookout and approximate policy evaluation using an m-step return. Specifically, we show that when linear function approximation is used to represent the value function, a certain minimum amount of lookahead and multi-step return is needed for the algorithm to even converge. And when this condition is met, we characterize the finite-time performance of policies obtained using such approximate policy iteration. Our results are presented for two different procedures to compute the function approximation: linear least-squares regression and gradient descent.
Improved Algorithms for Misspecified Linear Markov Decision Processes
Sep 12, 2021
For the misspecified linear Markov decision process (MLMDP) model of Jin et al. [2020], we propose an algorithm with three desirable properties. (P1) Its regret after $K$ episodes scales as $K \max \{ \varepsilon_{\text{mis}}, \varepsilon_{\text{tol}} \}$, where $\varepsilon_{\text{mis}}$ is the degree of misspecification and $\varepsilon_{\text{tol}}$ is a user-specified error tolerance. (P2) Its space and per-episode time complexities remain bounded as $K \rightarrow \infty$. (P3) It does not require $\varepsilon_{\text{mis}}$ as input. To our knowledge, this is the first algorithm satisfying all three properties. For concrete choices of $\varepsilon_{\text{tol}}$, we also improve existing regret bounds (up to log factors) while achieving either (P2) or (P3) (existing algorithms satisfy neither). At a high level, our algorithm generalizes (to MLMDPs) and refines the Sup-Lin-UCB algorithm, which Takemura et al. [2021] recently showed satisfies (P3) in the contextual bandit setting.
Linear Convergence of Entropy-Regularized Natural Policy Gradient with Linear Function Approximation
Jun 08, 2021Natural policy gradient (NPG) methods with function approximation achieve impressive empirical success in reinforcement learning problems with large state-action spaces. However, theoretical understanding of their convergence behaviors remains limited in the function approximation setting. In this paper, we perform a finite-time analysis of NPG with linear function approximation and softmax parameterization, and prove for the first time that widely used entropy regularization method, which encourages exploration, leads to linear convergence rate. We adopt a Lyapunov drift analysis to prove the convergence results and explain the effectiveness of entropy regularization in improving the convergence rates.
Regret Bounds for Stochastic Shortest Path Problems with Linear Function Approximation
May 04, 2021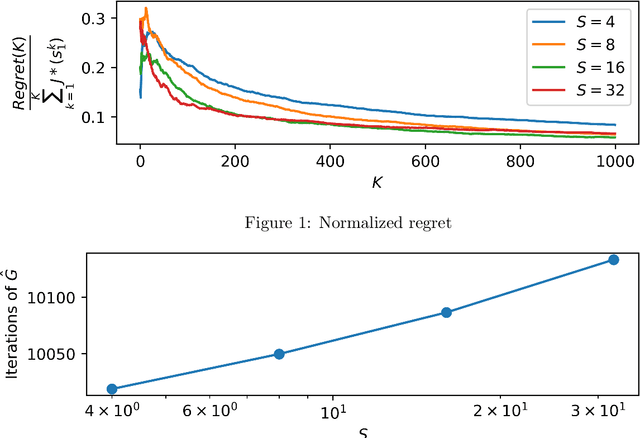
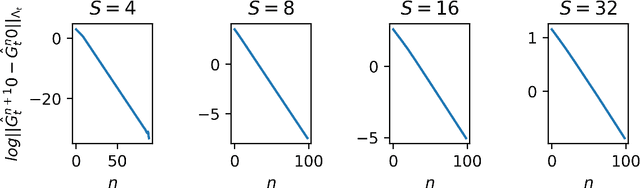
We propose two algorithms for episodic stochastic shortest path problems with linear function approximation. The first is computationally expensive but provably obtains $\tilde{O} (\sqrt{B_\star^3 d^3 K/c_{min}} )$ regret, where $B_\star$ is a (known) upper bound on the optimal cost-to-go function, $d$ is the feature dimension, $K$ is the number of episodes, and $c_{min}$ is the minimal cost of non-goal state-action pairs (assumed to be positive). The second is computationally efficient in practice, and we conjecture that it obtains the same regret bound. Both algorithms are based on an optimistic least-squares version of value iteration analogous to the finite-horizon backward induction approach from Jin et al. 2020. To the best of our knowledge, these are the first regret bounds for stochastic shortest path that are independent of the size of the state and action spaces.