 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Testing of Autonomous Driving Systems: A Survey
Aug 27, 2025Autonomous driving systems (ADS) have been an active area of research, with the potential to deliver significant benefits to society. However, before large-scale deployment on public roads, extensive testing is necessary to validate their functionality and safety under diverse driving conditions. Therefore, different testing approaches are required, and achieving effective and efficient testing of ADS remains an open challenge. Recently, generative AI has emerged as a powerful tool across many domains, and it is increasingly being applied to ADS testing due to its ability to interpret context, reason about complex tasks, and generate diverse outputs. To gain a deeper understanding of its role in ADS testing, we systematically analyzed 91 relevant studies and synthesized their findings into six major application categories, primarily centered on scenario-based testing of ADS. We also reviewed their effectiveness and compiled a wide range of datasets, simulators, ADS, metrics, and benchmarks used for evaluation, while identifying 27 limitations. This survey provides an overview and practical insights into the use of generative AI for testing ADS, highlights existing challenges, and outlines directions for future research in this rapidly evolving field.
Exploring ML testing in practice -- Lessons learned from an interactive rapid review with Axis Communications
Mar 30, 2022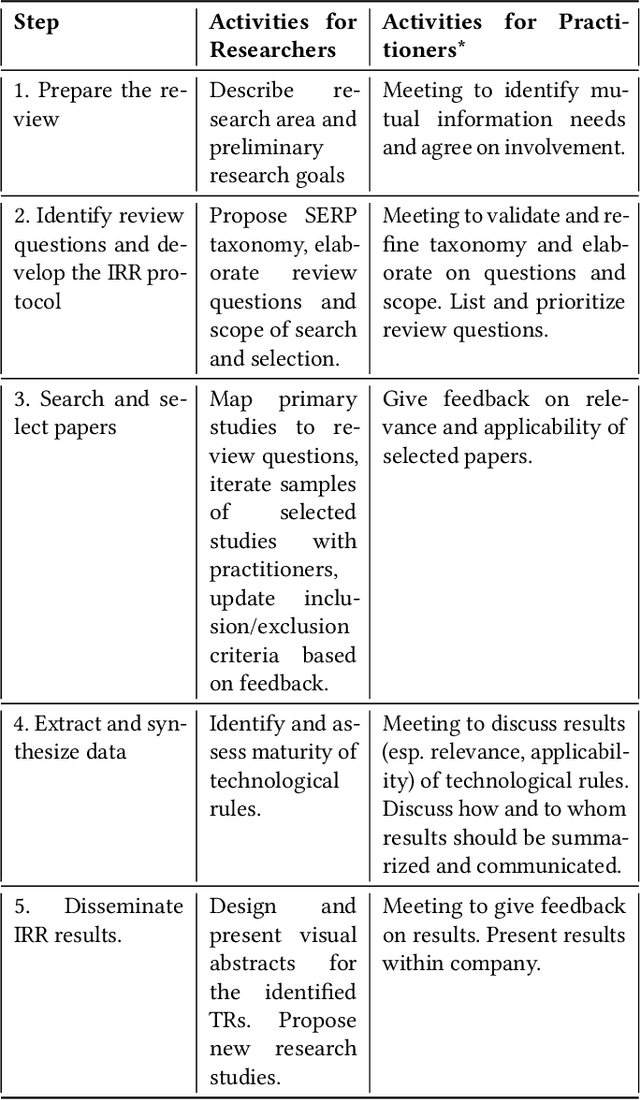
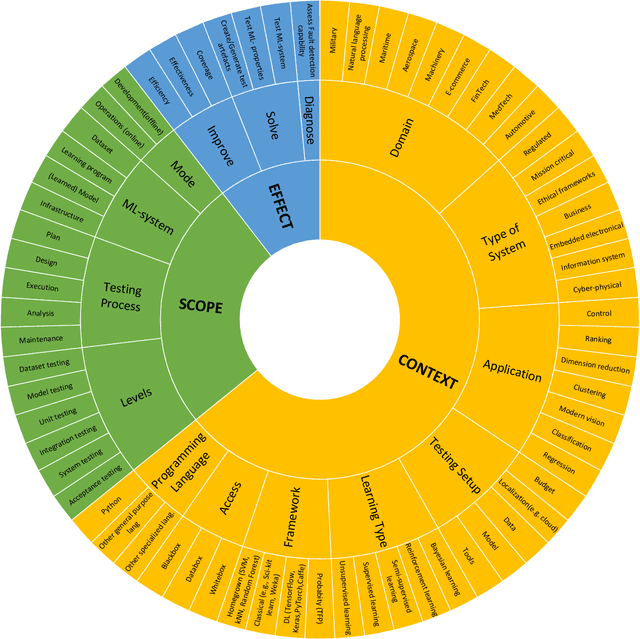
There is a growing interest in industry and academia in machine learning (ML) testing. We believe that industry and academia need to learn together to produce rigorous and relevant knowledge. In this study, we initiate a collaboration between stakeholders from one case company, one research institute, and one university. To establish a common view of the problem domain, we applied an interactive rapid review of the state of the art. Four researchers from Lund University and RISE Research Institutes and four practitioners from Axis Communications reviewed a set of 180 primary studies on ML testing. We developed a taxonomy for the communication around ML testing challenges and results and identified a list of 12 review questions relevant for Axis Communications. The three most important questions (data testing, metrics for assessment, and test generation) were mapped to the literature, and an in-depth analysis of the 35 primary studies matching the most important question (data testing) was made. A final set of the five best matches were analysed and we reflect on the criteria for applicability and relevance for the industry. The taxonomies are helpful for communication but not final. Furthermore, there was no perfect match to the case company's investigated review question (data testing). However, we extracted relevant approaches from the five studies on a conceptual level to support later context-specific improvements. We found the interactive rapid review approach useful for triggering and aligning communication between the different stakeholders.