 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiNR: Model Based Neural Retrieval on GPUs at LinkedIn
Jul 18, 2024



This paper introduces LiNR, LinkedIn's large-scale, GPU-based retrieval system. LiNR supports a billion-sized index on GPU models. We discuss our experiences and challenges in creating scalable, differentiable search indexes using TensorFlow and PyTorch at production scale. In LiNR, both items and model weights are integrated into the model binary. Viewing index construction as a form of model training, we describe scaling our system for large indexes, incorporating full scans and efficient filtering. A key focus is on enabling attribute-based pre-filtering for exhaustive GPU searches, addressing the common challenge of post-filtering in KNN searches that often reduces system quality. We further provide multi-embedding retrieval algorithms and strategies for tackling cold start issues in retrieval. Our advancements in supporting larger indexes through quantization are also discussed. We believe LiNR represents one of the industry's first Live-updated model-based retrieval indexes. Applied to out-of-network post recommendations on LinkedIn Feed, LiNR has contributed to a 3% relative increase in professional daily active users. We envisage LiNR as a step towards integrating retrieval and ranking into a single GPU model, simplifying complex infrastructures and enabling end-to-end optimization of the entire differentiable infrastructure through gradient descent.
BERT for Large-scale Video Segment Classification with Test-time Augmentation
Dec 02, 2019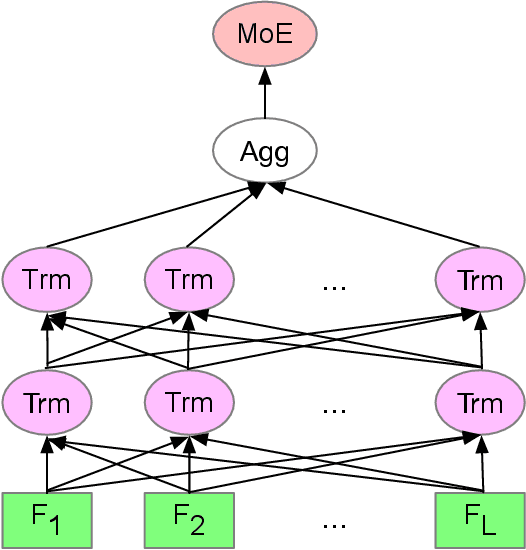
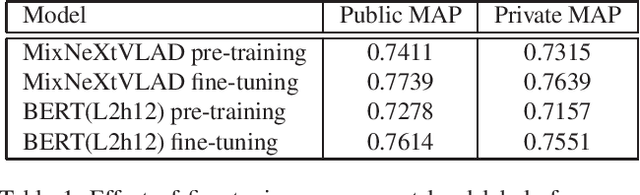
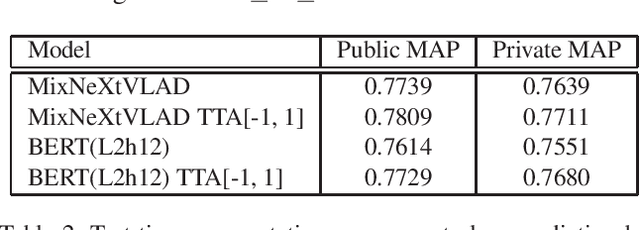
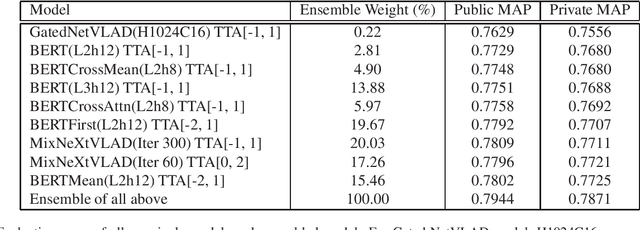
This paper presents our approach to the third YouTube-8M video understanding competition that challenges par-ticipants to localize video-level labels at scale to the pre-cise time in the video where the label actually occurs. Ourmodel is an ensemble of frame-level models such as GatedNetVLAD and NeXtVLAD and various BERT models withtest-time augmentation. We explore multiple ways to ag-gregate BERT outputs as video representation and variousways to combine visual and audio information. We proposetest-time augmentation as shifting video frames to one leftor right unit, which adds variety to the predictions and em-pirically shows improvement in evaluation metrics. We firstpre-train the model on the 4M training video-level data, andthen fine-tune the model on 237K annotated video segment-level data. We achieve MAP@100K 0.7871 on private test-ing video segment data, which is ranked 9th over 283 teams.
* ICCV 2019 YouTube8M workshop