 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE: a Scale-aware Multiple Instance Learning Method for Multicenter STAS Lung Cancer Histopathology Diagnosis
Mar 18, 2025Spread through air spaces (STAS) represents a newly identified aggressive pattern in lung cancer, which is known to be associated with adverse prognostic factors and complex pathological features. Pathologists currently rely on time consuming manual assessments, which are highly subjective and prone to variation. This highlights the urgent need for automated and precise diag nostic solutions. 2,970 lung cancer tissue slides are comprised from multiple centers, re-diagnosed them, and constructed and publicly released three lung cancer STAS datasets: STAS CSU (hospital), STAS TCGA, and STAS CPTAC. All STAS datasets provide corresponding pathological feature diagnoses and related clinical data. To address the bias, sparse and heterogeneous nature of STAS, we propose an scale-aware multiple instance learning(SMILE) method for STAS diagnosis of lung cancer. By introducing a scale-adaptive attention mechanism, the SMILE can adaptively adjust high attention instances, reducing over-reliance on local regions and promoting consistent detection of STAS lesions. Extensive experiments show that SMILE achieved competitive diagnostic results on STAS CSU, diagnosing 251 and 319 STAS samples in CPTAC andTCGA,respectively, surpassing clinical average AUC. The 11 open baseline results are the first to be established for STAS research, laying the foundation for the future expansion, interpretability, and clinical integration of computational pathology technologies. The datasets and code are available at https://anonymous.4open.science/r/IJCAI25-1DA1.
Multimodal Graph Neural Network for Recommendation with Dynamic De-redundancy and Modality-Guided Feature De-noisy
Nov 03, 2024



Graph neural networks (GNNs) have become crucial in multimodal recommendation tasks because of their powerful ability to capture complex relationships between neighboring nodes. However, increasing the number of propagation layers in GNNs can lead to feature redundancy, which may negatively impact the overall recommendation performance. In addition, the existing recommendation task method directly maps the preprocessed multimodal features to the low-dimensional space, which will bring the noise unrelated to user preference, thus affecting the representation ability of the model. To tackle the aforementioned challenges, we propose Multimodal Graph Neural Network for Recommendation (MGNM) with Dynamic De-redundancy and Modality-Guided Feature De-noisy, which is divided into local and global interaction. Initially, in the local interaction process,we integrate a dynamic de-redundancy (DDR) loss function which is achieved by utilizing the product of the feature coefficient matrix and the feature matrix as a penalization factor. It reduces the feature redundancy effects of multimodal and behavioral features caused by the stacking of multiple GNN layers. Subsequently, in the global interaction process, we developed modality-guided global feature purifiers for each modality to alleviate the impact of modality noise. It is a two-fold guiding mechanism eliminating modality features that are irrelevant to user preferences and captures complex relationships within the modality. Experimental results demonstrate that MGNM achieves superior performance on multimodal information denoising and removal of redundant information compared to the state-of-the-art methods.
Artificial Text Detection with Multiple Training Strategies
Dec 10, 2022As the deep learning rapidly promote, the artificial texts created by generative models are commonly used in news and social media. However, such models can be abused to generate product reviews, fake news, and even fake political content. The paper proposes a solution for the Russian Artificial Text Detection in the Dialogue shared task 2022 (RuATD 2022) to distinguish which model within the list is used to generate this text. We introduce the DeBERTa pre-trained language model with multiple training strategies for this shared task. Extensive experiments conducted on the RuATD dataset validate the effectiveness of our proposed method. Moreover, our submission ranked second place in the evaluation phase for RuATD 2022 (Multi-Class).
* Accepted by Dialogue-2022 Conference. 7 pages, 2 figures, 2 tables
Prompt-based Pre-trained Model for Personality and Interpersonal Reactivity Prediction
Mar 23, 2022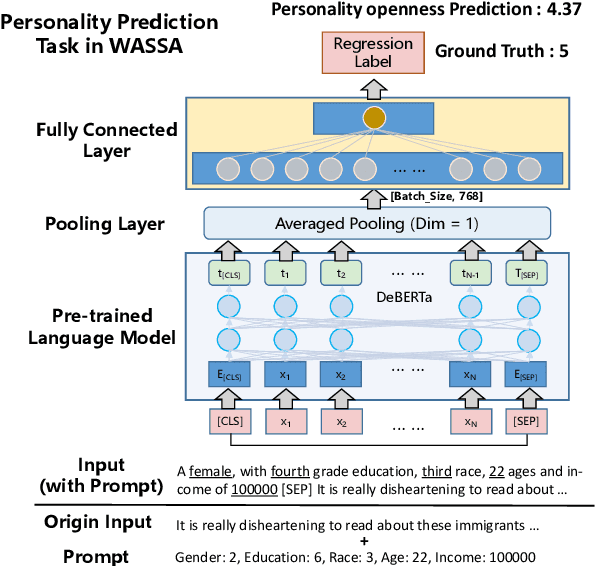
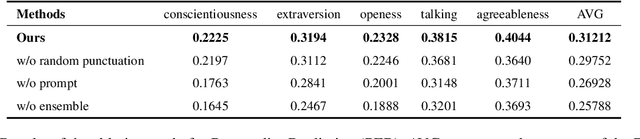
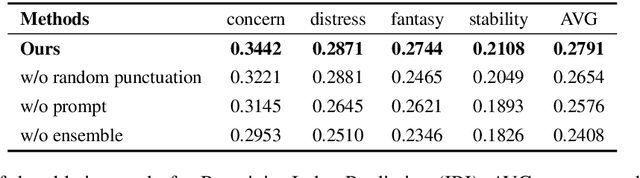

This paper describes the LingJing team's method to the Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA) 2022 shared task on Personality Prediction (PER) and Reactivity Index Prediction (IRI). In this paper, we adopt the prompt-based method with the pre-trained language model to accomplish these tasks. Specifically, the prompt is designed to provide the extra knowledge for enhancing the pre-trained model. Data augmentation and model ensemble are adopted for obtaining better results. Extensive experiments are performed, which shows the effectiveness of the proposed method. On the final submission, our system achieves a Pearson Correlation Coefficient of 0.2301 and 0.2546 on Track 3 and Track 4 respectively. We ranked Top-1 on both sub-tasks.