 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKronecker-Structured Nonparametric Spatiotemporal Point Processes
Mar 24, 2026Events in spatiotemporal domains arise in numerous real-world applications, where uncovering event relationships and enabling accurate prediction are central challenges. Classical Poisson and Hawkes processes rely on restrictive parametric assumptions that limit their ability to capture complex interaction patterns, while recent neural point process models increase representational capacity but integrate event information in a black-box manner, hindering interpretable relationship discovery. To address these limitations, we propose a Kronecker-Structured Nonparametric Spatiotemporal Point Process (KSTPP) that enables transparent event-wise relationship discovery while retaining high modeling flexibility. We model the background intensity with a spatial Gaussian process (GP) and the influence kernel as a spatiotemporal GP, allowing rich interaction patterns including excitation, inhibition, neutrality, and time-varying effects. To enable scalable training and prediction, we adopt separable product kernels and represent the GPs on structured grids, inducing Kronecker-structured covariance matrices. Exploiting Kronecker algebra substantially reduces computational cost and allows the model to scale to large event collections. In addition, we develop a tensor-product Gauss-Legendre quadrature scheme to efficiently evaluate intractable likelihood integrals. Extensive experiments demonstrate the effectiveness of our framework.
Contrastive Weight Regularization for Large Minibatch SGD
Nov 17, 2020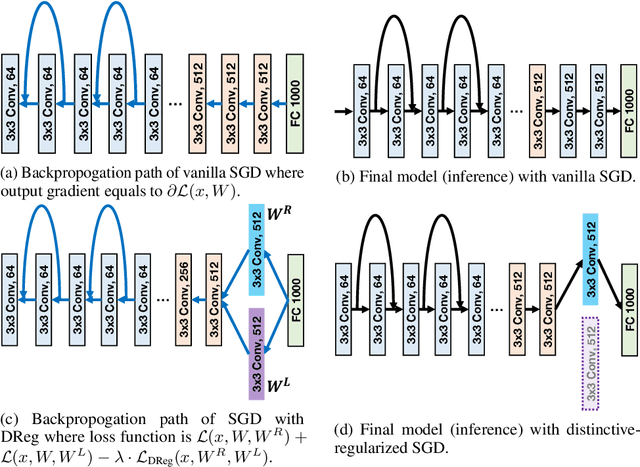
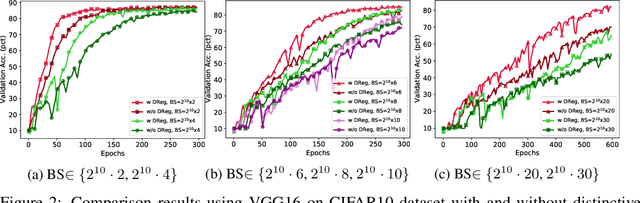
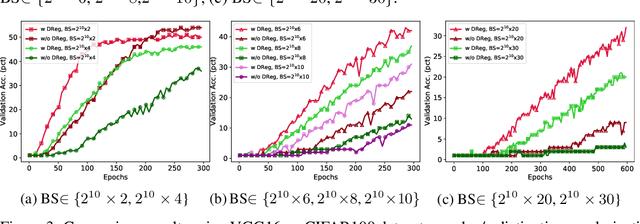
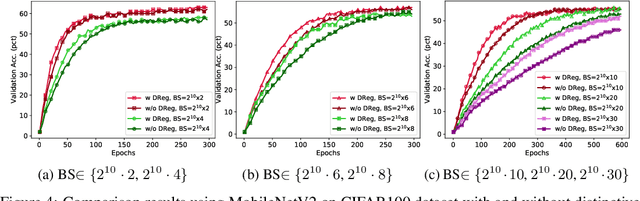
The minibatch stochastic gradient descent method (SGD) is widely applied in deep learning due to its efficiency and scalability that enable training deep networks with a large volume of data. Particularly in the distributed setting, SGD is usually applied with large batch size. However, as opposed to small-batch SGD, neural network models trained with large-batch SGD can hardly generalize well, i.e., the validation accuracy is low. In this work, we introduce a novel regularization technique, namely distinctive regularization (DReg), which replicates a certain layer of the deep network and encourages the parameters of both layers to be diverse. The DReg technique introduces very little computation overhead. Moreover, we empirically show that optimizing the neural network with DReg using large-batch SGD achieves a significant boost in the convergence and improved generalization performance. We also demonstrate that DReg can boost the convergence of large-batch SGD with momentum. We believe that DReg can be used as a simple regularization trick to accelerate large-batch training in deep learning.