 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Continual Fine-Tuning: A Survey
Apr 18, 2025


The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.
LAGA: A Learning Adaptive Genetic Algorithm for Earth Electromagnetic Satellite Scheduling Problem
Jan 07, 2023Earth electromagnetic exploration satellites are widely used in many fields due to their wide detection range and high detection sensitivity. The complex environment and the proliferating number of satellites make management a primary issue. We propose a learning adaptive genetic algorithm (LAGA) for the earth electromagnetic satellite scheduling problem (EESSP). Control parameters are vital for evolutionary algorithms, and their sensitivity to the problem makes tuning parameters usually require a lot of effort. In the LAGA, we use a GRU artificial neural network model to control the parameters of variation operators. The GRU model can utilize online information to achieve adaptive adjustment of the parameters during population search. Moreover, a policy gradient-based reinforcement learning method is designed to update the GRU network parameters. By using an adaptive evolution mechanism in the algorithm, the LAGA can autonomously select crossover operators. Furthermore, a heuristic initialization method, an elite strategy, and a local search method are adopted in the LAGA to enhance the overall performance. The proposed algorithm can obtain a more optimal solution on the EESSP through sufficient experimental validations compared to the state-of-the-art algorithms.
A Tent Lévy Flying Sparrow Search Algorithm for Feature Selection: A COVID-19 Case Study
Sep 20, 2022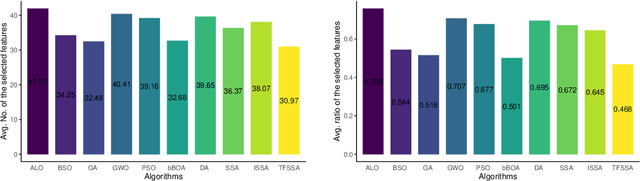
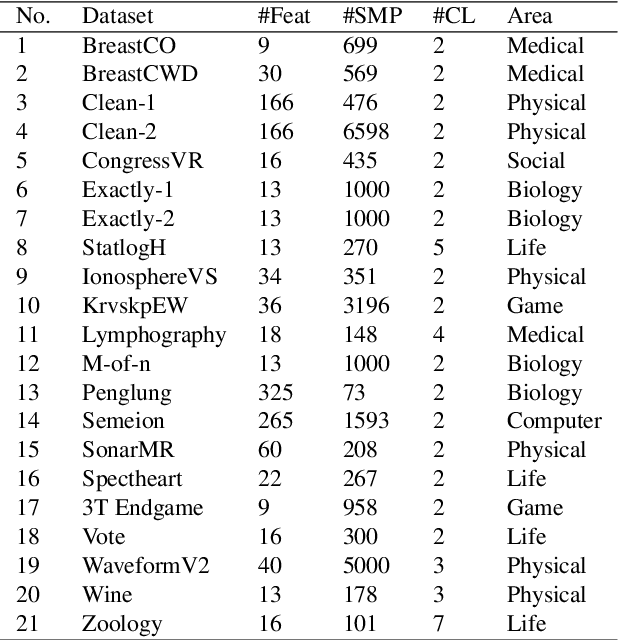

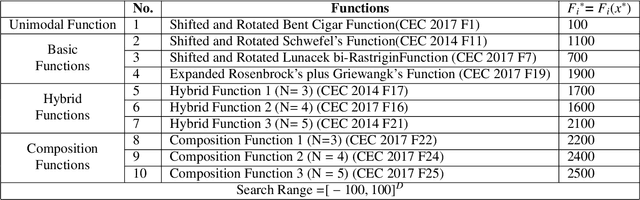
The "Curse of Dimensionality" induced by the rapid development of information science, might have a negative impact when dealing with big datasets. In this paper, we propose a variant of the sparrow search algorithm (SSA), called Tent L\'evy flying sparrow search algorithm (TFSSA), and use it to select the best subset of features in the packing pattern for classification purposes. SSA is a recently proposed algorithm that has not been systematically applied to feature selection problems. After verification by the CEC2020 benchmark function, TFSSA is used to select the best feature combination to maximize classification accuracy and minimize the number of selected features. The proposed TFSSA is compared with nine algorithms in the literature. Nine evaluation metrics are used to properly evaluate and compare the performance of these algorithms on twenty-one datasets from the UCI repository. Furthermore, the approach is applied to the coronavirus disease (COVID-19) dataset, yielding the best average classification accuracy and the average number of feature selections, respectively, of 93.47% and 2.1. Experimental results confirm the advantages of the proposed algorithm in improving classification accuracy and reducing the number of selected features compared to other wrapper-based algorithms.