 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023



Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.
Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review
May 09, 2023



Change detection is an essential and widely utilized task in remote sensing that aims to detect and analyze changes occurring in the same geographical area over time, which has broad applications in urban development, agricultural surveys, and land cover monitoring. Detecting changes in remote sensing images is a complex challenge due to various factors, including variations in image quality, noise, registration errors, illumination changes, complex landscapes, and spatial heterogeneity. In recent years, deep learning has emerged as a powerful tool for feature extraction and addressing these challenges. Its versatility has resulted in its widespread adoption for numerous image-processing tasks. This paper presents a comprehensive survey of significant advancements in change detection for remote sensing images over the past decade. We first introduce some preliminary knowledge for the change detection task, such as problem definition, datasets, evaluation metrics, and transformer basics, as well as provide a detailed taxonomy of existing algorithms from three different perspectives: algorithm granularity, supervision modes, and learning frameworks in the methodology section. This survey enables readers to gain systematic knowledge of change detection tasks from various angles. We then summarize the state-of-the-art performance on several dominant change detection datasets, providing insights into the strengths and limitations of existing algorithms. Based on our survey, some future research directions for change detection in remote sensing are well identified. This survey paper will shed some light on the community and inspire further research efforts in the change detection task.
DNeRV: Modeling Inherent Dynamics via Difference Neural Representation for Videos
Apr 13, 2023Existing implicit neural representation (INR) methods do not fully exploit spatiotemporal redundancies in videos. Index-based INRs ignore the content-specific spatial features and hybrid INRs ignore the contextual dependency on adjacent frames, leading to poor modeling capability for scenes with large motion or dynamics. We analyze this limitation from the perspective of function fitting and reveal the importance of frame difference. To use explicit motion information, we propose Difference Neural Representation for Videos (DNeRV), which consists of two streams for content and frame difference. We also introduce a collaborative content unit for effective feature fusion. We test DNeRV for video compression, inpainting, and interpolation. DNeRV achieves competitive results against the state-of-the-art neural compression approaches and outperforms existing implicit methods on downstream inpainting and interpolation for $960 \times 1920$ videos.
Cooperative Coevolution for Non-Separable Large-Scale Black-Box Optimization: Convergence Analyses and Distributed Accelerations
Apr 11, 2023Given the ubiquity of non-separable optimization problems in real worlds, in this paper we analyze and extend the large-scale version of the well-known cooperative coevolution (CC), a divide-and-conquer optimization framework, on non-separable functions. First, we reveal empirical reasons of why decomposition-based methods are preferred or not in practice on some non-separable large-scale problems, which have not been clearly pointed out in many previous CC papers. Then, we formalize CC to a continuous game model via simplification, but without losing its essential property. Different from previous evolutionary game theory for CC, our new model provides a much simpler but useful viewpoint to analyze its convergence, since only the pure Nash equilibrium concept is needed and more general fitness landscapes can be explicitly considered. Based on convergence analyses, we propose a hierarchical decomposition strategy for better generalization, as for any decomposition there is a risk of getting trapped into a suboptimal Nash equilibrium. Finally, we use powerful distributed computing to accelerate it under the multi-level learning framework, which combines the fine-tuning ability from decomposition with the invariance property of CMA-ES. Experiments on a set of high-dimensional functions validate both its search performance and scalability (w.r.t. CPU cores) on a clustering computing platform with 400 CPU cores.
Divide and Conquer: Answering Questions with Object Factorization and Compositional Reasoning
Mar 18, 2023Humans have the innate capability to answer diverse questions, which is rooted in the natural ability to correlate different concepts based on their semantic relationships and decompose difficult problems into sub-tasks. On the contrary, existing visual reasoning methods assume training samples that capture every possible object and reasoning problem, and rely on black-boxed models that commonly exploit statistical priors. They have yet to develop the capability to address novel objects or spurious biases in real-world scenarios, and also fall short of interpreting the rationales behind their decisions. Inspired by humans' reasoning of the visual world, we tackle the aforementioned challenges from a compositional perspective, and propose an integral framework consisting of a principled object factorization method and a novel neural module network. Our factorization method decomposes objects based on their key characteristics, and automatically derives prototypes that represent a wide range of objects. With these prototypes encoding important semantics, the proposed network then correlates objects by measuring their similarity on a common semantic space and makes decisions with a compositional reasoning process. It is capable of answering questions with diverse objects regardless of their availability during training, and overcoming the issues of biased question-answer distributions. In addition to the enhanced generalizability, our framework also provides an interpretable interface for understanding the decision-making process of models. Our code is available at https://github.com/szzexpoi/POEM.
A Survey on Automated Design of Metaheuristic Algorithms
Mar 12, 2023Metaheuristic algorithms have attracted wide attention from academia and industry due to their capability of conducting search independent of problem structures and problem domains. Often, human experts are requested to manually tailor algorithms to fit for solving a targeted problem. The manual tailoring process may be laborious, error-prone, and require intensive specialized knowledge. This gives rise to increasing interests and demands for automated design of metaheuristic algorithms with less human intervention. The automated design could make high-performance algorithms accessible to a much broader range of researchers and practitioners; and by leveraging computing power to fully explore the potential design choices, automated design could reach or even surpass human-level design. This paper presents a broad picture of the formalization, methodologies, challenges, and research trends of automated design of metaheuristic algorithms, by conducting a survey on the common grounds and representative techniques in this field. In the survey, we first present the concept of automated design of metaheuristic algorithms and provide a taxonomy by abstracting the automated design process into four parts, i.e., design space, design strategies, performance evaluation strategies, and targeted problems. Then, we overview the techniques concerning the four parts of the taxonomy and discuss their strengths, weaknesses, challenges, and usability, respectively. Finally, we present research trends in this field.
AutoOptLib: A Library of Automatically Designing Metaheuristic Optimization Algorithms in MATLAB
Mar 12, 2023Metaheuristic algorithms are widely-recognized solvers for challenging optimization problems with multi-modality, discretization, large-scale, multi-objectivity, etc. Automatically designing metaheuristic algorithms leverages today's increasing computing resources to conceive, build up, and verify the design choices of algorithms. It requires much less expertise, labor resources, and time cost than the traditional manual design. Furthermore, by fully exploring the design choices with computing power, automated design is potential to reach or even surpass human-level design, subsequently gaining enhanced performance compared with human problem-solving. These significant advantages have attracted increasing interest and development in the automated design techniques. Open source software is indispensable in response to the increasing interest and development of the techniques. To this end, we have developed a MATLAB library, AutoOptLib, to automatically design metaheuristic algorithms. AutoOptLib, for the first time, provides throughout support to the whole design process, including: 1) plenty of algorithmic components for continuous, discrete, and permutation problems, 2) flexible algorithm representation for evolving diverse algorithm structures, 3) various design objectives and design techniques for different experimentation and application scenarios, and 4) useful experimental tools and graphic user interface (GUI) for practicability and accessibility. In this paper, we first introduce the key features and architecture of the AutoOptLib library. We then illustrate how to use the library by either command or GUI. We further describe additional uses and experimental tools, including parameter importance analysis and benchmark comparison. Finally, we present academic and piratical applications of AutoOptLib, which verifies its efficiency and practicability.
Self-Training Guided Disentangled Adaptation for Cross-Domain Remote Sensing Image Semantic Segmentation
Jan 13, 2023Deep convolutional neural networks (DCNNs) based remote sensing (RS) image semantic segmentation technology has achieved great success used in many real-world applications such as geographic element analysis. However, strong dependency on annotated data of specific scene makes it hard for DCNNs to fit different RS scenes. To solve this problem, recent works gradually focus on cross-domain RS image semantic segmentation task. In this task, different ground sampling distance, remote sensing sensor variation and different geographical landscapes are three main factors causing dramatic domain shift between source and target images. To decrease the negative influence of domain shift, we propose a self-training guided disentangled adaptation network (ST-DASegNet). We first propose source student backbone and target student backbone to respectively extract the source-style and target-style feature for both source and target images. Towards the intermediate output feature maps of each backbone, we adopt adversarial learning for alignment. Then, we propose a domain disentangled module to extract the universal feature and purify the distinct feature of source-style and target-style features. Finally, these two features are fused and served as input of source student decoder and target student decoder to generate final predictions. Based on our proposed domain disentangled module, we further propose exponential moving average (EMA) based cross-domain separated self-training mechanism to ease the instability and disadvantageous effect during adversarial optimization. Extensive experiments and analysis on benchmark RS datasets show that ST-DASegNet outperforms previous methods on cross-domain RS image semantic segmentation task and achieves state-of-the-art (SOTA) results. Our code is available at https://github.com/cv516Buaa/ST-DASegNet.
PyPop7: A Pure-Python Library for Population-Based Black-Box Optimization
Dec 12, 2022In this paper, we present a pure-Python open-source library, called PyPop7, for black-box optimization (BBO). It provides a unified and modular interface for more than 60 versions and variants of different black-box optimization algorithms, particularly population-based optimizers, which can be classified into 12 popular families: Evolution Strategies (ES), Natural Evolution Strategies (NES), Estimation of Distribution Algorithms (EDA), Cross-Entropy Method (CEM), Differential Evolution (DE), Particle Swarm Optimizer (PSO), Cooperative Coevolution (CC), Simulated Annealing (SA), Genetic Algorithms (GA), Evolutionary Programming (EP), Pattern Search (PS), and Random Search (RS). It also provides many examples, interesting tutorials, and full-fledged API documentations. Through this new library, we expect to provide a well-designed platform for benchmarking of optimizers and promote their real-world applications, especially for large-scale BBO. Its source code and documentations are available at https://github.com/Evolutionary-Intelligence/pypop and https://pypop.readthedocs.io/en/latest, respectively.
Look in Different Views: Multi-Scheme Regression Guided Cell Instance Segmentation
Aug 17, 2022
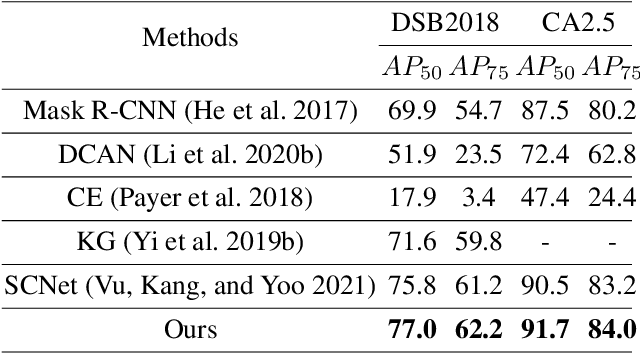
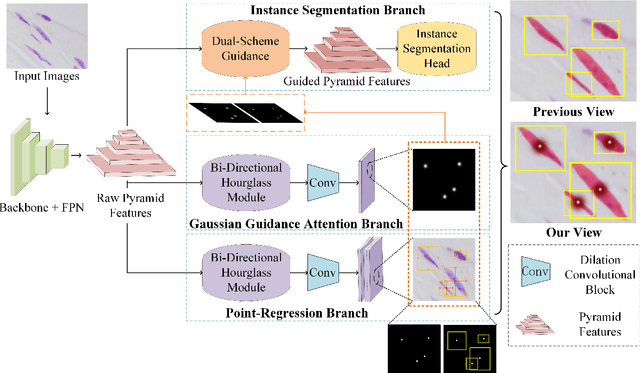
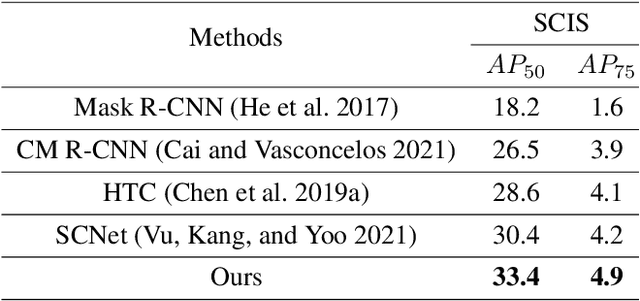
Cell instance segmentation is a new and challenging task aiming at joint detection and segmentation of every cell in an image. Recently, many instance segmentation methods have applied in this task. Despite their great success, there still exists two main weaknesses caused by uncertainty of localizing cell center points. First, densely packed cells can easily be recognized into one cell. Second, elongated cell can easily be recognized into two cells. To overcome these two weaknesses, we propose a novel cell instance segmentation network based on multi-scheme regression guidance. With multi-scheme regression guidance, the network has the ability to look each cell in different views. Specifically, we first propose a gaussian guidance attention mechanism to use gaussian labels for guiding the network's attention. We then propose a point-regression module for assisting the regression of cell center. Finally, we utilize the output of the above two modules to further guide the instance segmentation. With multi-scheme regression guidance, we can take full advantage of the characteristics of different regions, especially the central region of the cell. We conduct extensive experiments on benchmark datasets, DSB2018, CA2.5 and SCIS. The encouraging results show that our network achieves SOTA (state-of-the-art) performance. On the DSB2018 and CA2.5, our network surpasses previous methods by 1.2% (AP50). Particularly on SCIS dataset, our network performs stronger by large margin (3.0% higher AP50). Visualization and analysis further prove that our proposed method is interpretable.