 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and cross-lingual document classification: A meta-learning approach
Jan 27, 2021
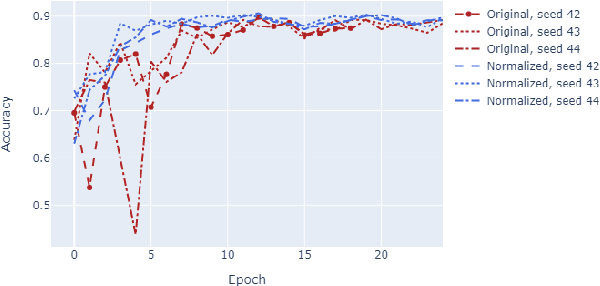
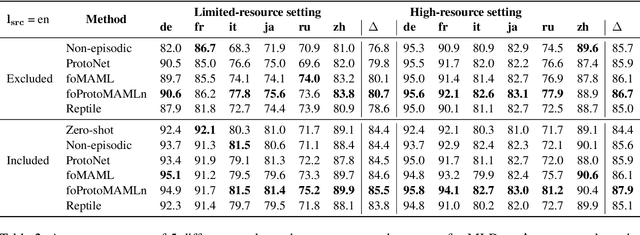
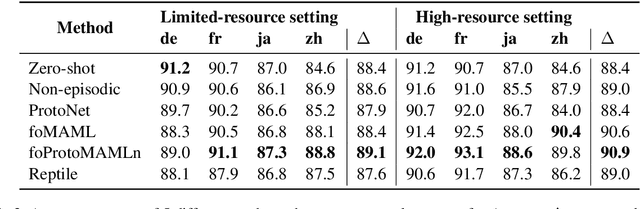
The great majority of languages in the world are considered under-resourced for the successful application of deep learning methods. In this work, we propose a meta-learning approach to document classification in limited-resource setting and demonstrate its effectiveness in two different settings: few-shot, cross-lingual adaptation to previously unseen languages; and multilingual joint training when limited target-language data is available during training. We conduct a systematic comparison of several meta-learning methods, investigate multiple settings in terms of data availability and show that meta-learning thrives in settings with a heterogeneous task distribution. We propose a simple, yet effective adjustment to existing meta-learning methods which allows for better and more stable learning, and set a new state of the art on several languages while performing on-par on others, using only a small amount of labeled data.
Graph-based Modeling of Online Communities for Fake News Detection
Sep 14, 2020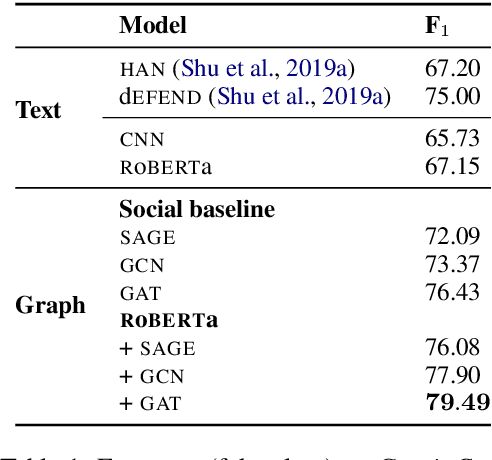
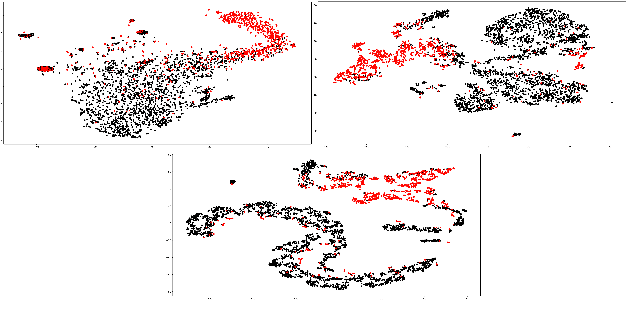
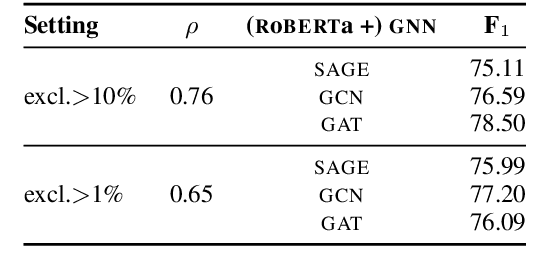
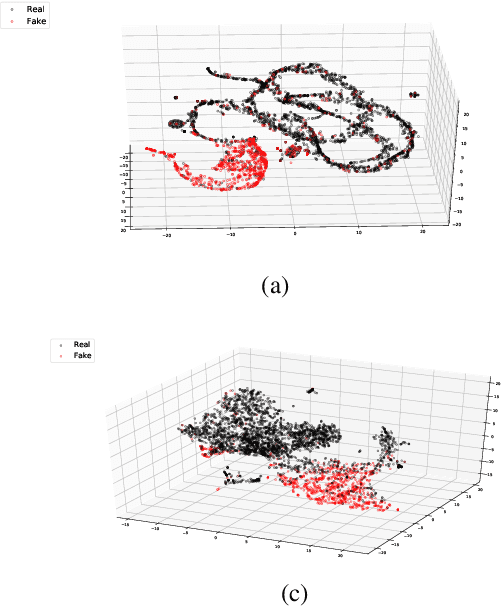
Over the past few years, there has been a substantial effort towards automated detection of fake news on social media platforms. Existing research has modeled the structure, style, content, and patterns in dissemination of online posts, as well as the demographic traits of users who interact with them. However, no attention has been directed towards modeling the properties of online communities that interact with the posts. In this work, we propose a novel social context-aware fake news detection framework, SAFER, based on graph neural networks (GNNs). The proposed framework aggregates information with respect to: 1) the nature of the content disseminated, 2) content-sharing behavior of users, and 3) the social network of those users. We furthermore perform a systematic comparison of several GNN models for this task and introduce novel methods based on relational and hyperbolic GNNs, which have not been previously used for user or community modeling within NLP. We empirically demonstrate that our framework yields significant improvements over existing text-based techniques and achieves state-of-the-art results on fake news datasets from two different domains.
Meta-Learning with Sparse Experience Replay for Lifelong Language Learning
Sep 10, 2020
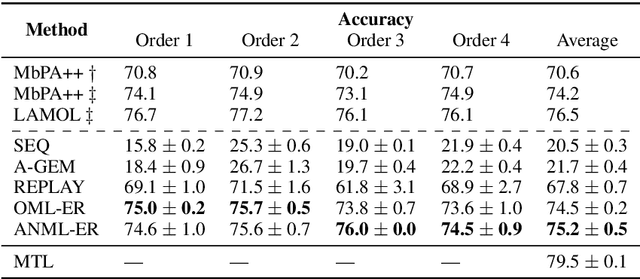
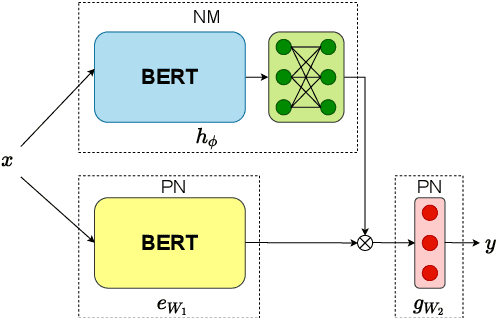
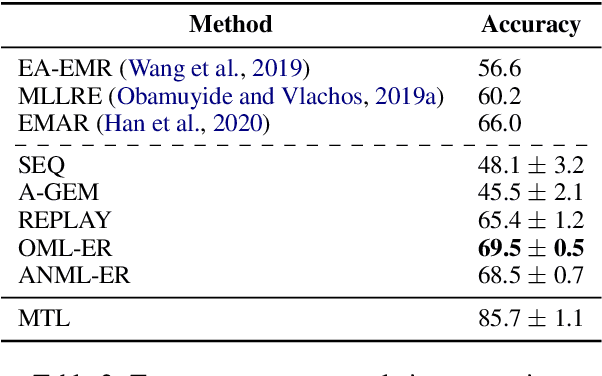
Lifelong learning requires models that can continuously learn from sequential streams of data without suffering catastrophic forgetting due to shifts in data distributions. Deep learning models have thrived in the non-sequential learning paradigm; however, when used to learn a sequence of tasks, they fail to retain past knowledge and learn incrementally. We propose a novel approach to lifelong learning of language tasks based on meta-learning with sparse experience replay that directly optimizes to prevent forgetting. We show that under the realistic setting of performing a single pass on a stream of tasks and without any task identifiers, our method obtains state-of-the-art results on lifelong text classification and relation extraction. We analyze the effectiveness of our approach and further demonstrate its low computational and space complexity.
Joint Modelling of Emotion and Abusive Language Detection
May 28, 2020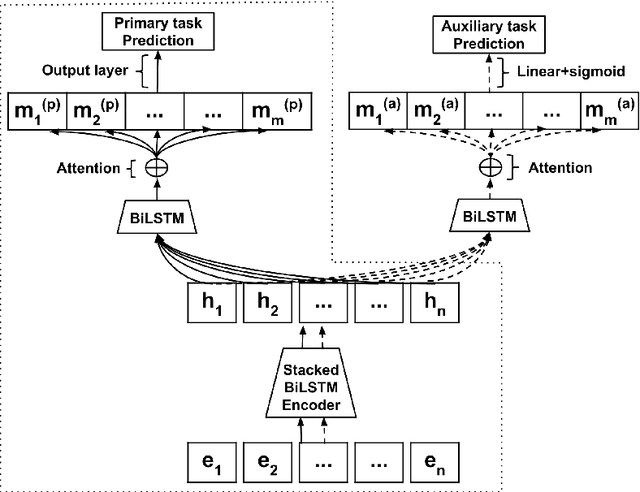
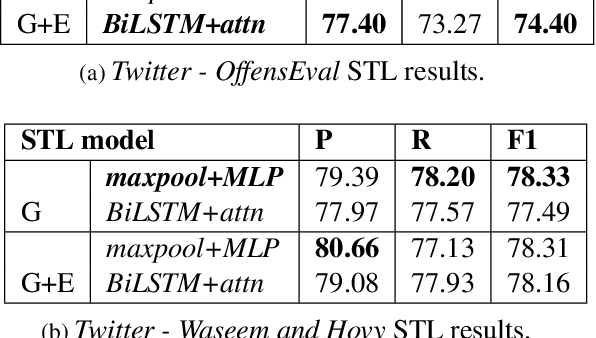
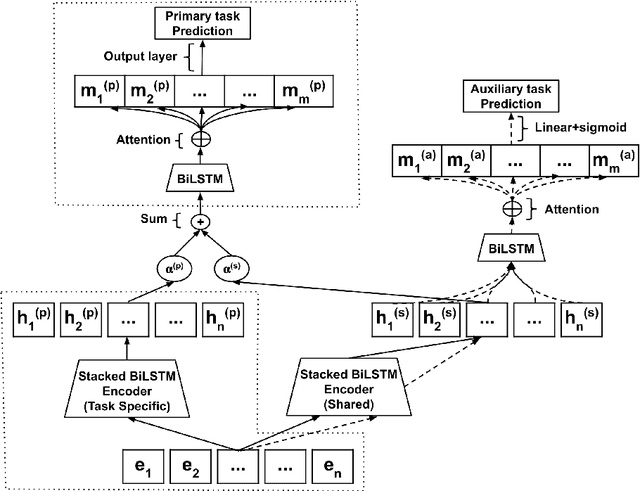
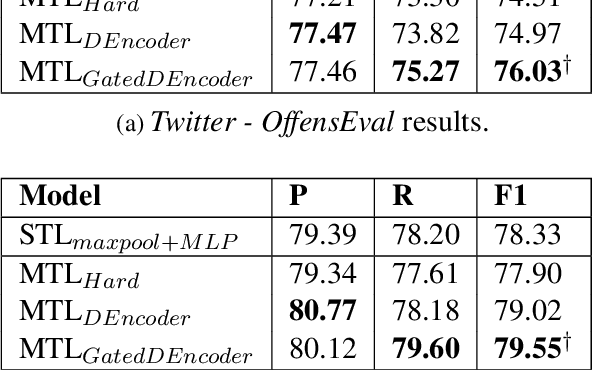
The rise of online communication platforms has been accompanied by some undesirable effects, such as the proliferation of aggressive and abusive behaviour online. Aiming to tackle this problem, the natural language processing (NLP) community has experimented with a range of techniques for abuse detection. While achieving substantial success, these methods have so far only focused on modelling the linguistic properties of the comments and the online communities of users, disregarding the emotional state of the users and how this might affect their language. The latter is, however, inextricably linked to abusive behaviour. In this paper, we present the first joint model of emotion and abusive language detection, experimenting in a multi-task learning framework that allows one task to inform the other. Our results demonstrate that incorporating affective features leads to significant improvements in abuse detection performance across datasets.
Learning to Learn to Disambiguate: Meta-Learning for Few-Shot Word Sense Disambiguation
Apr 29, 2020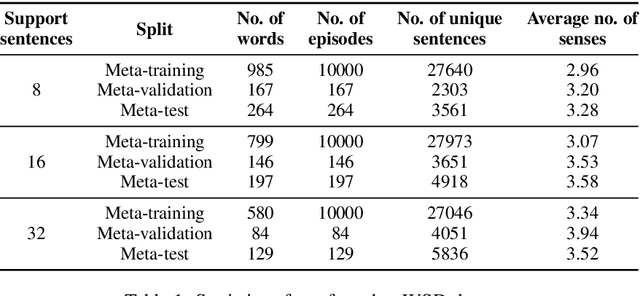
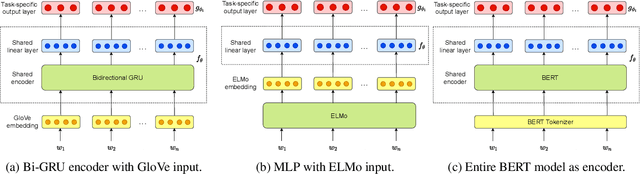
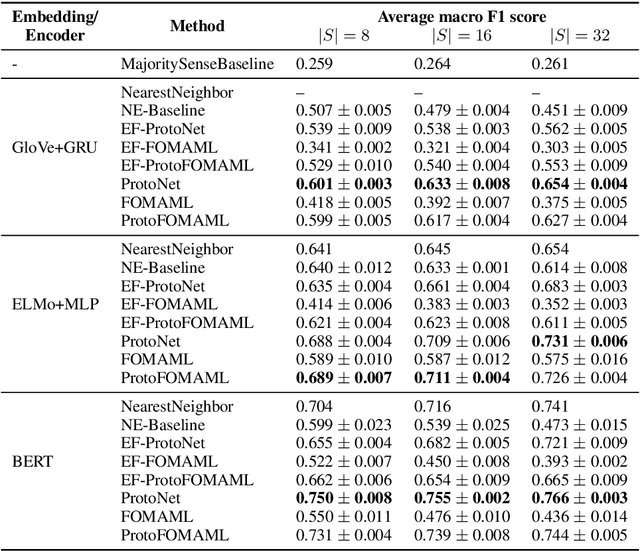
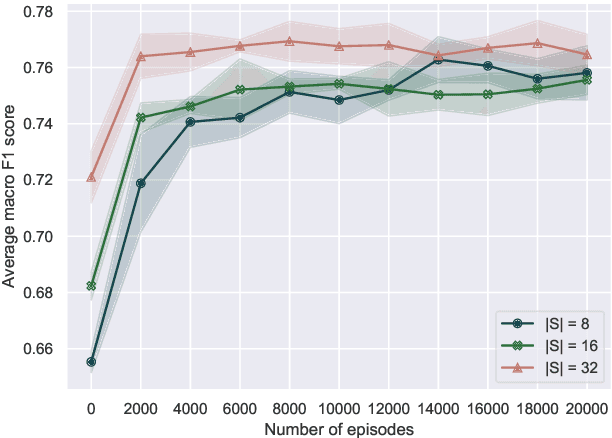
Deep learning methods typically rely on large amounts of annotated data and do not generalize well to few-shot learning problems where labeled data is scarce. In contrast to human intelligence, such approaches lack versatility and struggle to learn and adapt quickly to new tasks. Meta-learning addresses this problem by training on a large number of related tasks such that new tasks can be learned quickly using a small number of examples. We propose a meta-learning framework for few-shot word sense disambiguation (WSD), where the goal is to disambiguate unseen words from only a few labeled instances. Meta-learning approaches have so far been typically tested in an $N$-way, $K$-shot classification setting where each task has $N$ classes with $K$ examples per class. Owing to its nature, WSD deviates from this controlled setup and requires the models to handle a large number of highly unbalanced classes. We extend several popular meta-learning approaches to this scenario, and analyze their strengths and weaknesses in this new challenging setting.
Node Masking: Making Graph Neural Networks Generalize and Scale Better
Feb 20, 2020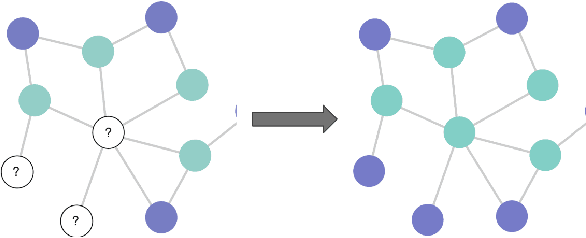
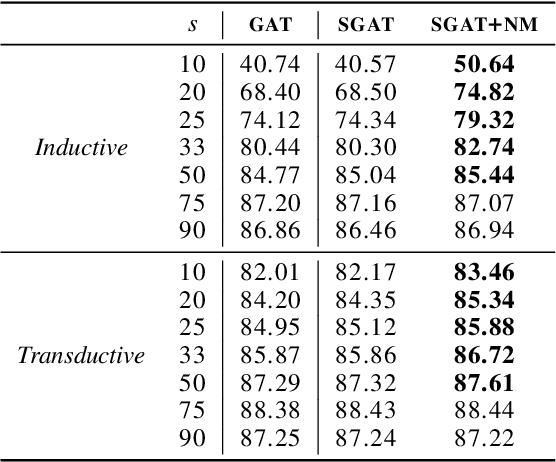
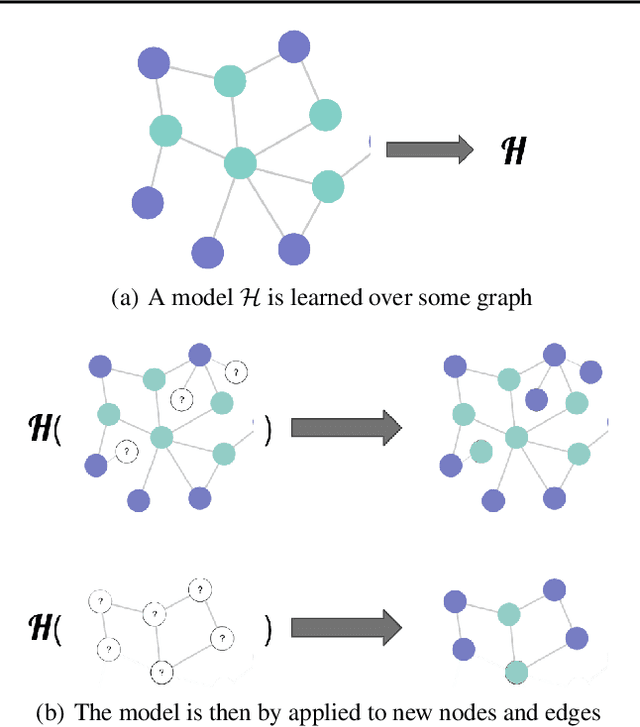
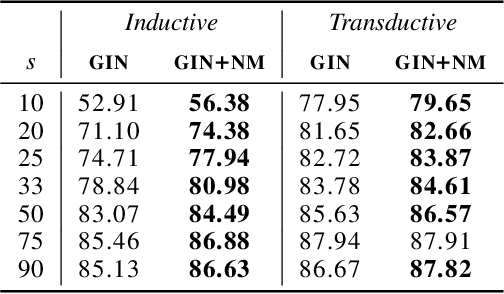
Graph Neural Networks (GNNs) have received a lot of interest in the recent times. From the early spectral architectures that could only operate on undirected graphs per a transductive learning paradigm to the current state of the art spatial ones that can apply inductively to arbitrary graphs, GNNs have seen significant contributions from the research community. In this paper, we discuss some theoretical tools to better visualize the operations performed by state of the art spatial GNNs. We analyze the inner workings of these architectures and introduce a simple concept, node masking, that allows them to generalize and scale better. To empirically validate the theory, we perform several experiments on three widely-used benchmark datasets for node classification in both transductive and inductive settings.
Tackling Online Abuse: A Survey of Automated Abuse Detection Methods
Aug 13, 2019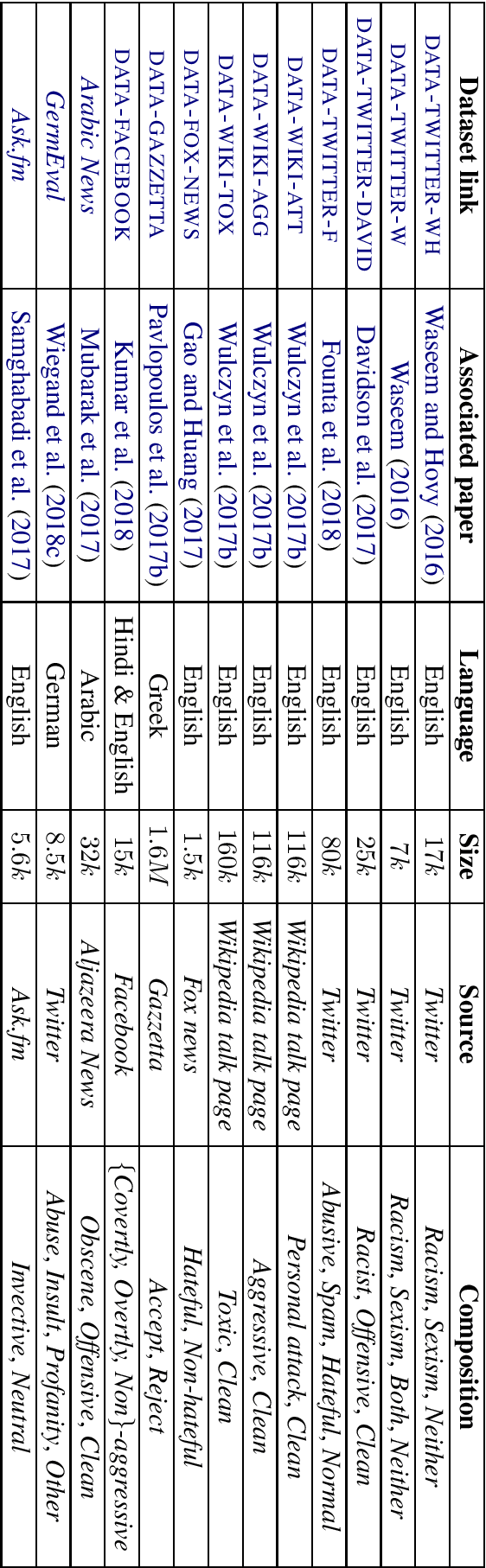
Abuse on the Internet represents an important societal problem of our time. Millions of Internet users face harassment, racism, personal attacks, and other types of abuse on online platforms. The psychological effects of such abuse on individuals can be profound and lasting. Consequently, over the past few years, there has been a substantial research effort towards automated abuse detection in the field of natural language processing (NLP). In this paper, we present a comprehensive survey of the methods that have been proposed to date, thus providing a platform for further development of this area. We describe the existing datasets and review the computational approaches to abuse detection, analyzing their strengths and limitations. We discuss the main trends that emerge, highlight the challenges that remain, outline possible solutions, and propose guidelines for ethics and explainability
Abusive Language Detection with Graph Convolutional Networks
Apr 05, 2019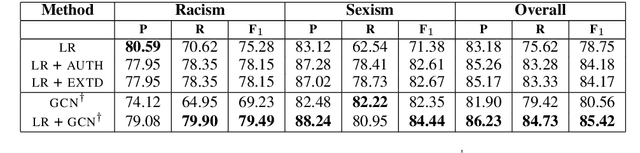


Abuse on the Internet represents a significant societal problem of our time. Previous research on automated abusive language detection in Twitter has shown that community-based profiling of users is a promising technique for this task. However, existing approaches only capture shallow properties of online communities by modeling follower-following relationships. In contrast, working with graph convolutional networks (GCNs), we present the first approach that captures not only the structure of online communities but also the linguistic behavior of the users within them. We show that such a heterogeneous graph-structured modeling of communities significantly advances the current state of the art in abusive language detection.
Author Profiling for Hate Speech Detection
Feb 14, 2019
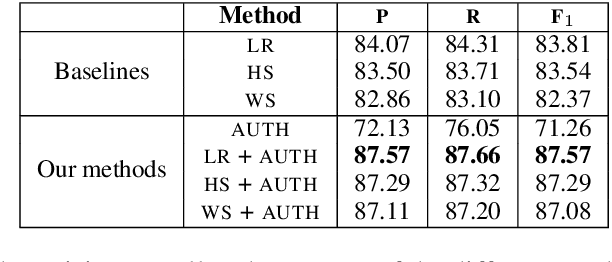
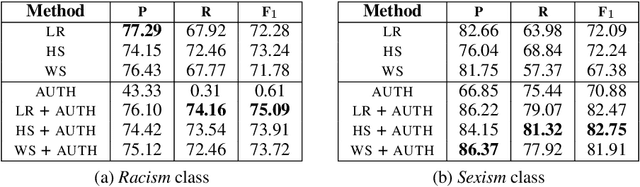

The rapid growth of social media in recent years has fed into some highly undesirable phenomena such as proliferation of abusive and offensive language on the Internet. Previous research suggests that such hateful content tends to come from users who share a set of common stereotypes and form communities around them. The current state-of-the-art approaches to hate speech detection are oblivious to user and community information and rely entirely on textual (i.e., lexical and semantic) cues. In this paper, we propose a novel approach to this problem that incorporates community-based profiling features of Twitter users. Experimenting with a dataset of 16k tweets, we show that our methods significantly outperform the current state of the art in hate speech detection. Further, we conduct a qualitative analysis of model characteristics. We release our code, pre-trained models and all the resources used in the public domain.
Neural Character-based Composition Models for Abuse Detection
Sep 02, 2018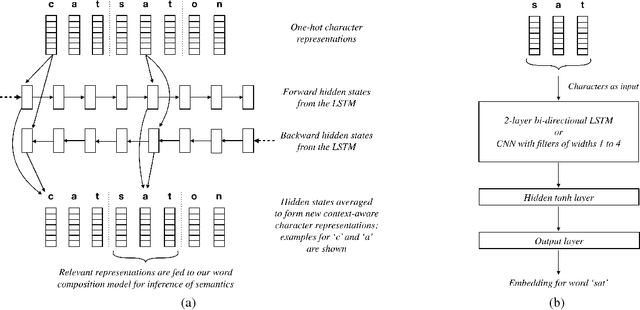
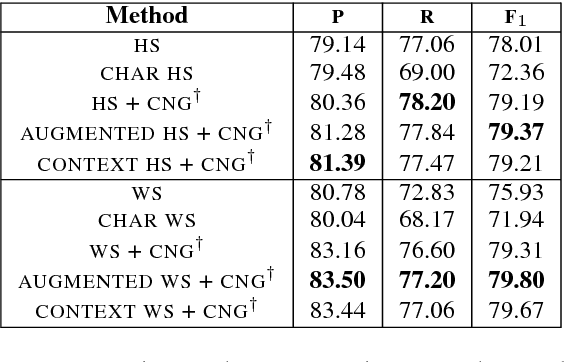
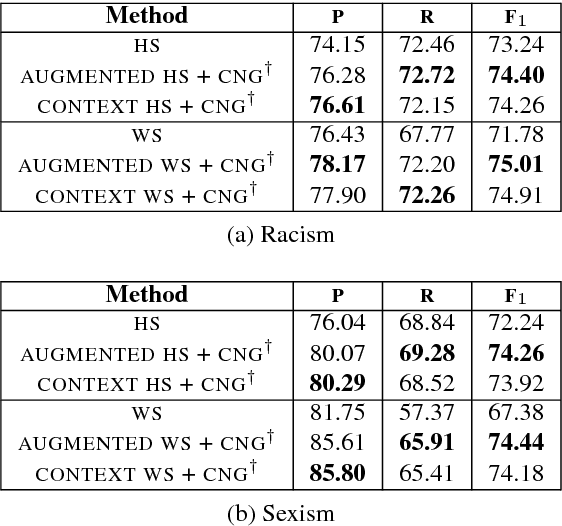
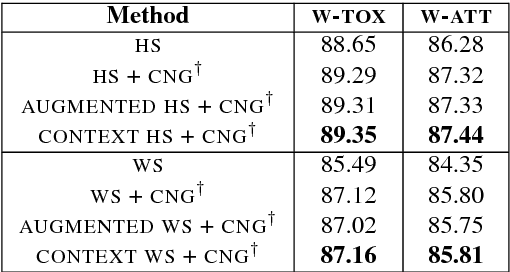
The advent of social media in recent years has fed into some highly undesirable phenomena such as proliferation of offensive language, hate speech, sexist remarks, etc. on the Internet. In light of this, there have been several efforts to automate the detection and moderation of such abusive content. However, deliberate obfuscation of words by users to evade detection poses a serious challenge to the effectiveness of these efforts. The current state of the art approaches to abusive language detection, based on recurrent neural networks, do not explicitly address this problem and resort to a generic OOV (out of vocabulary) embedding for unseen words. However, in using a single embedding for all unseen words we lose the ability to distinguish between obfuscated and non-obfuscated or rare words. In this paper, we address this problem by designing a model that can compose embeddings for unseen words. We experimentally demonstrate that our approach significantly advances the current state of the art in abuse detection on datasets from two different domains, namely Twitter and Wikipedia talk page.