 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Tiny Episodic Memories
Mar 20, 2019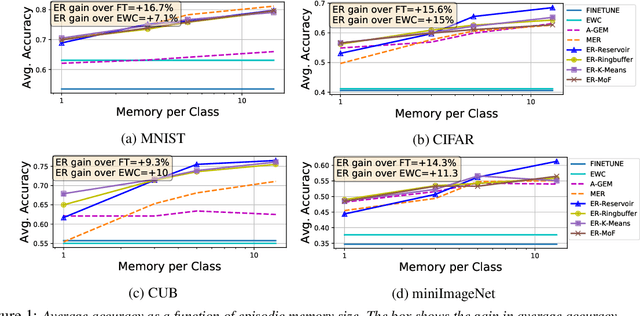
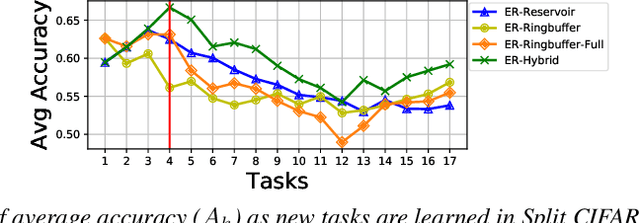

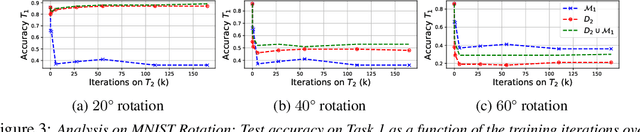
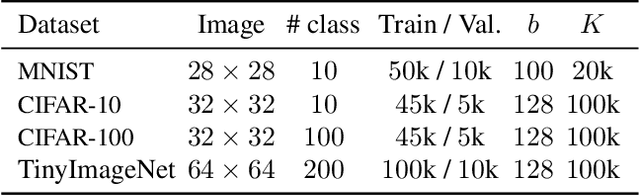
Learning with less supervision is a major challenge in artificial intelligence. One sensible approach to decrease the amount of supervision is to leverage prior experience and transfer knowledge from tasks seen in the past. However, a necessary condition for a successful transfer is the ability to remember how to perform previous tasks. The Continual Learning (CL) setting, whereby an agent learns from a stream of tasks without seeing any example twice, is an ideal framework to investigate how to accrue such knowledge. In this work, we consider supervised learning tasks and methods that leverage a very small episodic memory for continual learning. Through an extensive empirical analysis across four benchmark datasets adapted to CL, we observe that a very simple baseline, which jointly trains on both examples from the current task as well as examples stored in the memory, outperforms state-of-the-art CL approaches with and without episodic memory. Surprisingly, repeated learning over tiny episodic memories does not harm generalization on past tasks, as joint training on data from subsequent tasks acts like a data dependent regularizer. We discuss and evaluate different approaches to write into the memory. Most notably, reservoir sampling works remarkably well across the board, except when the memory size is extremely small. In this case, writing strategies that guarantee an equal representation of all classes work better. Overall, these methods should be considered as a strong baseline candidate when benchmarking new CL approaches
Visual Dialogue without Vision or Dialogue
Dec 16, 2018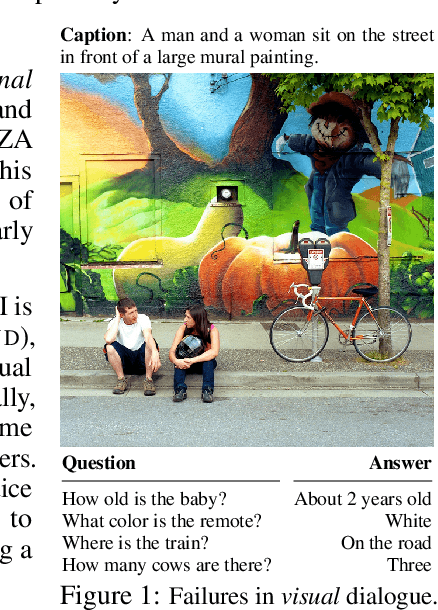
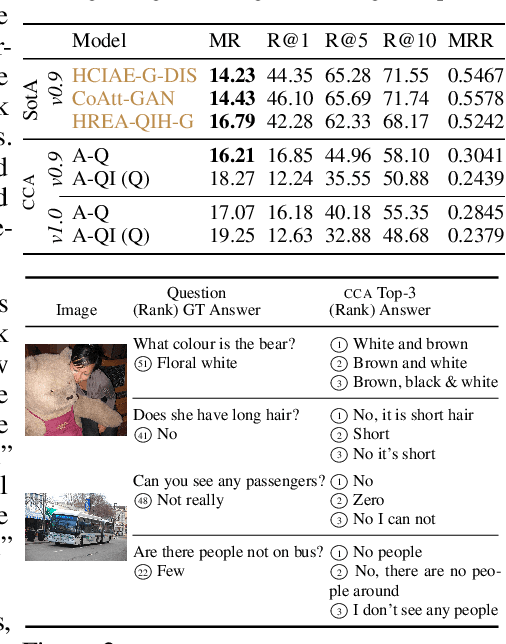

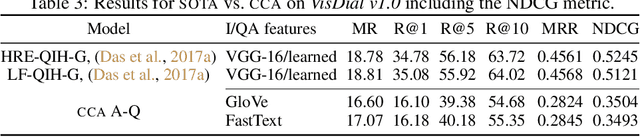
We characterise some of the quirks and shortcomings in the exploration of Visual Dialogue (VD) - a sequential question-answering task where the questions and corresponding answers are related through given visual stimuli. To do so, we develop an embarrassingly simple method based on Canonical Correlation Analysis (CCA) that, on the standard dataset, achieves near state-of-the-art performance for some standard metric. In direct contrast to current complex and over-parametrised architectures that are both compute and time intensive, our method ignores the visual stimuli, ignores the sequencing of dialogue, does not need gradients, uses off-the-shelf feature extractors, has at least an order of magnitude fewer parameters, and learns in practically no time. We argue that these results are indicative of issues in current approaches to Visual Dialogue relating particularly to implicit dataset biases, under-constrained task objectives, and over-constrained evaluation metrics, and consequently, discuss some avenues to ameliorate these issues.
Proximal Mean-field for Neural Network Quantization
Dec 11, 2018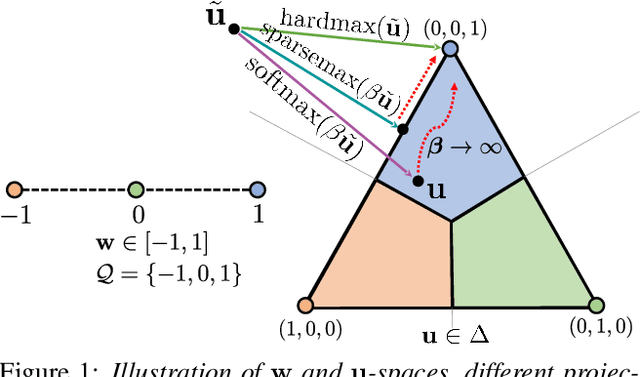
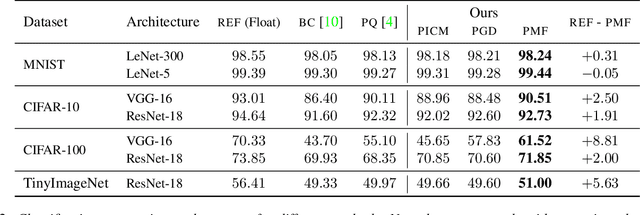
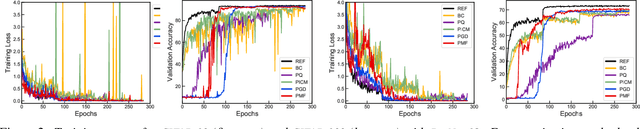
Compressing large neural networks by quantizing the parameters, while maintaining the performance is often highly desirable due to the reduced memory and time complexity. In this work, we formulate neural network quantization as a discrete labelling problem and design an efficient approximate algorithm based on the popular mean-field method. To this end, we devise a projected stochastic gradient descent algorithm and show that it is, in fact, equivalent to a proximal version of the mean-field method. Thus, we provide an MRF optimization perspective to neural network quantization, which would enable research on modelling higher-order interactions among the network parameters to design better quantization schemes. Our experiments on standard image classification datasets with convolutional and residual architectures evidence that our algorithm obtains fully-quantized networks with accuracies very close to the floating-point reference networks.
Weakly-Supervised Learning of Metric Aggregations for Deformable Image Registration
Sep 24, 2018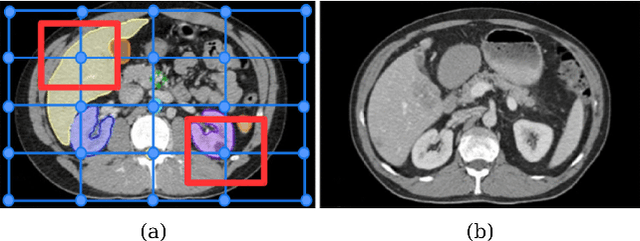
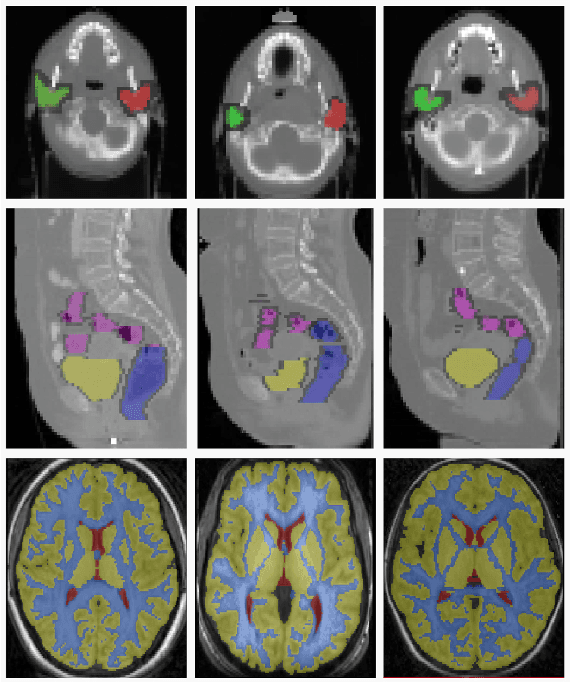
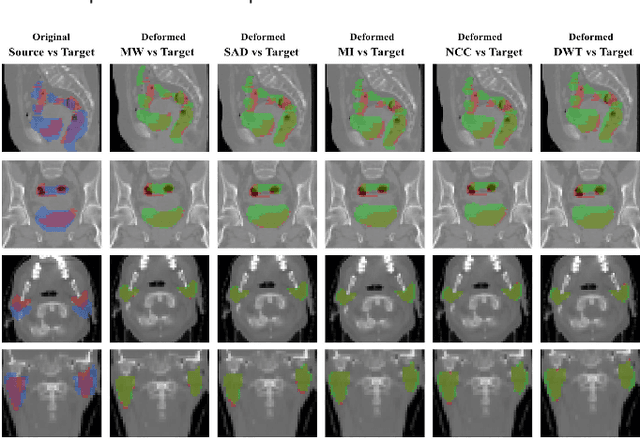
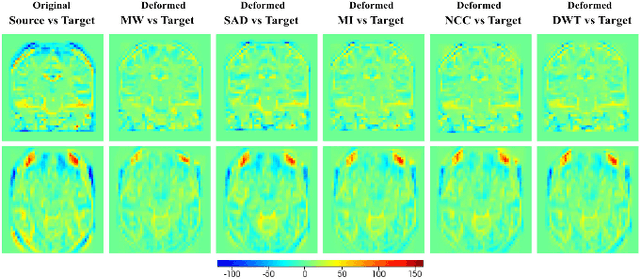
Deformable registration has been one of the pillars of biomedical image computing. Conventional approaches refer to the definition of a similarity criterion that, once endowed with a deformation model and a smoothness constraint, determines the optimal transformation to align two given images. The definition of this metric function is among the most critical aspects of the registration process. We argue that incorporating semantic information (in the form of anatomical segmentation maps) into the registration process will further improve the accuracy of the results. In this paper, we propose a novel weakly supervised approach to learn domain specific aggregations of conventional metrics using anatomical segmentations. This combination is learned using latent structured support vector machines (LSSVM). The learned matching criterion is integrated within a metric free optimization framework based on graphical models, resulting in a multi-metric algorithm endowed with a spatially varying similarity metric function conditioned on the anatomical structures. We provide extensive evaluation on three different datasets of CT and MRI images, showing that learned multi-metric registration outperforms single-metric approaches based on conventional similarity measures.
Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence
Aug 14, 2018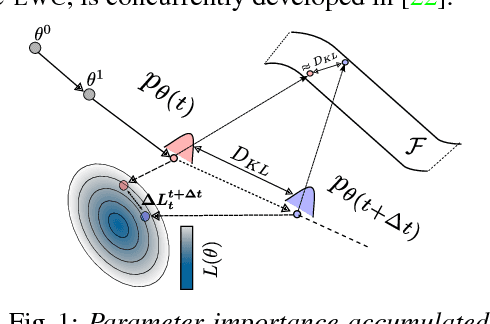
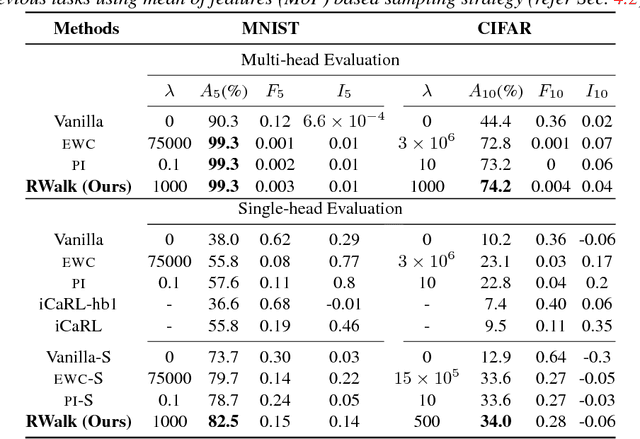
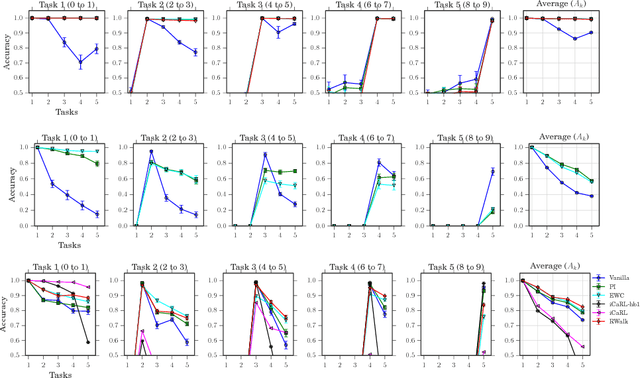
Incremental learning (IL) has received a lot of attention recently, however, the literature lacks a precise problem definition, proper evaluation settings, and metrics tailored specifically for the IL problem. One of the main objectives of this work is to fill these gaps so as to provide a common ground for better understanding of IL. The main challenge for an IL algorithm is to update the classifier whilst preserving existing knowledge. We observe that, in addition to forgetting, a known issue while preserving knowledge, IL also suffers from a problem we call intransigence, inability of a model to update its knowledge. We introduce two metrics to quantify forgetting and intransigence that allow us to understand, analyse, and gain better insights into the behaviour of IL algorithms. We present RWalk, a generalization of EWC++ (our efficient version of EWC [Kirkpatrick2016EWC]) and Path Integral [Zenke2017Continual] with a theoretically grounded KL-divergence based perspective. We provide a thorough analysis of various IL algorithms on MNIST and CIFAR-100 datasets. In these experiments, RWalk obtains superior results in terms of accuracy, and also provides a better trade-off between forgetting and intransigence.
Multi-Agent Diverse Generative Adversarial Networks
Jul 16, 2018
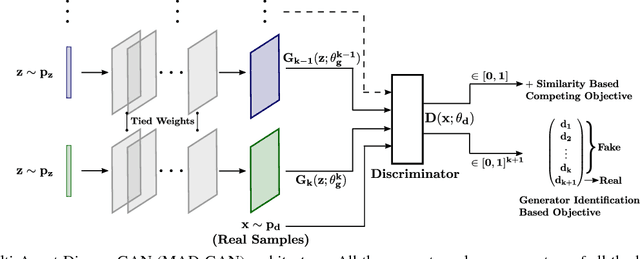

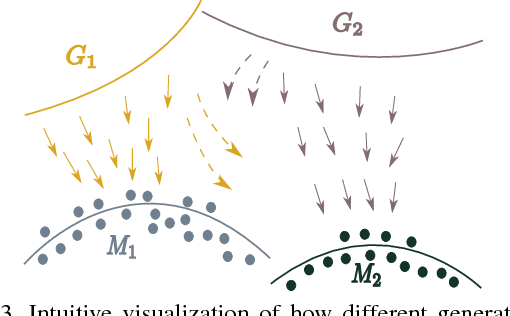
We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.
FlipDial: A Generative Model for Two-Way Visual Dialogue
Apr 03, 2018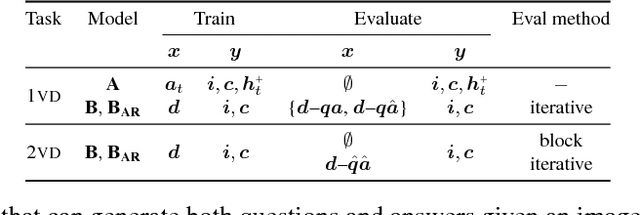
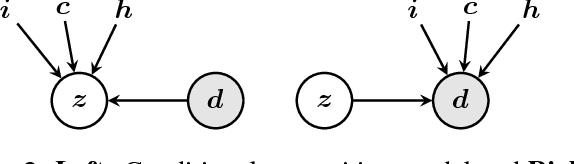
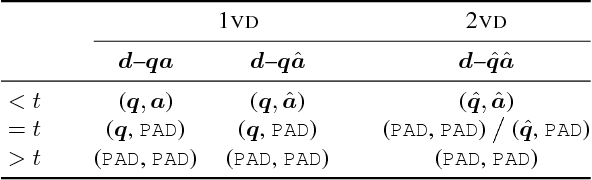
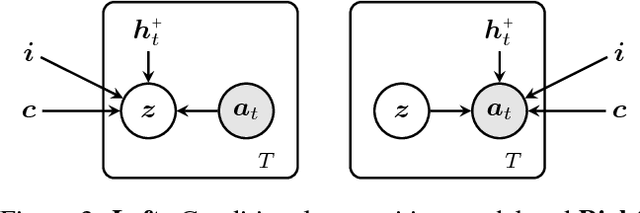
We present FlipDial, a generative model for visual dialogue that simultaneously plays the role of both participants in a visually-grounded dialogue. Given context in the form of an image and an associated caption summarising the contents of the image, FlipDial learns both to answer questions and put forward questions, capable of generating entire sequences of dialogue (question-answer pairs) which are diverse and relevant to the image. To do this, FlipDial relies on a simple but surprisingly powerful idea: it uses convolutional neural networks (CNNs) to encode entire dialogues directly, implicitly capturing dialogue context, and conditional VAEs to learn the generative model. FlipDial outperforms the state-of-the-art model in the sequential answering task (one-way visual dialogue) on the VisDial dataset by 5 points in Mean Rank using the generated answers. We are the first to extend this paradigm to full two-way visual dialogue, where our model is capable of generating both questions and answers in sequence based on a visual input, for which we propose a set of novel evaluation measures and metrics.
Discovering Class-Specific Pixels for Weakly-Supervised Semantic Segmentation
Jul 18, 2017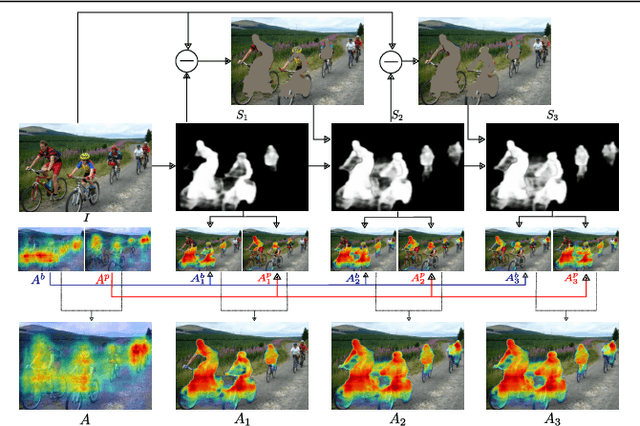
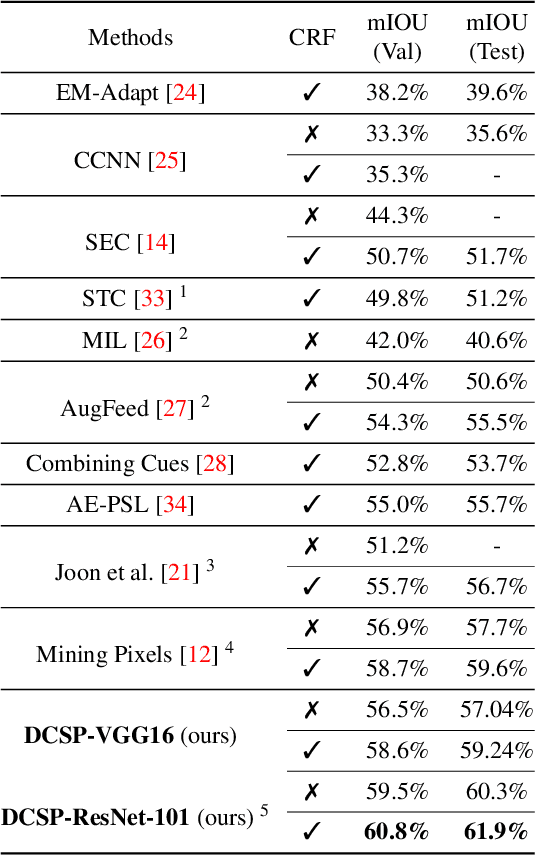
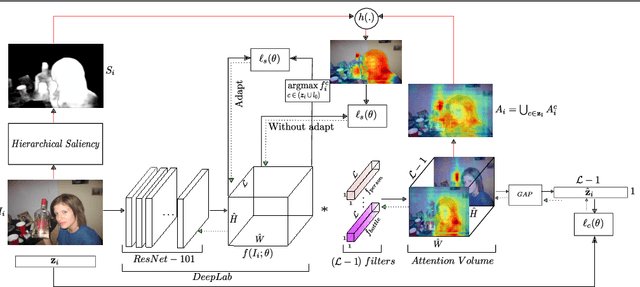

We propose an approach to discover class-specific pixels for the weakly-supervised semantic segmentation task. We show that properly combining saliency and attention maps allows us to obtain reliable cues capable of significantly boosting the performance. First, we propose a simple yet powerful hierarchical approach to discover the class-agnostic salient regions, obtained using a salient object detector, which otherwise would be ignored. Second, we use fully convolutional attention maps to reliably localize the class-specific regions in a given image. We combine these two cues to discover class-specific pixels which are then used as an approximate ground truth for training a CNN. While solving the weakly supervised semantic segmentation task, we ensure that the image-level classification task is also solved in order to enforce the CNN to assign at least one pixel to each object present in the image. Experimentally, on the PASCAL VOC12 val and test sets, we obtain the mIoU of 60.8% and 61.9%, achieving the performance gains of 5.1% and 5.2% compared to the published state-of-the-art results. The code is made publicly available.
Minding the Gaps for Block Frank-Wolfe Optimization of Structured SVMs
May 30, 2016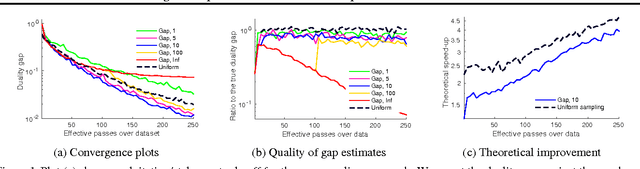
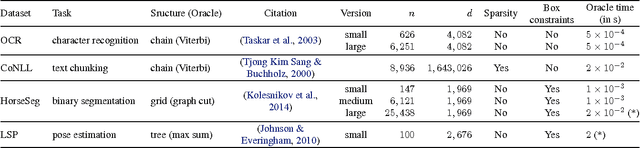
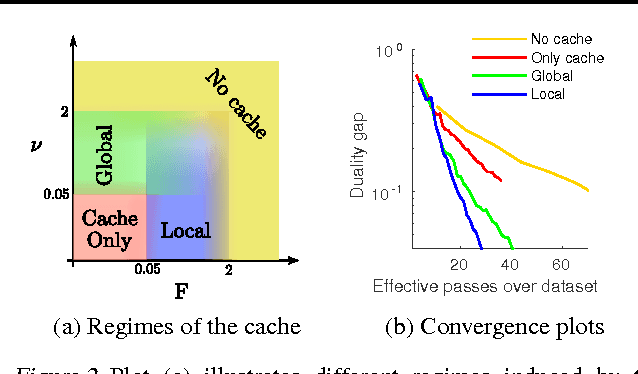
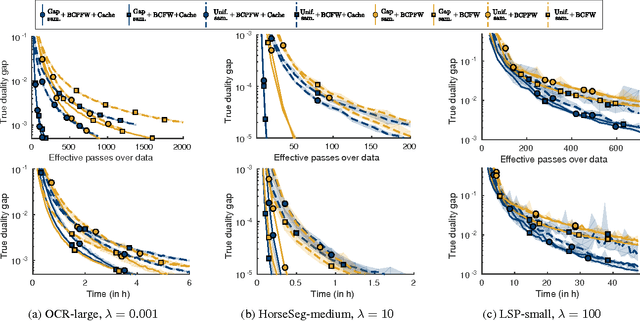
In this paper, we propose several improvements on the block-coordinate Frank-Wolfe (BCFW) algorithm from Lacoste-Julien et al. (2013) recently used to optimize the structured support vector machine (SSVM) objective in the context of structured prediction, though it has wider applications. The key intuition behind our improvements is that the estimates of block gaps maintained by BCFW reveal the block suboptimality that can be used as an adaptive criterion. First, we sample objects at each iteration of BCFW in an adaptive non-uniform way via gapbased sampling. Second, we incorporate pairwise and away-step variants of Frank-Wolfe into the block-coordinate setting. Third, we cache oracle calls with a cache-hit criterion based on the block gaps. Fourth, we provide the first method to compute an approximate regularization path for SSVM. Finally, we provide an exhaustive empirical evaluation of all our methods on four structured prediction datasets.
Parsimonious Labeling
Jul 05, 2015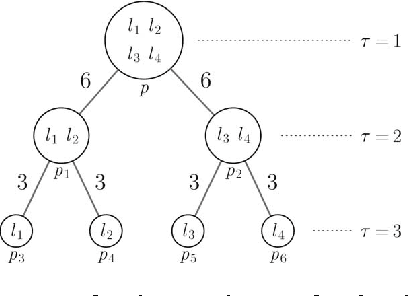
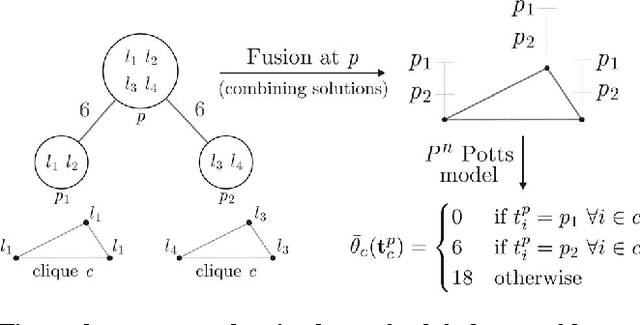
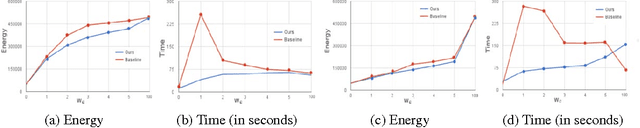

We propose a new family of discrete energy minimization problems, which we call parsimonious labeling. Specifically, our energy functional consists of unary potentials and high-order clique potentials. While the unary potentials are arbitrary, the clique potentials are proportional to the {\em diversity} of set of the unique labels assigned to the clique. Intuitively, our energy functional encourages the labeling to be parsimonious, that is, use as few labels as possible. This in turn allows us to capture useful cues for important computer vision applications such as stereo correspondence and image denoising. Furthermore, we propose an efficient graph-cuts based algorithm for the parsimonious labeling problem that provides strong theoretical guarantees on the quality of the solution. Our algorithm consists of three steps. First, we approximate a given diversity using a mixture of a novel hierarchical $P^n$ Potts model. Second, we use a divide-and-conquer approach for each mixture component, where each subproblem is solved using an effficient $\alpha$-expansion algorithm. This provides us with a small number of putative labelings, one for each mixture component. Third, we choose the best putative labeling in terms of the energy value. Using both sythetic and standard real datasets, we show that our algorithm significantly outperforms other graph-cuts based approaches.