 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Data Augmentation for Training Spiking Neural Networks
Mar 11, 2022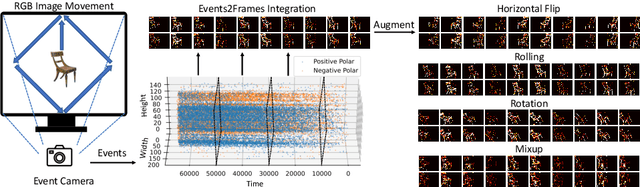
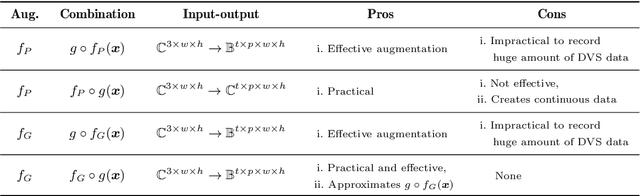
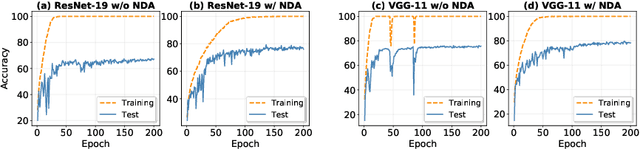

Developing neuromorphic intelligence on event-based datasets with spiking neural networks (SNNs) has recently attracted much research attention. However, the limited size of event-based datasets makes SNNs prone to overfitting and unstable convergence. This issue remains unexplored by previous academic works. In an effort to minimize this generalization gap, we propose neuromorphic data augmentation (NDA), a family of geometric augmentations specifically designed for event-based datasets with the goal of significantly stabilizing the SNN training and reducing the generalization gap between training and test performance. The proposed method is simple and compatible with existing SNN training pipelines. Using the proposed augmentation, for the first time, we demonstrate the feasibility of unsupervised contrastive learning for SNNs. We conduct comprehensive experiments on prevailing neuromorphic vision benchmarks and show that NDA yields substantial improvements over previous state-of-the-art results. For example, NDA-based SNN achieves accuracy gain on CIFAR10-DVS and N-Caltech 101 by 10.1% and 13.7%, respectively.
Adversarial Detection without Model Information
Feb 09, 2022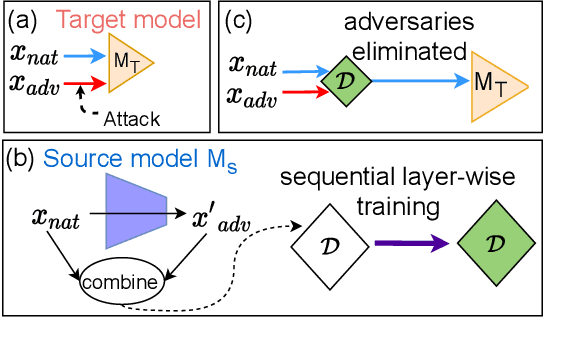

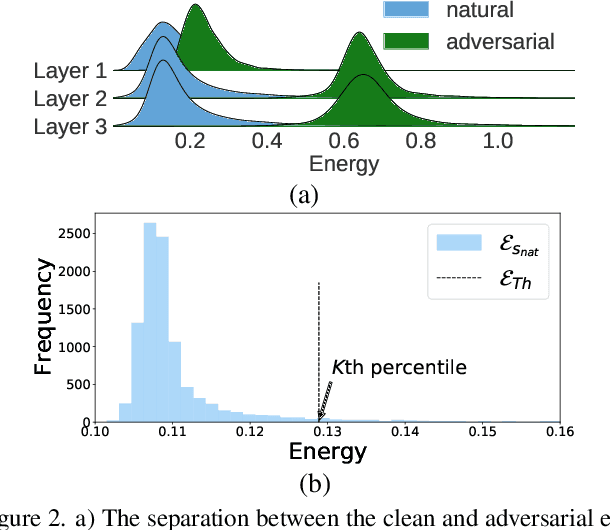

Most prior state-of-the-art adversarial detection works assume that the underlying vulnerable model is accessible, i,e., the model can be trained or its outputs are visible. However, this is not a practical assumption due to factors like model encryption, model information leakage and so on. In this work, we propose a model independent adversarial detection method using a simple energy function to distinguish between adversarial and natural inputs. We train a standalone detector independent of the underlying model, with sequential layer-wise training to increase the energy separation corresponding to natural and adversarial inputs. With this, we perform energy distribution-based adversarial detection. Our method achieves state-of-the-art detection performance (ROC-AUC > 0.9) across a wide range of gradient, score and decision-based adversarial attacks on CIFAR10, CIFAR100 and TinyImagenet datasets. Compared to prior approaches, our method requires ~10-100x less number of operations and parameters for adversarial detection. Further, we show that our detection method is transferable across different datasets and adversarial attacks. For reproducibility, we provide code in the supplementary material.
Rate Coding or Direct Coding: Which One is Better for Accurate, Robust, and Energy-efficient Spiking Neural Networks?
Jan 31, 2022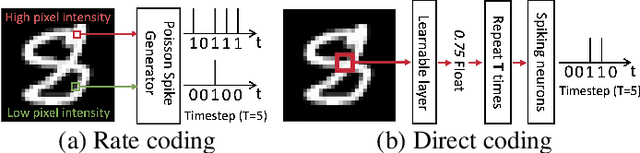

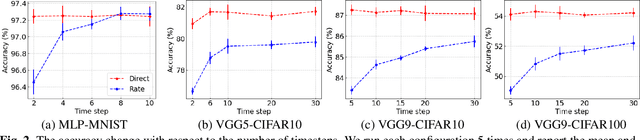
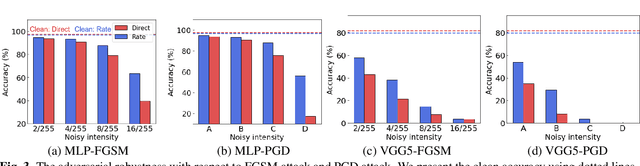
Recent Spiking Neural Networks (SNNs) works focus on an image classification task, therefore various coding techniques have been proposed to convert an image into temporal binary spikes. Among them, rate coding and direct coding are regarded as prospective candidates for building a practical SNN system as they show state-of-the-art performance on large-scale datasets. Despite their usage, there is little attention to comparing these two coding schemes in a fair manner. In this paper, we conduct a comprehensive analysis of the two codings from three perspectives: accuracy, adversarial robustness, and energy-efficiency. First, we compare the performance of two coding techniques with various architectures and datasets. Then, we measure the robustness of the coding techniques on two adversarial attack methods. Finally, we compare the energy-efficiency of two coding schemes on a digital hardware platform. Our results show that direct coding can achieve better accuracy especially for a small number of timesteps. In contrast, rate coding shows better robustness to adversarial attacks owing to the non-differentiable spike generation process. Rate coding also yields higher energy-efficiency than direct coding which requires multi-bit precision for the first layer. Our study explores the characteristics of two codings, which is an important design consideration for building SNNs. The code is made available at https://github.com/Intelligent-Computing-Lab-Yale/Rate-vs-Direct.
Neural Architecture Search for Spiking Neural Networks
Jan 23, 2022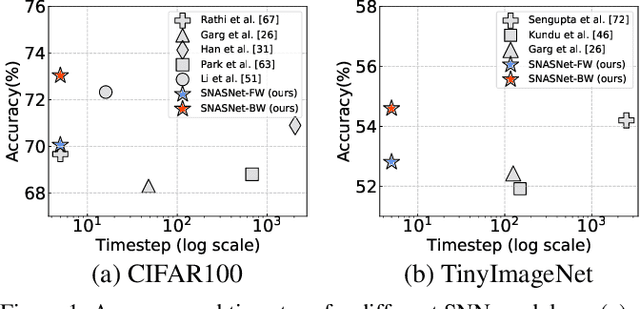
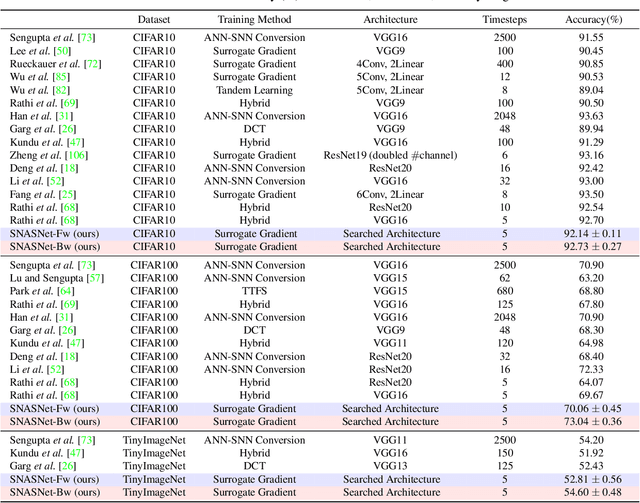
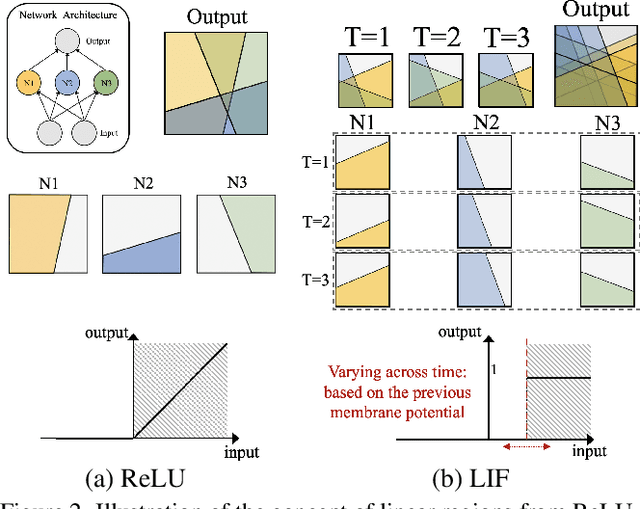
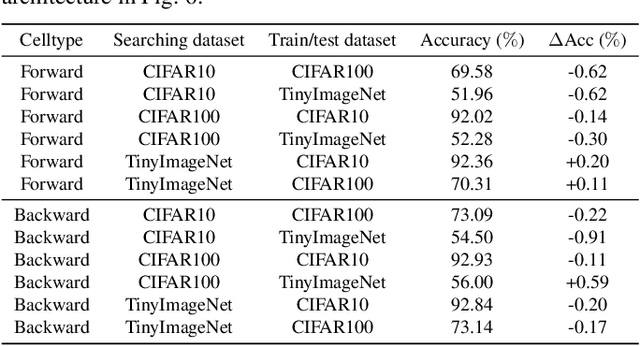
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. However, most prior SNN methods use ANN-like architectures (e.g., VGG-Net or ResNet), which could provide sub-optimal performance for temporal sequence processing of binary information in SNNs. To address this, in this paper, we introduce a novel Neural Architecture Search (NAS) approach for finding better SNN architectures. Inspired by recent NAS approaches that find the optimal architecture from activation patterns at initialization, we select the architecture that can represent diverse spike activation patterns across different data samples without training. Furthermore, to leverage the temporal correlation among the spikes, we search for feed forward connections as well as backward connections (i.e., temporal feedback connections) between layers. Interestingly, SNASNet found by our search algorithm achieves higher performance with backward connections, demonstrating the importance of designing SNN architecture for suitably using temporal information. We conduct extensive experiments on three image recognition benchmarks where we show that SNASNet achieves state-of-the-art performance with significantly lower timesteps (5 timesteps).
Examining and Mitigating the Impact of Crossbar Non-idealities for Accurate Implementation of Sparse Deep Neural Networks
Jan 13, 2022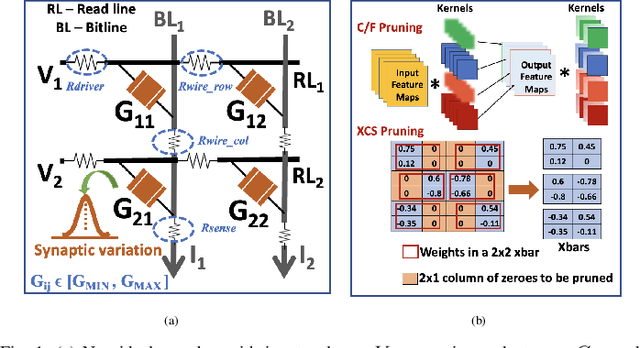
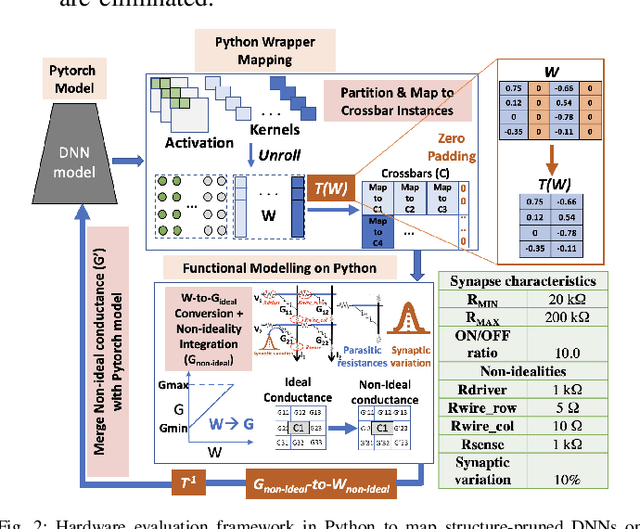
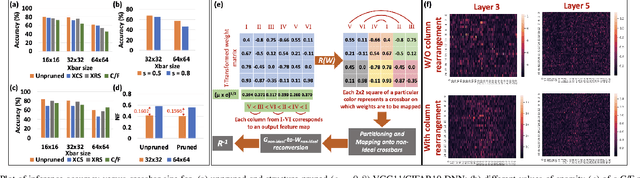

Recently several structured pruning techniques have been introduced for energy-efficient implementation of Deep Neural Networks (DNNs) with lesser number of crossbars. Although, these techniques have claimed to preserve the accuracy of the sparse DNNs on crossbars, none have studied the impact of the inexorable crossbar non-idealities on the actual performance of the pruned networks. To this end, we perform a comprehensive study to show how highly sparse DNNs, that result in significant crossbar-compression-rate, can lead to severe accuracy losses compared to unpruned DNNs mapped onto non-ideal crossbars. We perform experiments with multiple structured-pruning approaches (such as, C/F pruning, XCS and XRS) on VGG11 and VGG16 DNNs with benchmark datasets (CIFAR10 and CIFAR100). We propose two mitigation approaches - Crossbar column rearrangement and Weight-Constrained-Training (WCT) - that can be integrated with the crossbar-mapping of the sparse DNNs to minimize accuracy losses incurred by the pruned models. These help in mitigating non-idealities by increasing the proportion of low conductance synapses on crossbars, thereby improving their computational accuracies.
* Accepted in Design, Automation and Test in Europe (DATE) Conference, 2022
Gradient-based Bit Encoding Optimization for Noise-Robust Binary Memristive Crossbar
Jan 05, 2022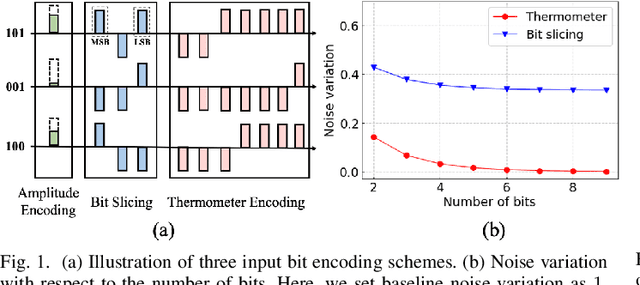
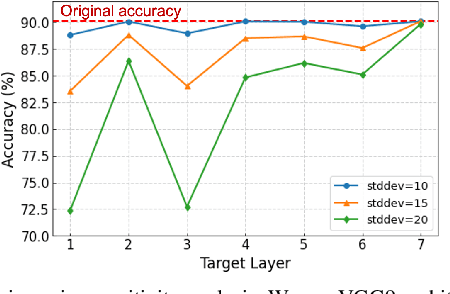
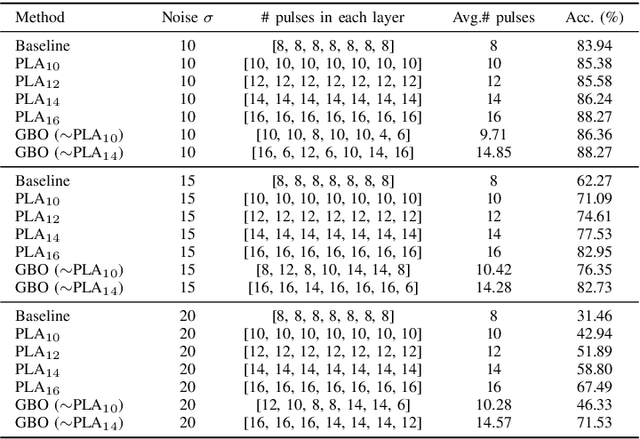
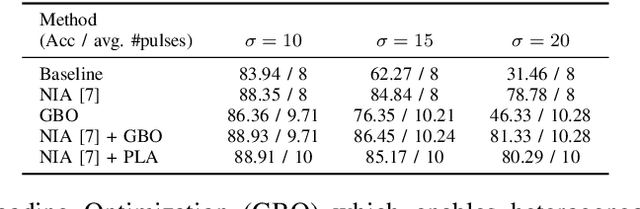
Binary memristive crossbars have gained huge attention as an energy-efficient deep learning hardware accelerator. Nonetheless, they suffer from various noises due to the analog nature of the crossbars. To overcome such limitations, most previous works train weight parameters with noise data obtained from a crossbar. These methods are, however, ineffective because it is difficult to collect noise data in large-volume manufacturing environment where each crossbar has a large device/circuit level variation. Moreover, we argue that there is still room for improvement even though these methods somewhat improve accuracy. This paper explores a new perspective on mitigating crossbar noise in a more generalized way by manipulating input binary bit encoding rather than training the weight of networks with respect to noise data. We first mathematically show that the noise decreases as the number of binary bit encoding pulses increases when representing the same amount of information. In addition, we propose Gradient-based Bit Encoding Optimization (GBO) which optimizes a different number of pulses at each layer, based on our in-depth analysis that each layer has a different level of noise sensitivity. The proposed heterogeneous layer-wise bit encoding scheme achieves high noise robustness with low computational cost. Our experimental results on public benchmark datasets show that GBO improves the classification accuracy by ~5-40% in severe noise scenarios.
Beyond Classification: Directly Training Spiking Neural Networks for Semantic Segmentation
Oct 14, 2021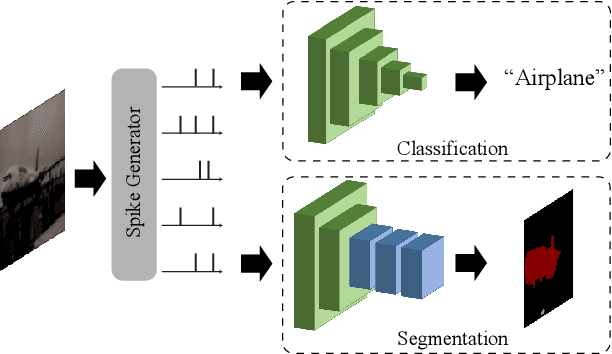
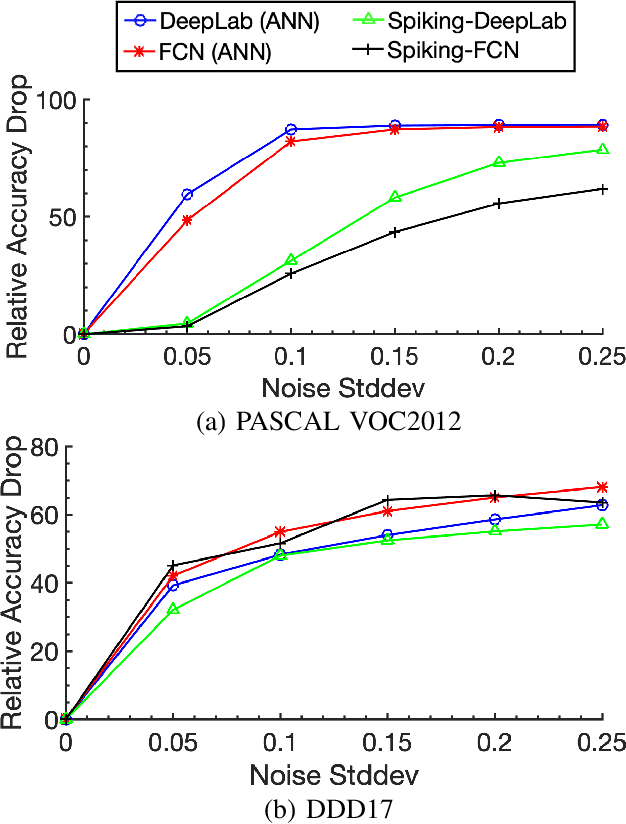
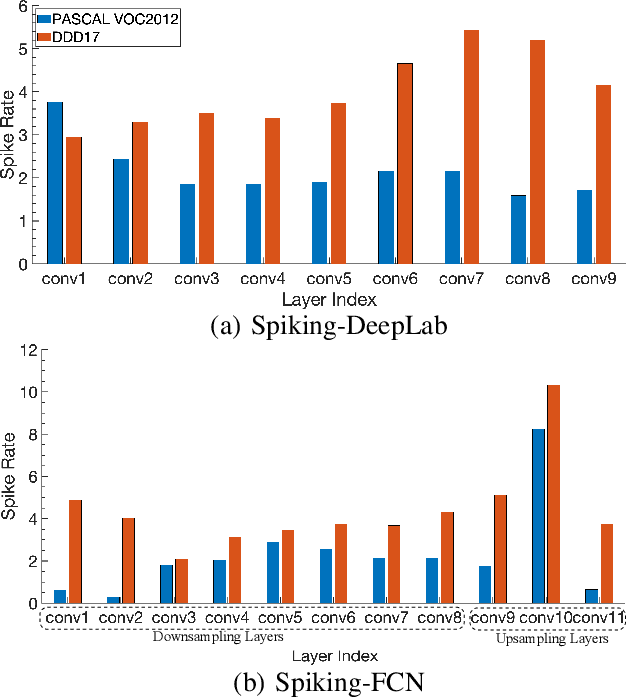
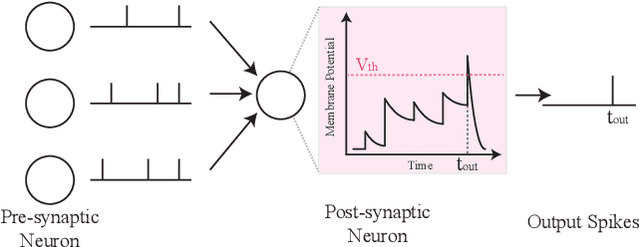
Spiking Neural Networks (SNNs) have recently emerged as the low-power alternative to Artificial Neural Networks (ANNs) because of their sparse, asynchronous, and binary event-driven processing. Due to their energy efficiency, SNNs have a high possibility of being deployed for real-world, resource-constrained systems such as autonomous vehicles and drones. However, owing to their non-differentiable and complex neuronal dynamics, most previous SNN optimization methods have been limited to image recognition. In this paper, we explore the SNN applications beyond classification and present semantic segmentation networks configured with spiking neurons. Specifically, we first investigate two representative SNN optimization techniques for recognition tasks (i.e., ANN-SNN conversion and surrogate gradient learning) on semantic segmentation datasets. We observe that, when converted from ANNs, SNNs suffer from high latency and low performance due to the spatial variance of features. Therefore, we directly train networks with surrogate gradient learning, resulting in lower latency and higher performance than ANN-SNN conversion. Moreover, we redesign two fundamental ANN segmentation architectures (i.e., Fully Convolutional Networks and DeepLab) for the SNN domain. We conduct experiments on two public semantic segmentation benchmarks including the PASCAL VOC2012 dataset and the DDD17 event-based dataset. In addition to showing the feasibility of SNNs for semantic segmentation, we show that SNNs can be more robust and energy-efficient compared to their ANN counterparts in this domain.
RAPID-RL: A Reconfigurable Architecture with Preemptive-Exits for Efficient Deep-Reinforcement Learning
Sep 16, 2021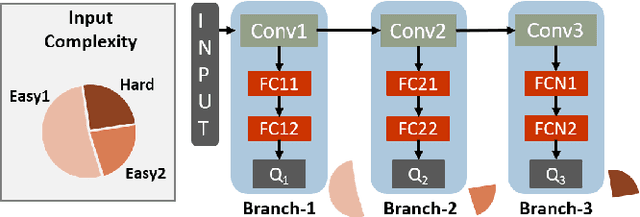
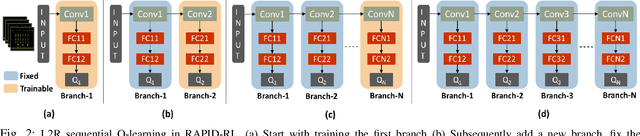
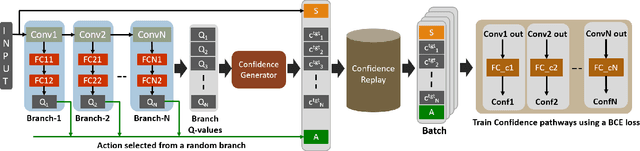
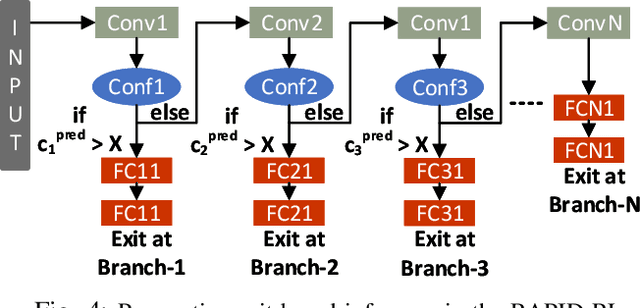
Present-day Deep Reinforcement Learning (RL) systems show great promise towards building intelligent agents surpassing human-level performance. However, the computational complexity associated with the underlying deep neural networks (DNNs) leads to power-hungry implementations. This makes deep RL systems unsuitable for deployment on resource-constrained edge devices. To address this challenge, we propose a reconfigurable architecture with preemptive exits for efficient deep RL (RAPID-RL). RAPID-RL enables conditional activation of DNN layers based on the difficulty level of inputs. This allows to dynamically adjust the compute effort during inference while maintaining competitive performance. We achieve this by augmenting a deep Q-network (DQN) with side-branches capable of generating intermediate predictions along with an associated confidence score. We also propose a novel training methodology for learning the actions and branch confidence scores in a dynamic RL setting. Our experiments evaluate the proposed framework for Atari 2600 gaming tasks and a realistic Drone navigation task on an open-source drone simulator (PEDRA). We show that RAPID-RL incurs 0.34x (0.25x) number of operations (OPS) while maintaining performance above 0.88x (0.91x) on Atari (Drone navigation) tasks, compared to a baseline-DQN without any side-branches. The reduction in OPS leads to fast and efficient inference, proving to be highly beneficial for the resource-constrained edge where making quick decisions with minimal compute is essential.
Federated Learning with Spiking Neural Networks
Jun 11, 2021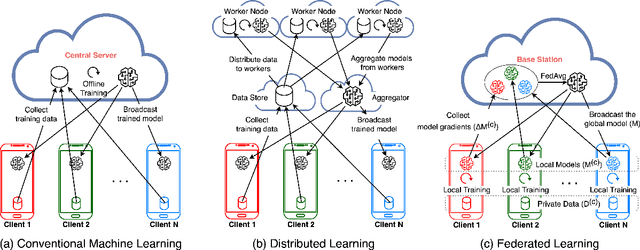
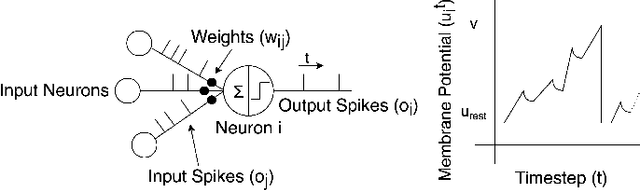

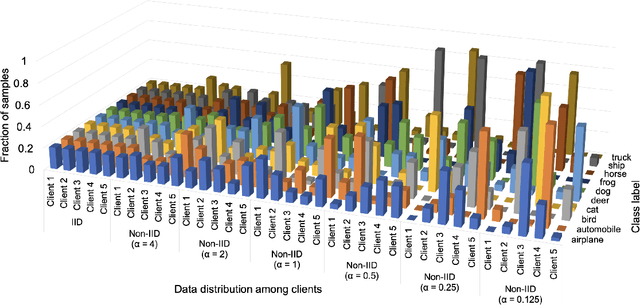
As neural networks get widespread adoption in resource-constrained embedded devices, there is a growing need for low-power neural systems. Spiking Neural Networks (SNNs)are emerging to be an energy-efficient alternative to the traditional Artificial Neural Networks (ANNs) which are known to be computationally intensive. From an application perspective, as federated learning involves multiple energy-constrained devices, there is a huge scope to leverage energy efficiency provided by SNNs. Despite its importance, there has been little attention on training SNNs on a large-scale distributed system like federated learning. In this paper, we bring SNNs to a more realistic federated learning scenario. Specifically, we propose a federated learning framework for decentralized and privacy-preserving training of SNNs. To validate the proposed federated learning framework, we experimentally evaluate the advantages of SNNs on various aspects of federated learning with CIFAR10 and CIFAR100 benchmarks. We observe that SNNs outperform ANNs in terms of overall accuracy by over 15% when the data is distributed across a large number of clients in the federation while providing up to5.3x energy efficiency. In addition to efficiency, we also analyze the sensitivity of the proposed federated SNN framework to data distribution among the clients, stragglers, and gradient noise and perform a comprehensive comparison with ANNs.
Efficiency-driven Hardware Optimization for Adversarially Robust Neural Networks
May 09, 2021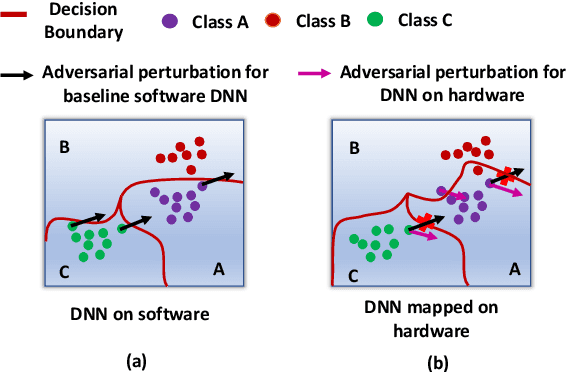
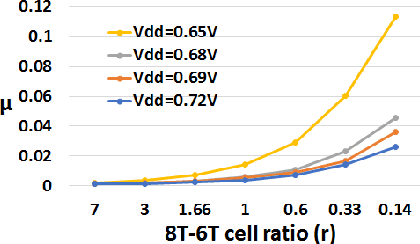
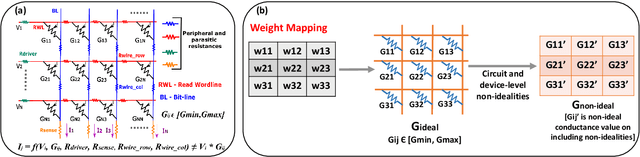
With a growing need to enable intelligence in embedded devices in the Internet of Things (IoT) era, secure hardware implementation of Deep Neural Networks (DNNs) has become imperative. We will focus on how to address adversarial robustness for DNNs through efficiency-driven hardware optimizations. Since memory (specifically, dot-product operations) is a key energy-spending component for DNNs, hardware approaches in the past have focused on optimizing the memory. One such approach is approximate digital CMOS memories with hybrid 6T-8T SRAM cells that enable supply voltage (Vdd) scaling yielding low-power operation, without significantly affecting the performance due to read/write failures incurred in the 6T cells. In this paper, we show how the bit-errors in the 6T cells of hybrid 6T-8T memories minimize the adversarial perturbations in a DNN. Essentially, we find that for different configurations of 8T-6T ratios and scaledVdd operation, noise incurred in the hybrid memory architectures is bound within specific limits. This hardware noise can potentially interfere in the creation of adversarial attacks in DNNs yielding robustness. Another memory optimization approach involves using analog memristive crossbars that perform Matrix-Vector-Multiplications (MVMs) efficiently with low energy and area requirements. However, crossbars generally suffer from intrinsic non-idealities that cause errors in performing MVMs, leading to degradation in the accuracy of the DNNs. We will show how the intrinsic hardware variations manifested through crossbar non-idealities yield adversarial robustness to the mapped DNNs without any additional optimization.
* 6 pages, 8 figures, 3 tables; Accepted in DATE 2021 conference. arXiv admin note: text overlap with arXiv:2008.11298